

이 문서는 AI로 번역되었습니다. 부정확한 내용이 있을 경우 영어 버전을 참조하세요
JSON 변수 매핑
워크플로우: JSON 변수 매핑Community Edition+v1.6.0
소개
상위 노드 결과의 복잡한 JSON 구조를 변수로 매핑하여 후속 노드에서 사용할 수 있도록 합니다. 예를 들어, SQL 작업 및 HTTP 요청 노드의 결과를 매핑한 후에는 후속 노드에서 해당 속성 값을 사용할 수 있습니다.
JSON 계산 노드와 달리, JSON 변수 매핑 노드는 사용자 지정 표현식을 지원하지 않으며 서드파티 엔진을 기반으로 하지 않습니다. 이 노드는 JSON 구조의 속성 값을 매핑하는 데만 사용되지만, 사용하기가 더 간단합니다.
노드 생성
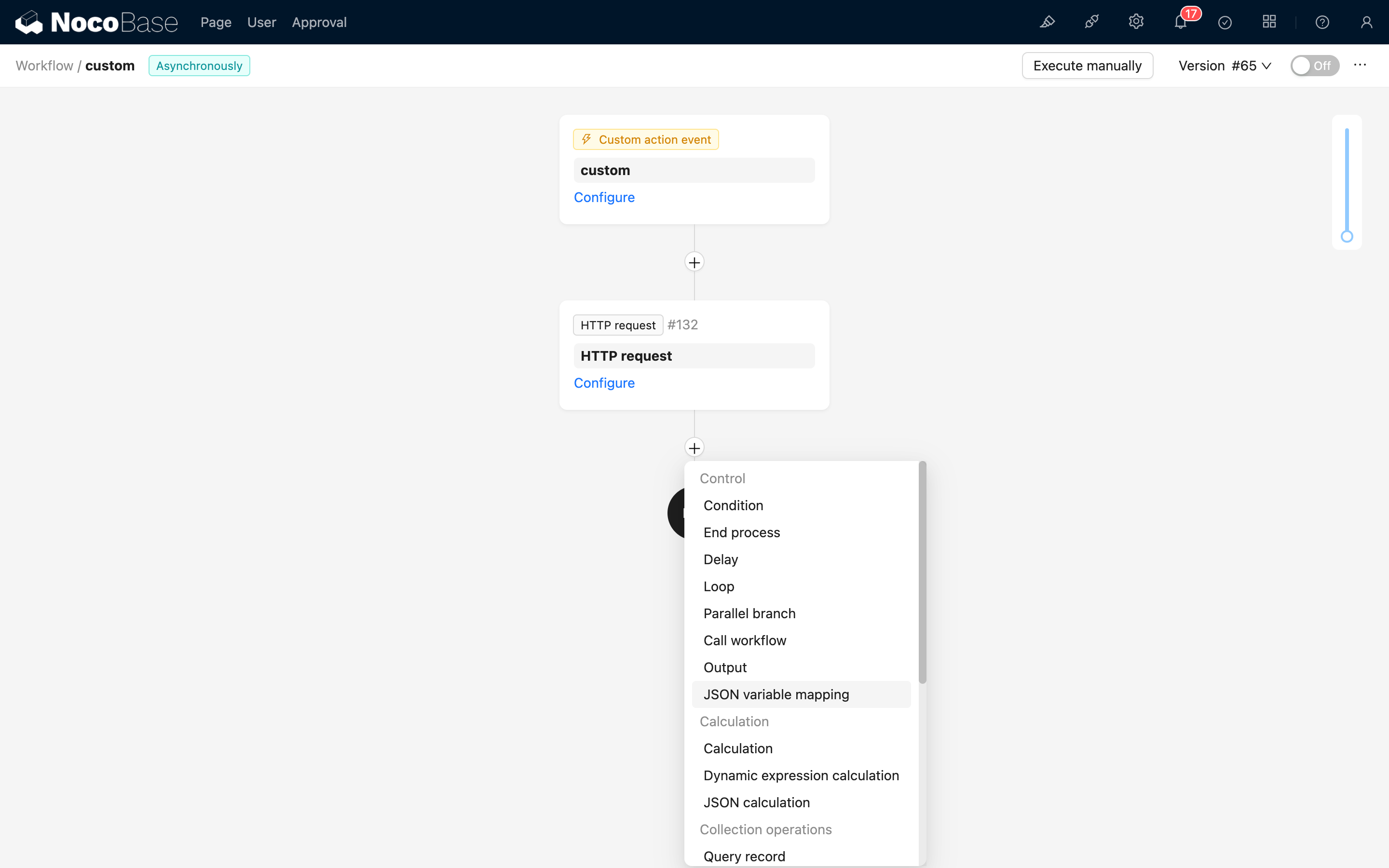
워크플로우 설정 화면에서 플로우 내의 더하기("+"") 버튼을 클릭하여 "JSON 변수 매핑" 노드를 추가합니다.
