

このドキュメントはAIによって翻訳されました。不正確な情報については、英語版をご参照ください
インポート Pro
操作:レコードのインポート ProStandard Edition+概要
インポート Pro プラグインは、通常のインポート機能に加えて、さらに強化された機能を提供します。
インストール
このプラグインは非同期タスク管理プラグインに依存しています。使用する前に、非同期タスク管理プラグインを有効にする必要があります。
機能強化
- 非同期インポート操作に対応しており、独立したスレッドで実行されるため、大量のデータをインポートできます。
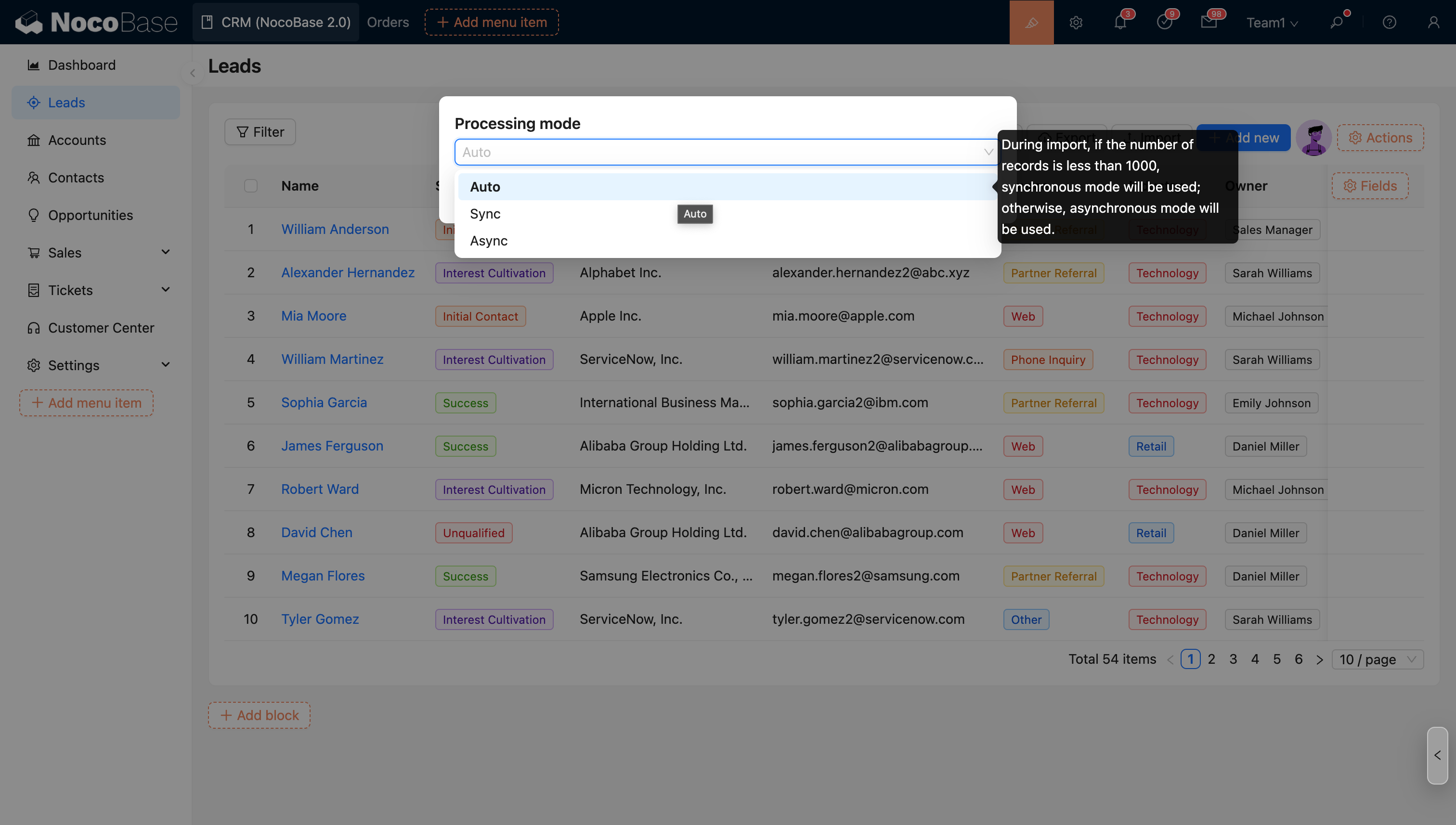
- 高度なインポートオプションに対応しています。
利用ガイド
非同期インポート
