

Ten dokument został przetłumaczony przez AI. W przypadku niedokładności, proszę odnieść się do wersji angielskiej
Mapowanie zmiennych JSON
Workflow: Mapowanie zmiennych JSONCommunity Edition+v1.6.0
Wprowadzenie
Umożliwia mapowanie złożonych struktur JSON, pochodzących z wyników węzłów nadrzędnych, na zmienne, które mogą być następnie wykorzystane w kolejnych węzłach. Przykładowo, po zmapowaniu wyników operacji SQL lub węzłów żądań HTTP, mogą Państwo używać ich wartości właściwości w dalszych węzłach.
W przeciwieństwie do węzła obliczeń JSON, węzeł mapowania zmiennych JSON nie obsługuje niestandardowych wyrażeń i nie bazuje na silnikach stron trzecich. Służy wyłącznie do mapowania wartości właściwości w strukturze JSON, ale jest prostszy w użyciu.
Tworzenie węzła
W interfejsie konfiguracji przepływu pracy, proszę kliknąć przycisk plusa („+”) w przepływie, aby dodać węzeł „Mapowanie zmiennych JSON”:
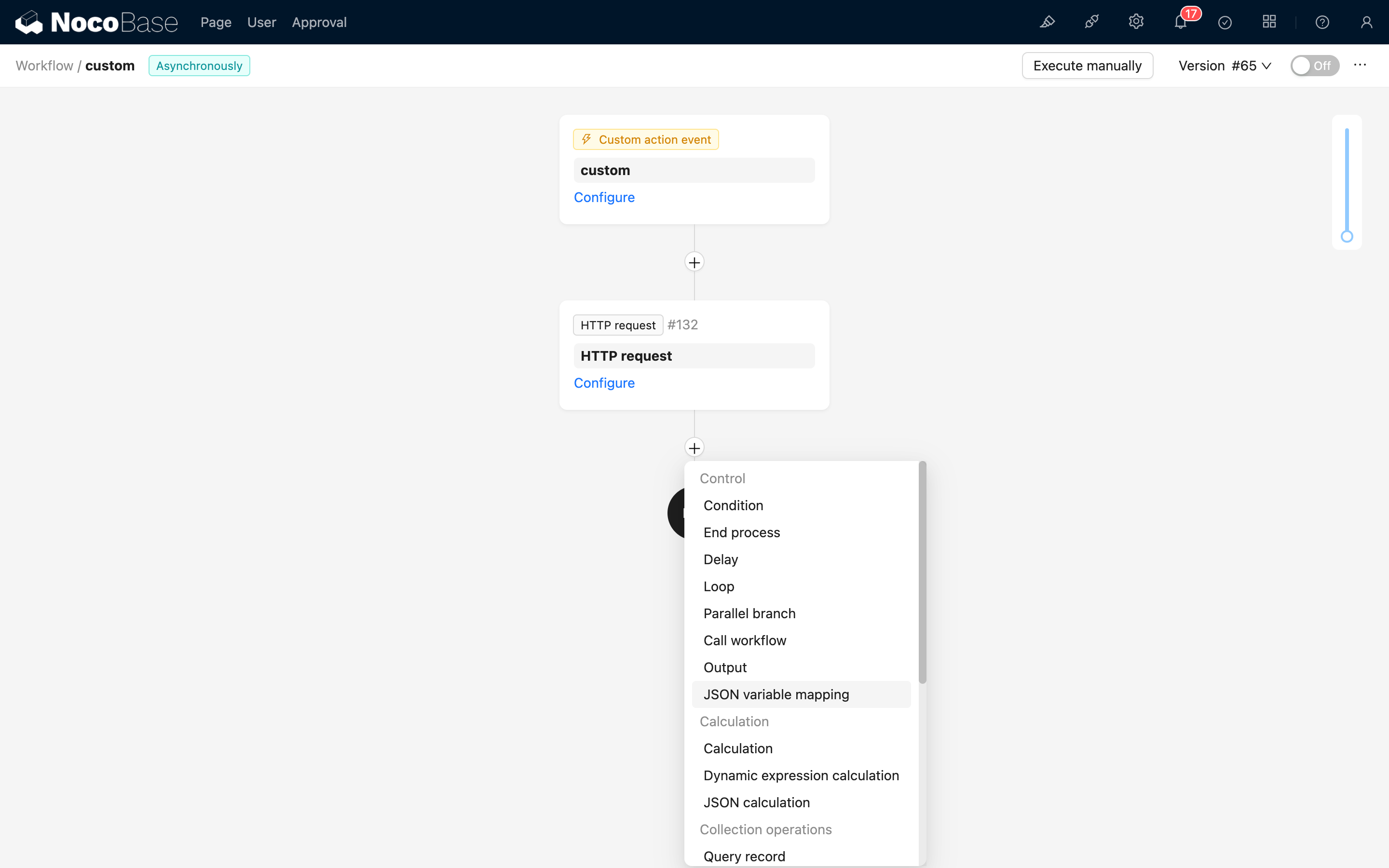
Konfiguracja węzła
Źródło danych
Źródło danych może być wynikiem węzła nadrzędnego lub obiektem danych w kontekście procesu. Zazwyczaj jest to niestrukturyzowany obiekt danych, taki jak wynik węzła SQL lub węzła żądania HTTP.