노드 설정
데이터 소스
데이터 소스는 상위 노드의 결과이거나 워크플로우 컨텍스트 내의 데이터 객체일 수 있습니다. 일반적으로 내장된 구조가 없는 데이터 객체이며, 예를 들어 SQL 노드 또는 HTTP 요청 노드의 결과와 같습니다.
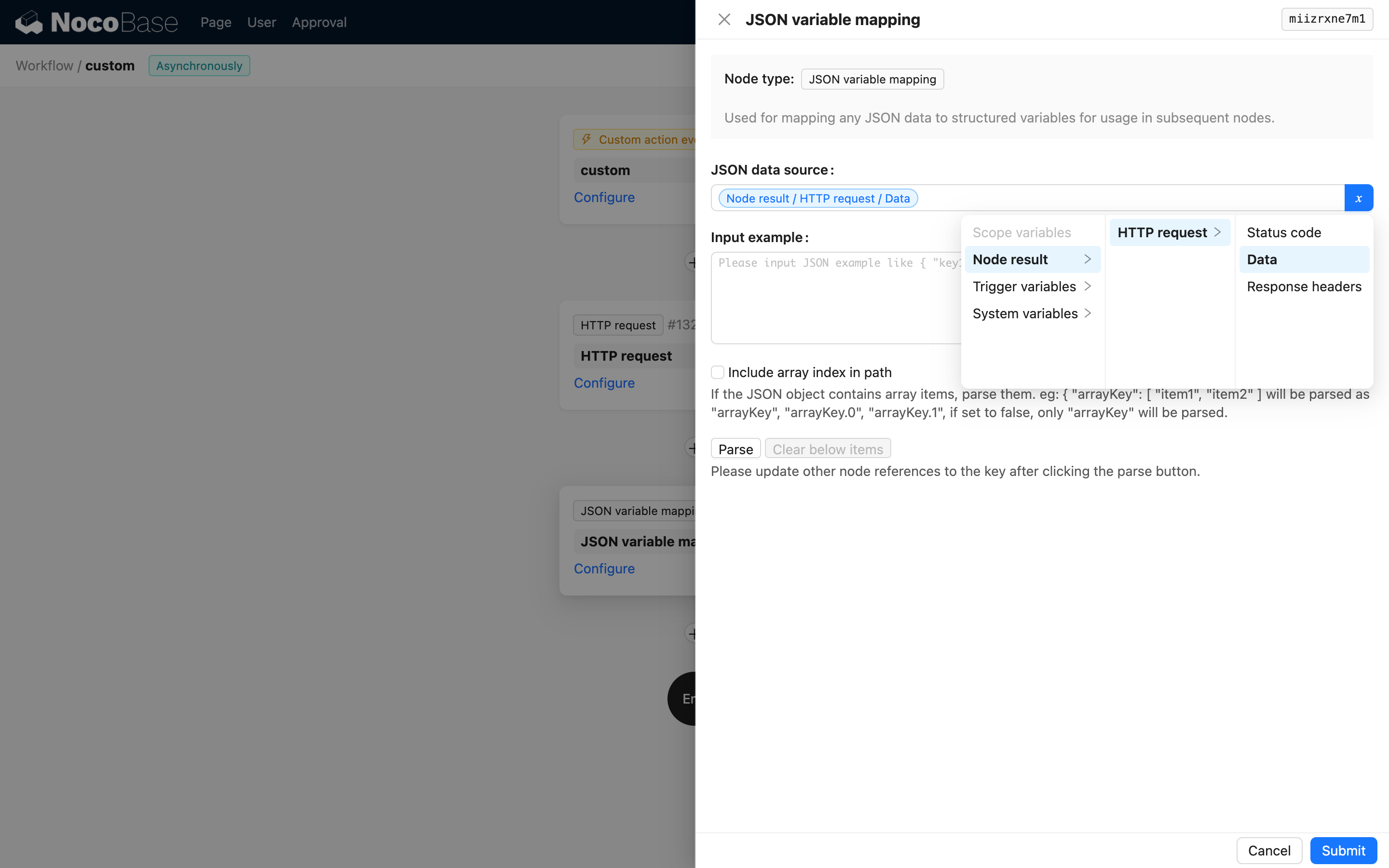
샘플 데이터 입력
샘플 데이터를 붙여넣고 파싱 버튼을 클릭하면 변수 목록이 자동으로 생성됩니다.