インポートを実行すると、その処理はユーザーによる手動設定なしに、独立したバックグラウンドスレッドで実行されます。ユーザーインターフェースでは、インポート操作を開始した後、右上に現在実行中のインポートタスクが表示され、リアルタイムでタスクの進捗が確認できます。
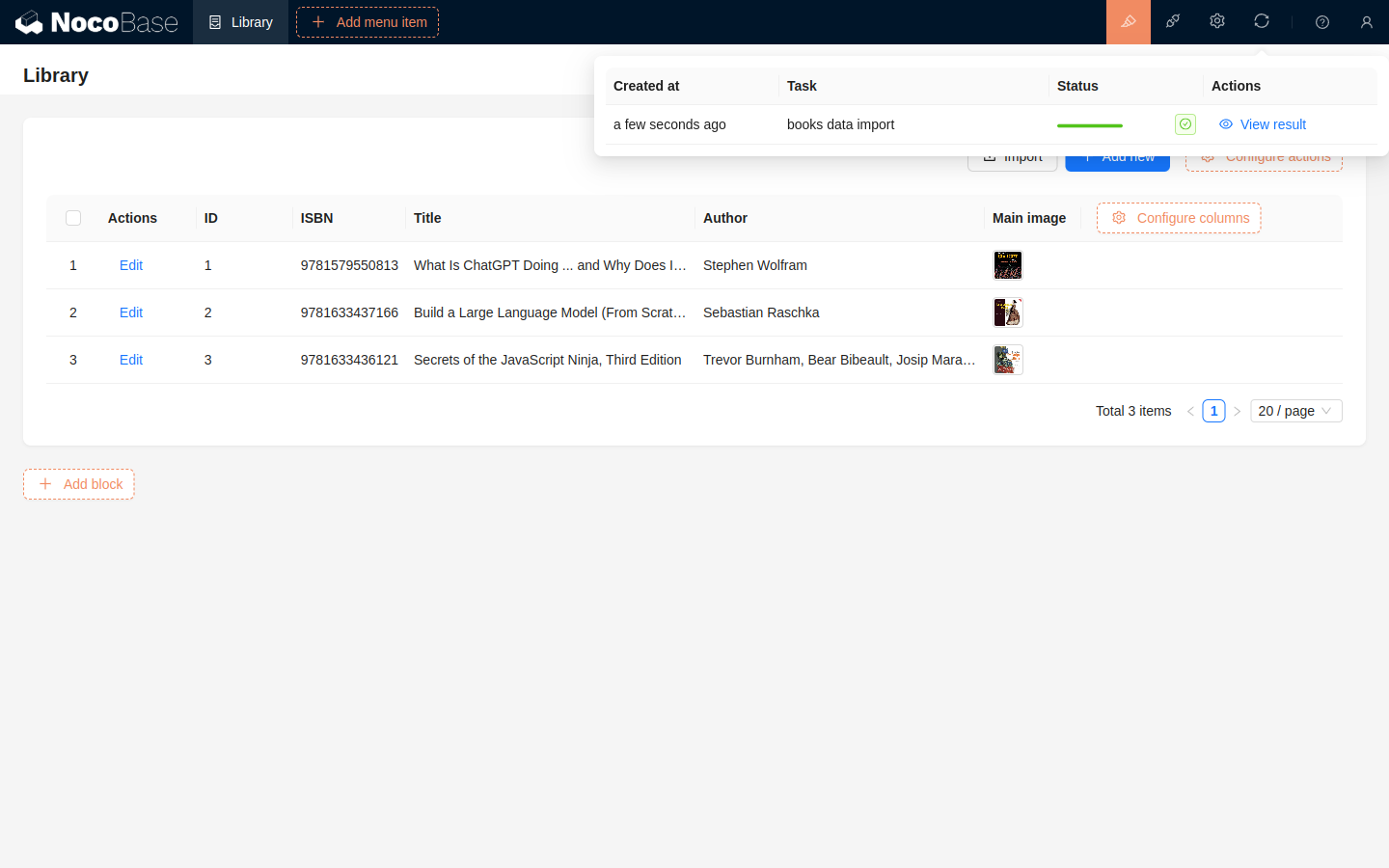
インポートが完了した後、インポートタスクから結果を確認できます。
パフォーマンスについて
大規模なデータインポートのパフォーマンスを評価するため、さまざまなシナリオ、フィールドタイプ、トリガー設定で比較テストを実施しました(サーバーやデータベースの構成によって結果は異なる場合がありますので、あくまで参考としてください)。
| データ量 | フィールドタイプ | インポート設定 | 処理時間 |
|---|---|---|---|
| 100万件 | 文字列、数値、日付、メールアドレス、長文テキスト | • ワークフローをトリガー:なし • 重複識別子:なし | 約1分 |
| 50万件 | 文字列、数値、日付、メールアドレス、長文テキスト、多対多 | • ワークフローをトリガー:なし • 重複識別子:なし | 約16分 |
| 50万件 | 文字列、数値、日付、メールアドレス、長文テキスト、多対多、多対一 | • ワークフローをトリガー:なし • 重複識別子:なし | 約22分 |
| 50万件 | 文字列、数値、日付、メールアドレス、長文テキスト、多対多、多対一 | • ワークフローをトリガー:非同期トリガー通知 • 重複識別子:なし | 約22分 |
| 50万件 | 文字列、数値、日付、メールアドレス、長文テキスト、多対多、多対一 | • ワークフローをトリガー:非同期トリガー通知 • 重複識別子:重複を更新、5万件の重複データあり | 約3時間 |
上記のパフォーマンス測定結果と既存の設計に基づき、影響要因について以下の説明と提案があります。
-
重複レコードの処理メカニズム:重複レコードを更新または重複レコードのみを更新オプションを選択すると、システムはレコードを1件ずつ検索および更新するため、インポート効率が著しく低下します。Excelファイルに不要な重複データが含まれている場合、インポート速度にさらに大きな影響を与えるため、インポート前にExcelファイル内の不要な重複データをクリーンアップ(例:専門の重複排除ツールを使用)してからシステムにインポートすることをお勧めします。これにより、無駄な時間を省くことができます。
-
リレーションフィールドの処理効率:システムがリレーションフィールドを処理する際、関連付けを1件ずつ検索する実装方式を採用しているため、大量データシナリオではパフォーマンスのボトルネックとなる可能性があります。