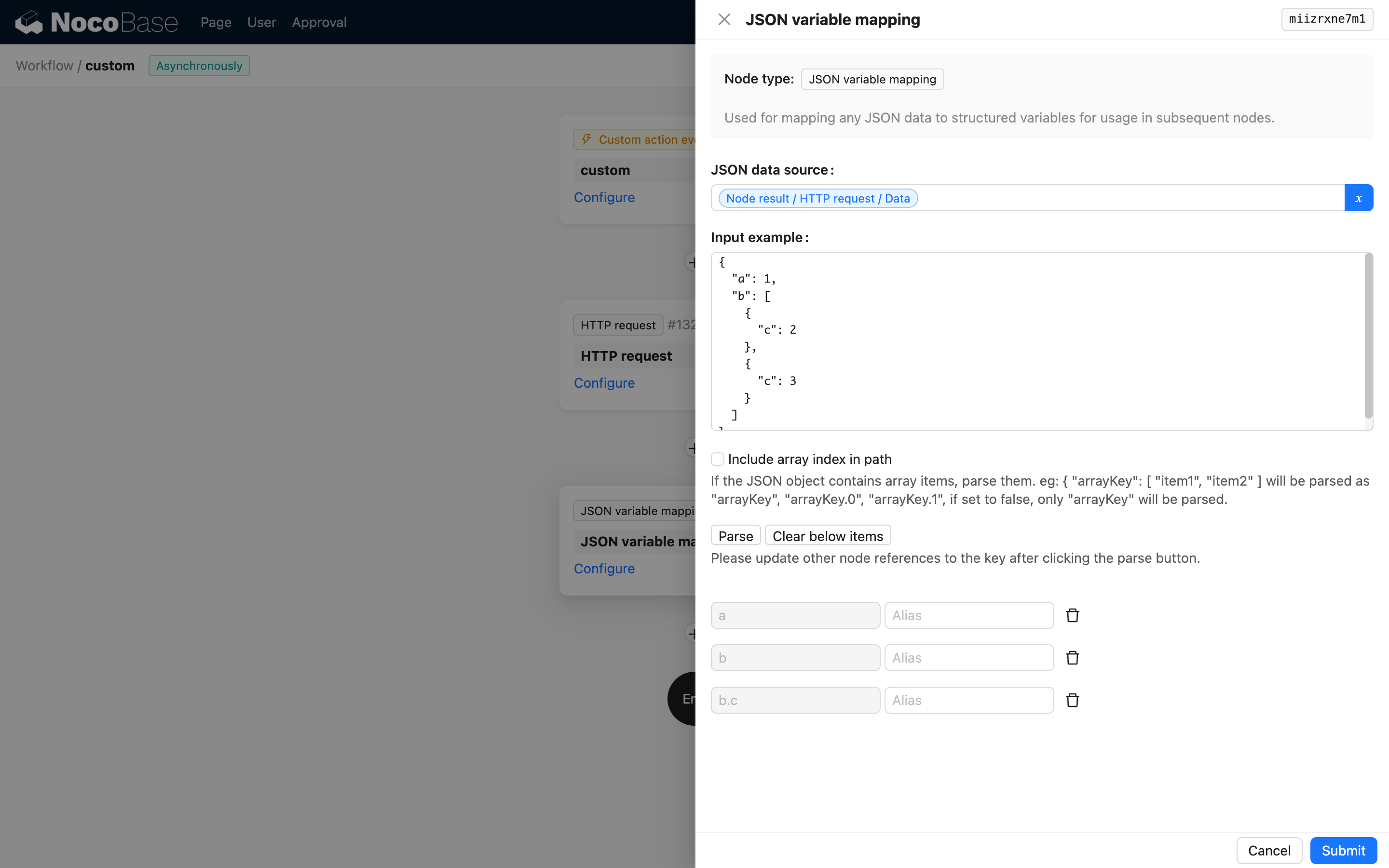
자동으로 생성된 목록에서 사용하지 않을 변수가 있다면 삭제 버튼을 클릭하여 제거할 수 있습니다.