シンプルなリレーション構造(例:2つのコレクション間の一対多関連)の場合、段階的なインポート戦略をお勧めします。まずメインコレクションの基本データをインポートし、完了後にコレクション間のリレーションを確立します。ビジネス要件によりリレーションデータを同時にインポートする必要がある場合は、上記の表のパフォーマンス測定結果を参考に、インポート時間を適切に計画してください。
-
ワークフローのトリガーメカニズム:大規模なデータインポートシナリオでワークフローのトリガーを有効にすることは推奨されません。主な理由は以下の2点です。
- インポートタスクのステータスが100%と表示されても、すぐに終了するわけではありません。システムはワークフロー実行計画の作成に追加の時間を必要とします。この段階では、システムはインポートされた各レコードに対応するワークフロー実行計画を生成し、インポートスレッドを占有しますが、すでにインポートされたデータの使用には影響しません。
- インポートタスクが完全に完了した後、大量のワークフローが同時に実行されることでシステムリソースが逼迫し、システム全体の応答速度やユーザーエクスペリエンスに影響を与える可能性があります。
上記3つの影響要因については、今後さらなる最適化を検討していきます。
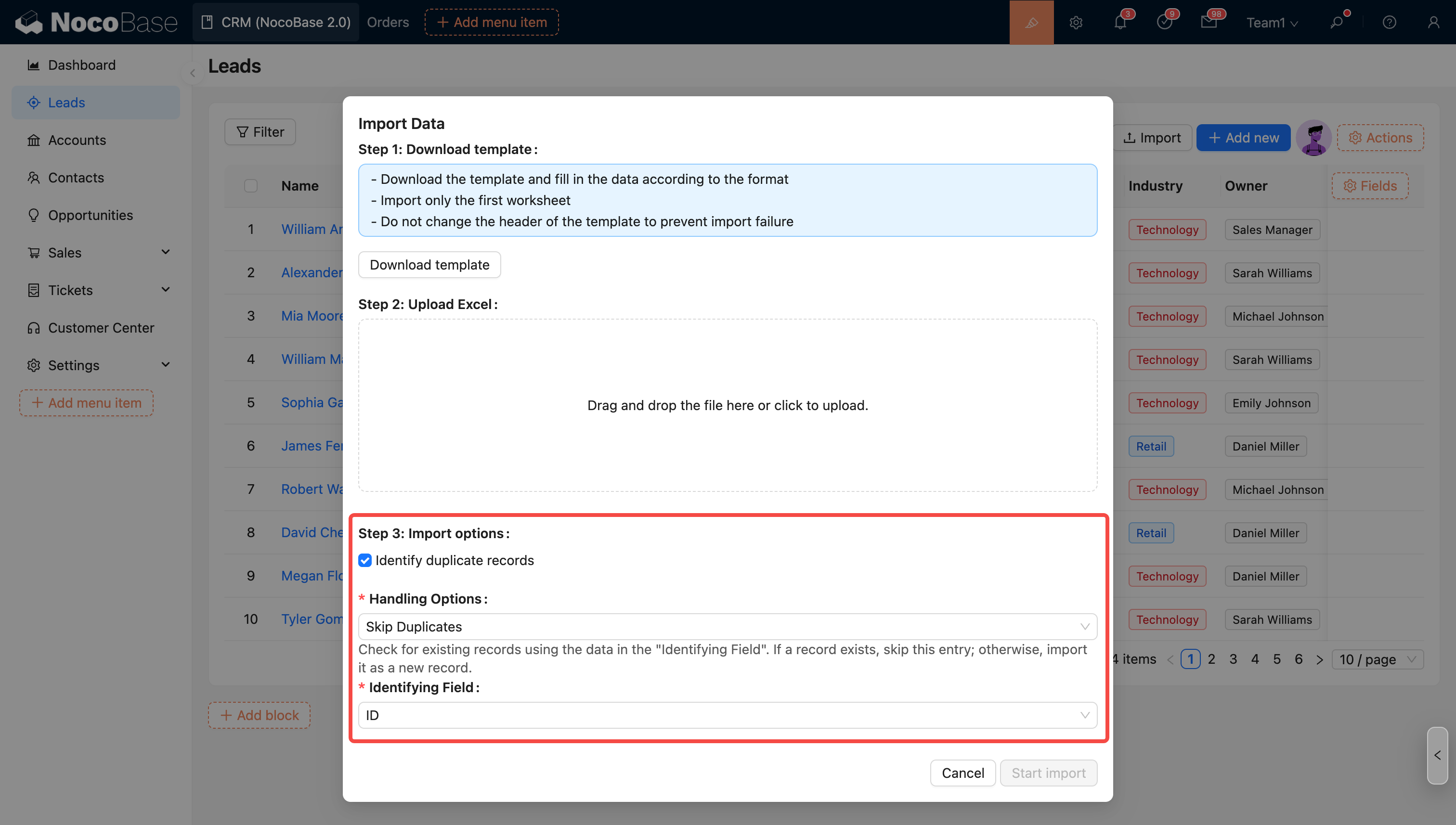
インポート設定
インポートオプション - ワークフローをトリガーするかどうか
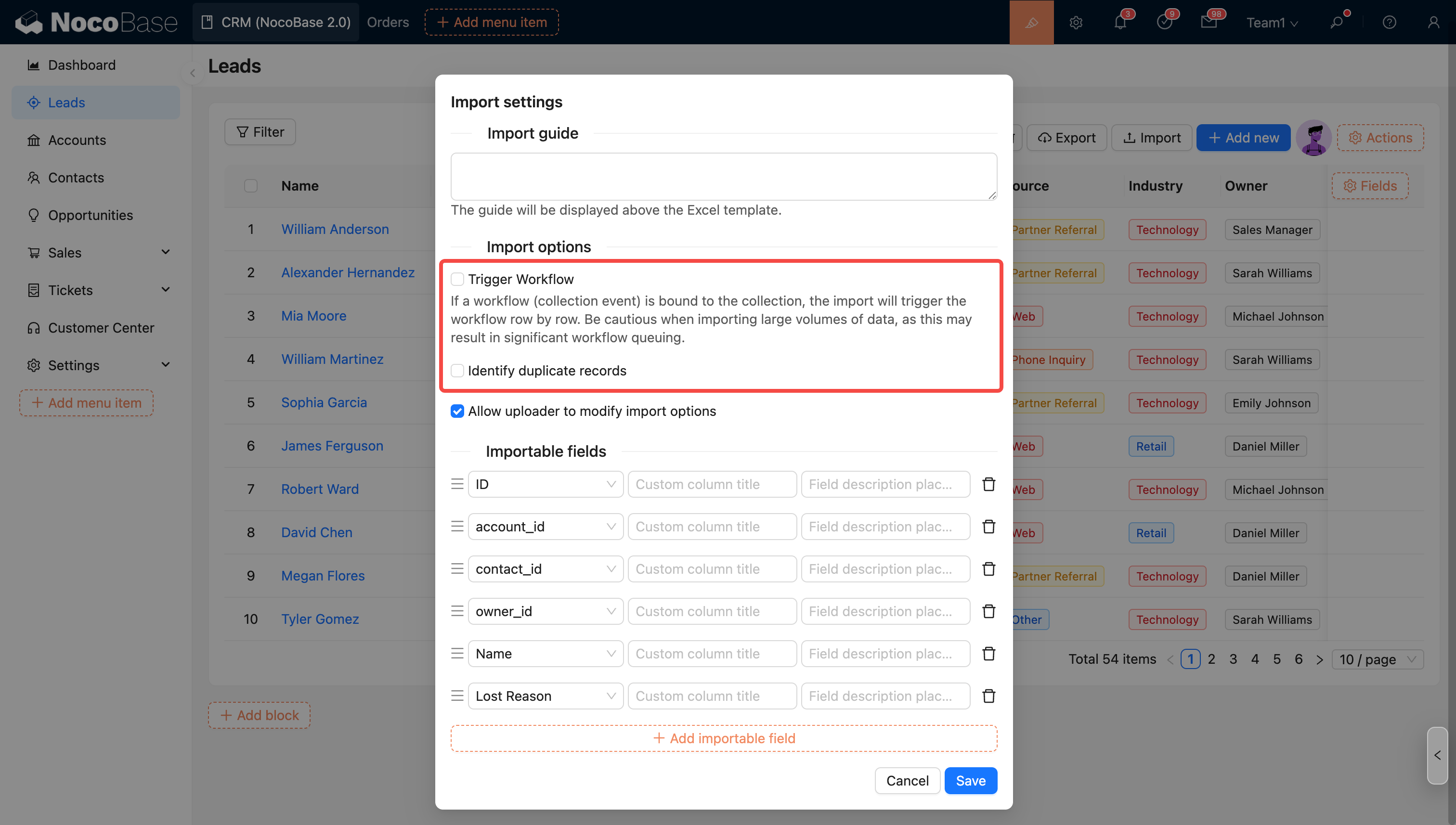
インポート時にワークフローをトリガーするかどうかを選択できます。このオプションをチェックし、そのコレクションがワークフロー(コレクションイベント)にバインドされている場合、インポートは各行に対してワークフローの実行をトリガーします。