샘플 데이터는 최종 실행 결과가 아니며, 변수 목록을 생성하는 데만 사용됩니다.
경로에 배열 인덱스 포함
이 옵션을 선택하지 않으면 NocoBase 워크플로우의 기본 변수 처리 방식에 따라 배열 내용이 매핑됩니다. 예를 들어, 다음 샘플을 입력하면:
생성된 변수에서 b.c는 배열 [2, 3]을 나타냅니다.
이 옵션을 선택하면 변수 경로에 배열 인덱스가 포함됩니다. 예를 들어 b.0.c 및 b.1.c와 같이 말이죠.
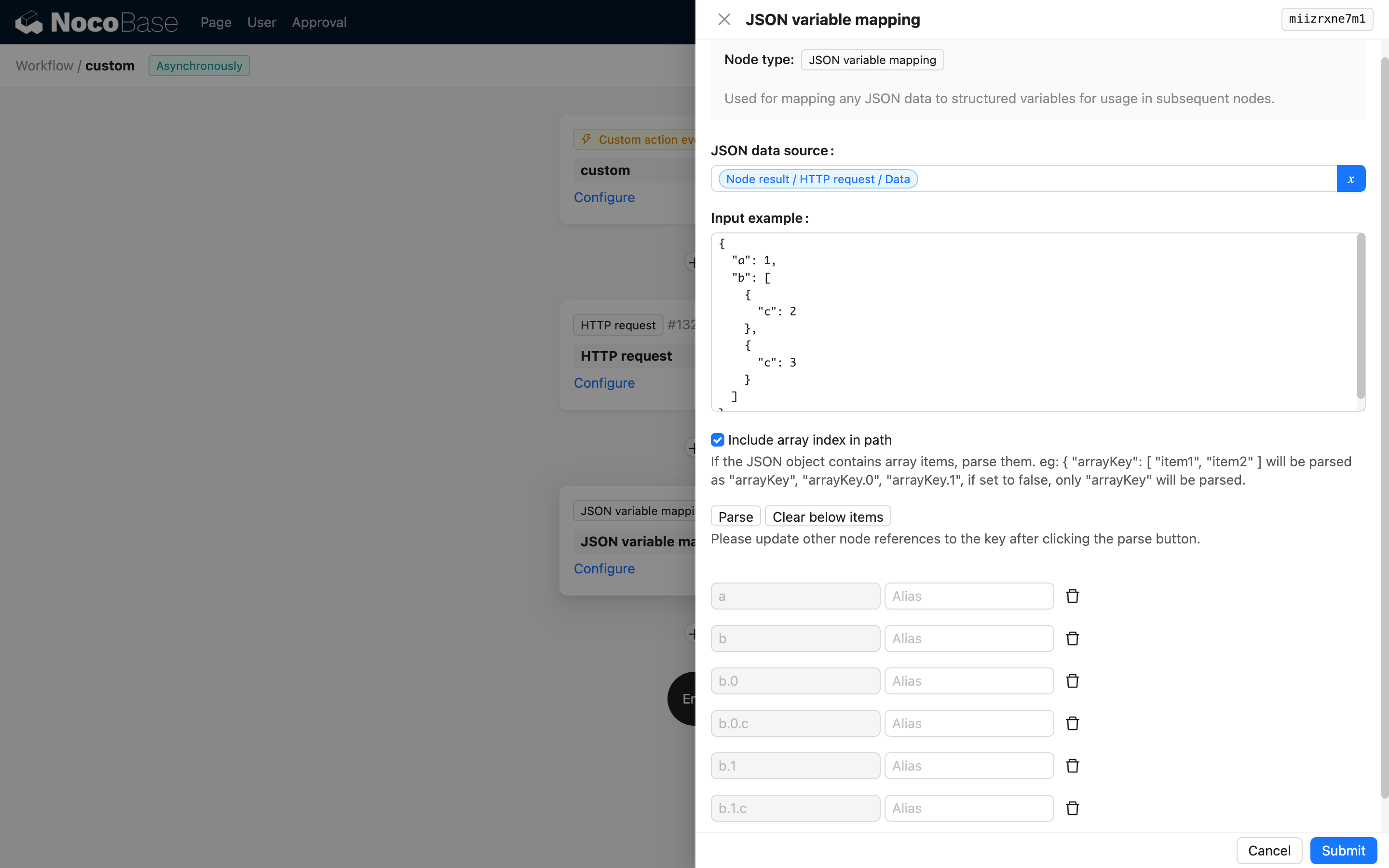
배열 인덱스를 포함하는 경우, 입력 데이터의 배열 인덱스가 일관적인지 확인해야 합니다. 그렇지 않으면 파싱 오류가 발생할 수 있습니다.