インポートオプション - 重複レコードの識別
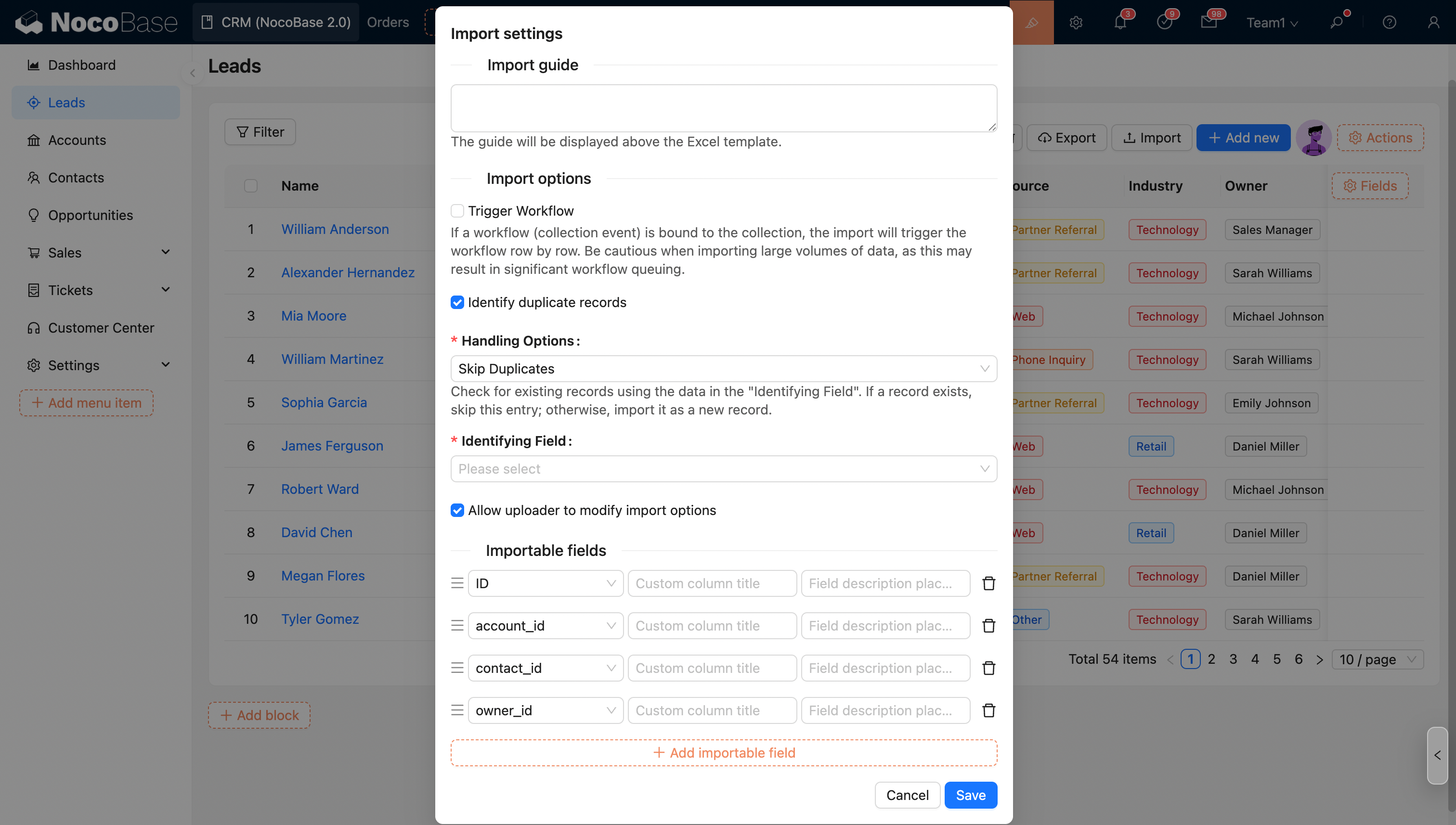
このオプションをチェックし、対応するモードを選択すると、インポート時に重複レコードが識別され、処理されます。
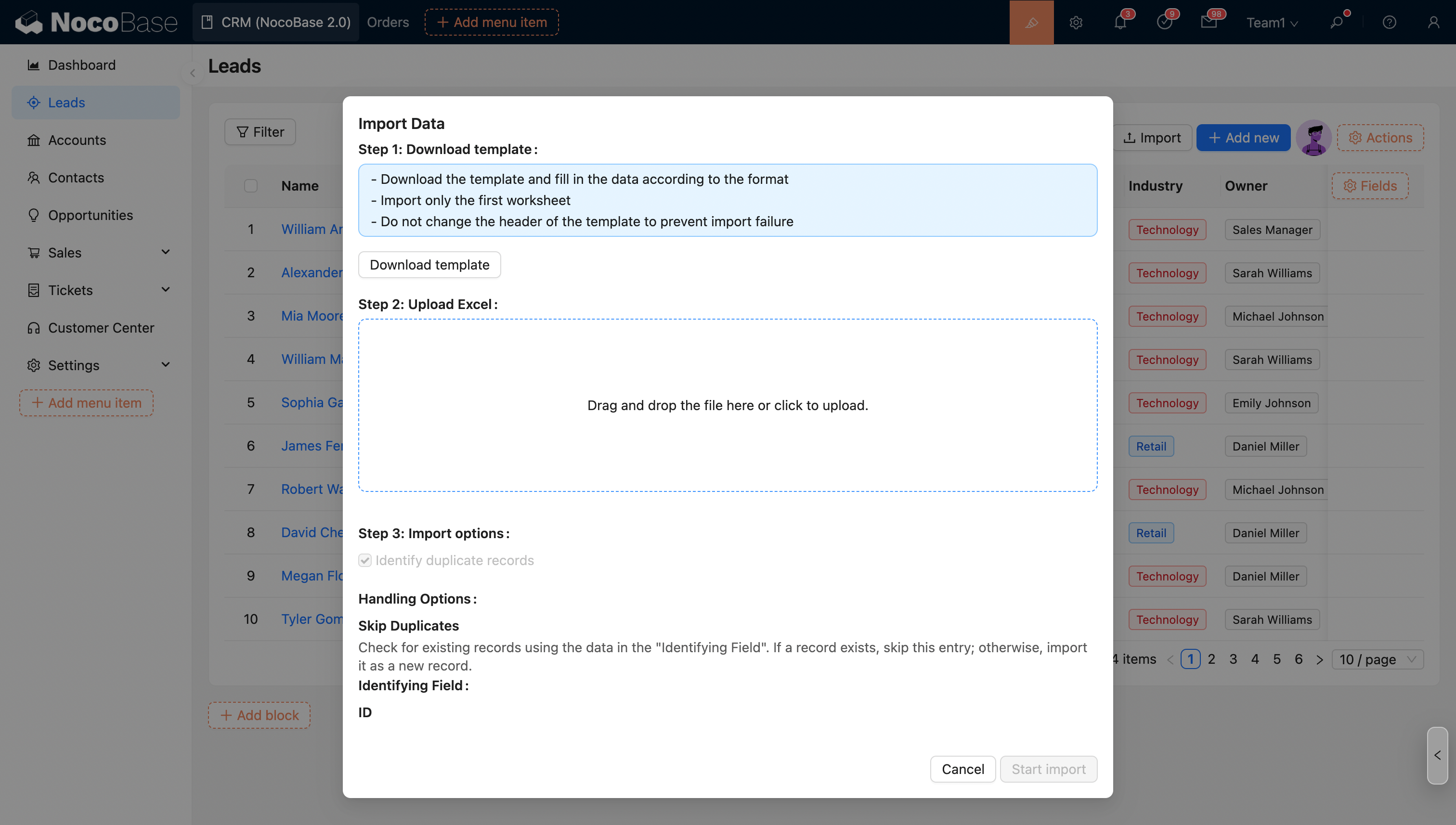
インポート設定のオプションはデフォルト値として適用されます。管理者は、アップロード者がこれらのオプション(ワークフローをトリガーするオプションを除く)を変更することを許可するかどうかを制御できます。
アップロード者の権限設定
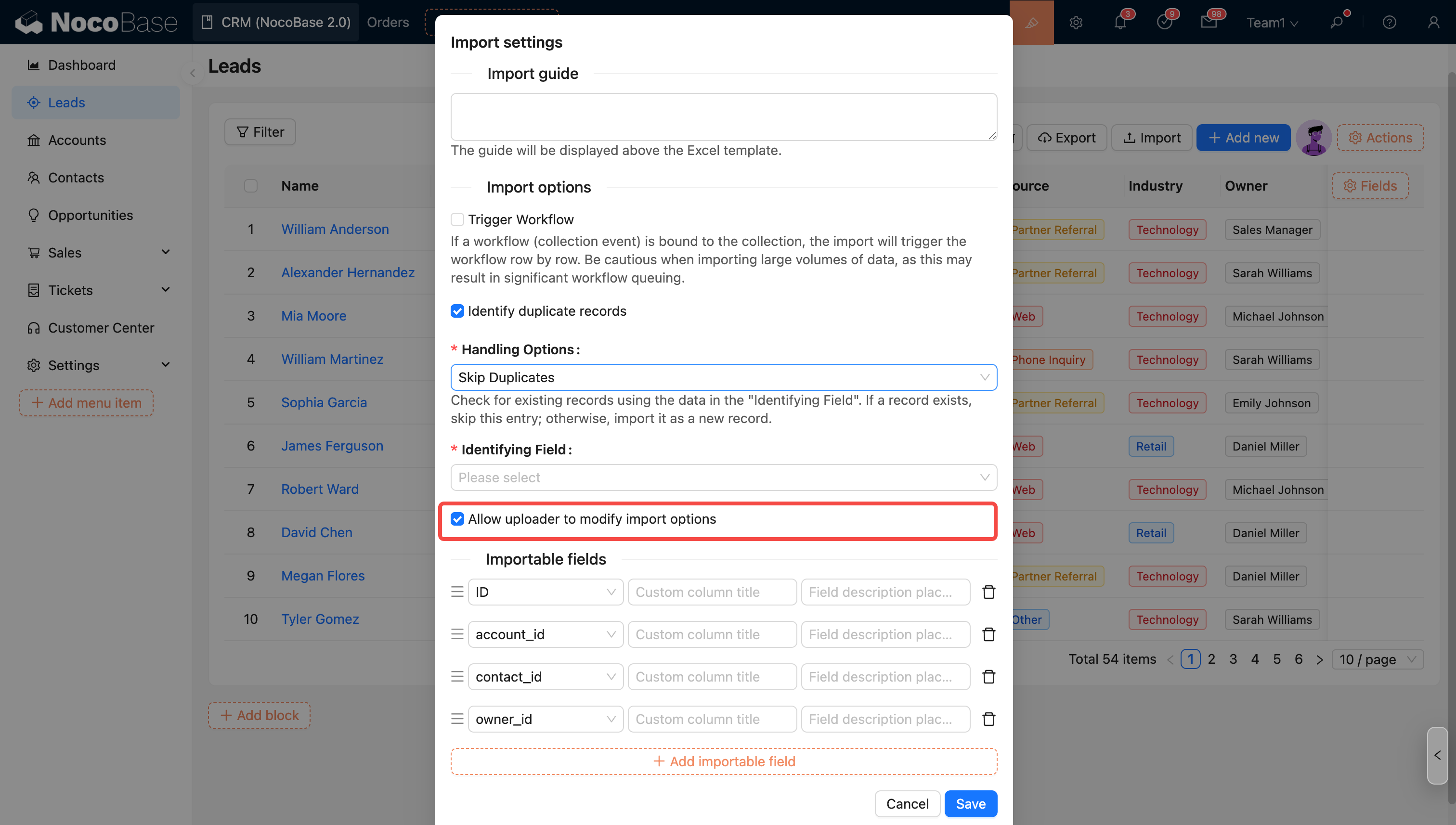
- アップロード者がインポートオプションを変更することを許可する
- アップロード者がインポートオプションを変更することを禁止する
モードの説明
- 重複レコードをスキップ: 「識別フィールド」の内容に基づいて既存のレコードを検索し、レコードがすでに存在する場合はその行をスキップします。存在しない場合は、新しいレコードとしてインポートします。
- 重複レコードを更新: 「識別フィールド」の内容に基づいて既存のレコードを検索し、レコードがすでに存在する場合はそのレコードを更新します。存在しない場合は、新しいレコードとしてインポートします。
- 重複レコードのみを更新: 「識別フィールド」の内容に基づいて既存のレコードを検索し、レコードがすでに存在する場合はそのレコードを更新します。存在しない場合はスキップします。
識別フィールド
システムは、このフィールドの値に基づいて、行が重複レコードであるかどうかを識別します。