후속 노드에서 사용하기
후속 노드의 설정에서 JSON 변수 매핑 노드에서 생성된 변수를 사용할 수 있습니다.
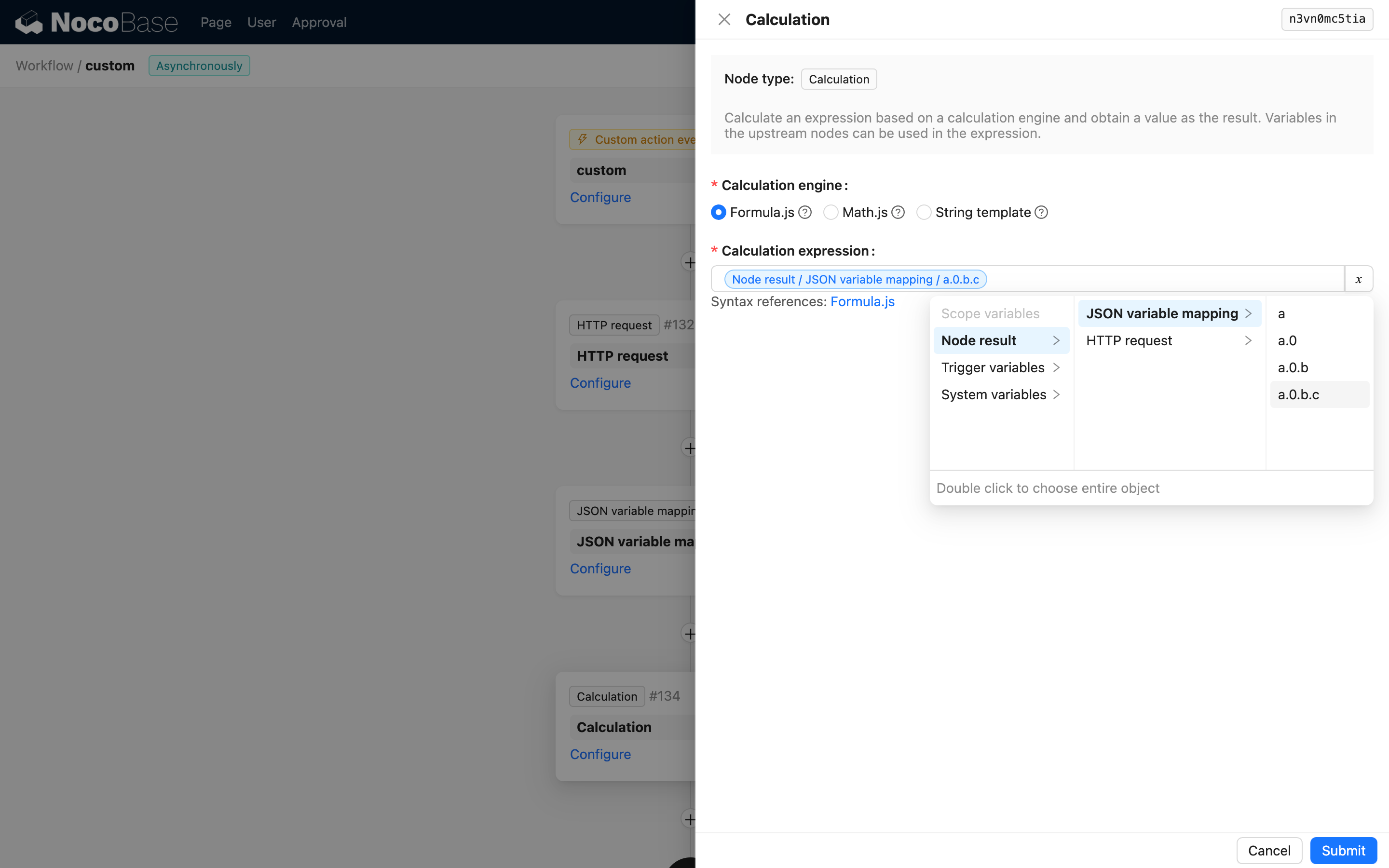
JSON 구조가 복잡할 수 있지만, 매핑한 후에는 해당 경로의 변수를 선택하기만 하면 됩니다.