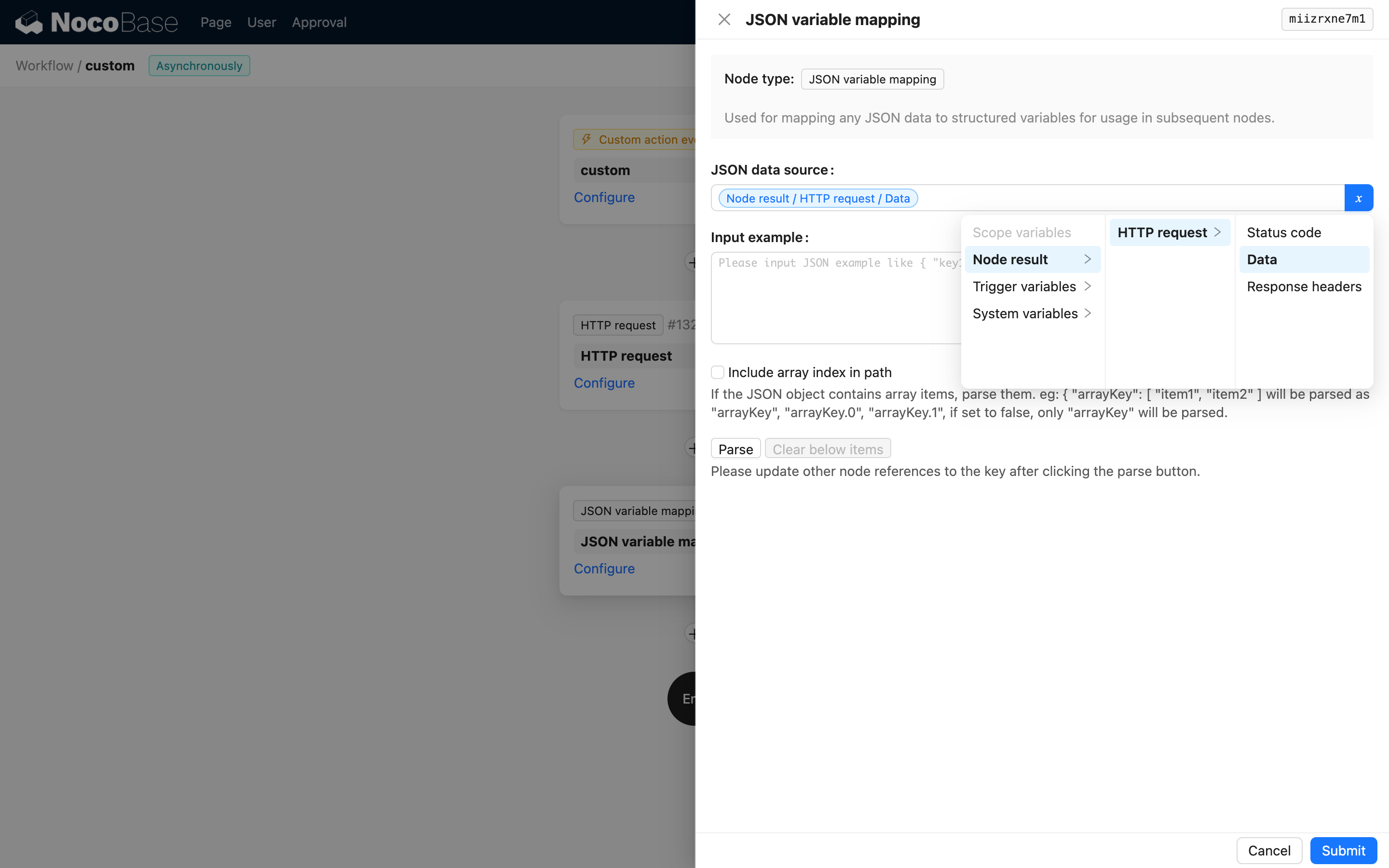
Wprowadzanie przykładowych danych
Proszę wkleić przykładowe dane i kliknąć przycisk „Parsuj”, aby automatycznie wygenerować listę zmiennych:
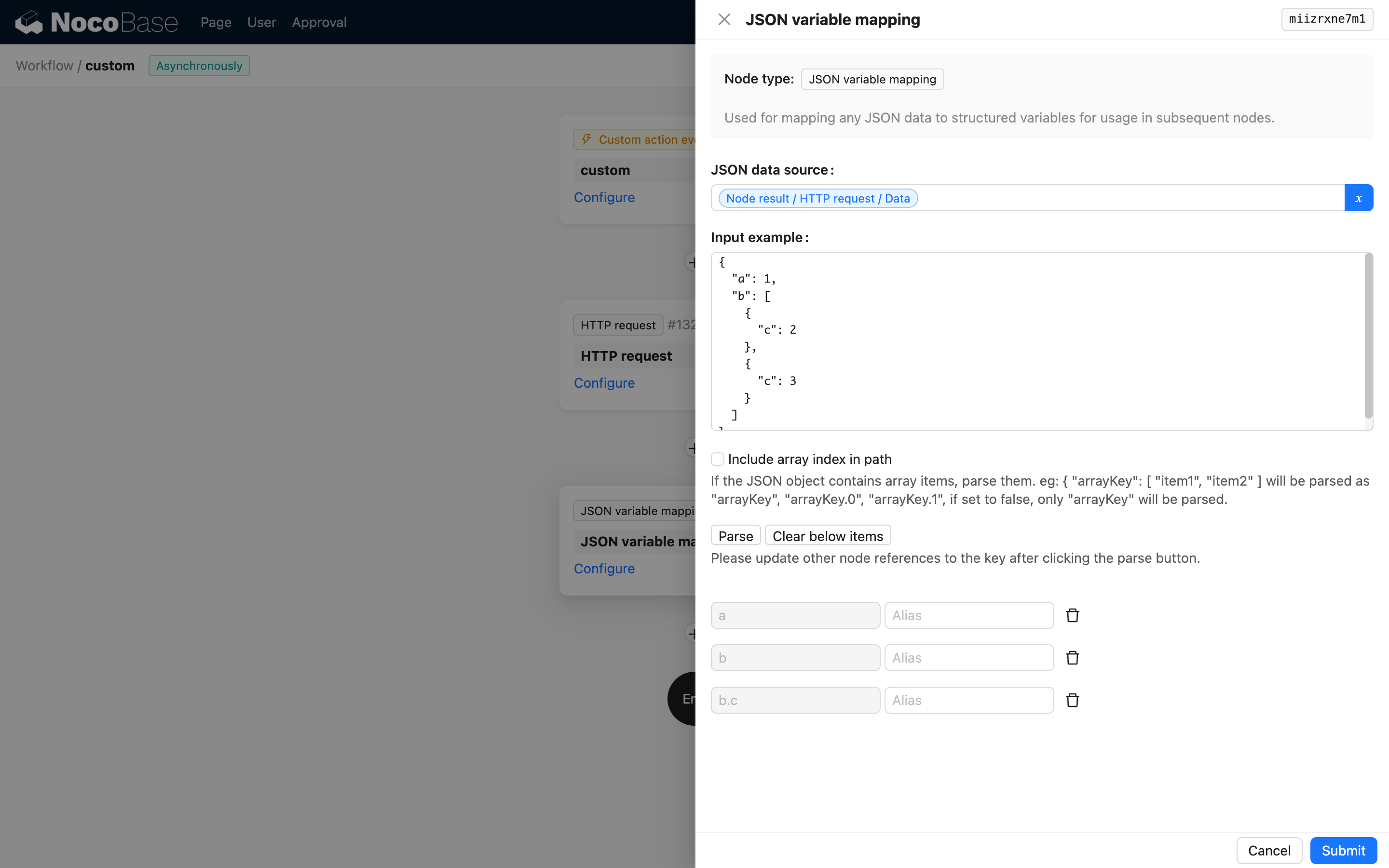
Jeśli na automatycznie wygenerowanej liście znajdują się zmienne, których Państwo nie potrzebują, można je usunąć, klikając przycisk „Usuń”.
Przykładowe dane nie są ostatecznym wynikiem wykonania; służą jedynie do wspomagania generowania listy zmiennych.
Ścieżka zawiera indeks tablicy
Jeśli opcja nie jest zaznaczona, zawartość tablicy zostanie zmapowana zgodnie z domyślnym sposobem obsługi zmiennych w przepływach pracy NocoBase. Na przykład, po wprowadzeniu następującego przykładu:
W wygenerowanych zmiennych b.c będzie reprezentować tablicę [2, 3].
Jeśli ta opcja zostanie zaznaczona, ścieżka zmiennej będzie zawierać indeks tablicy, na przykład b.0.c i b.1.c.
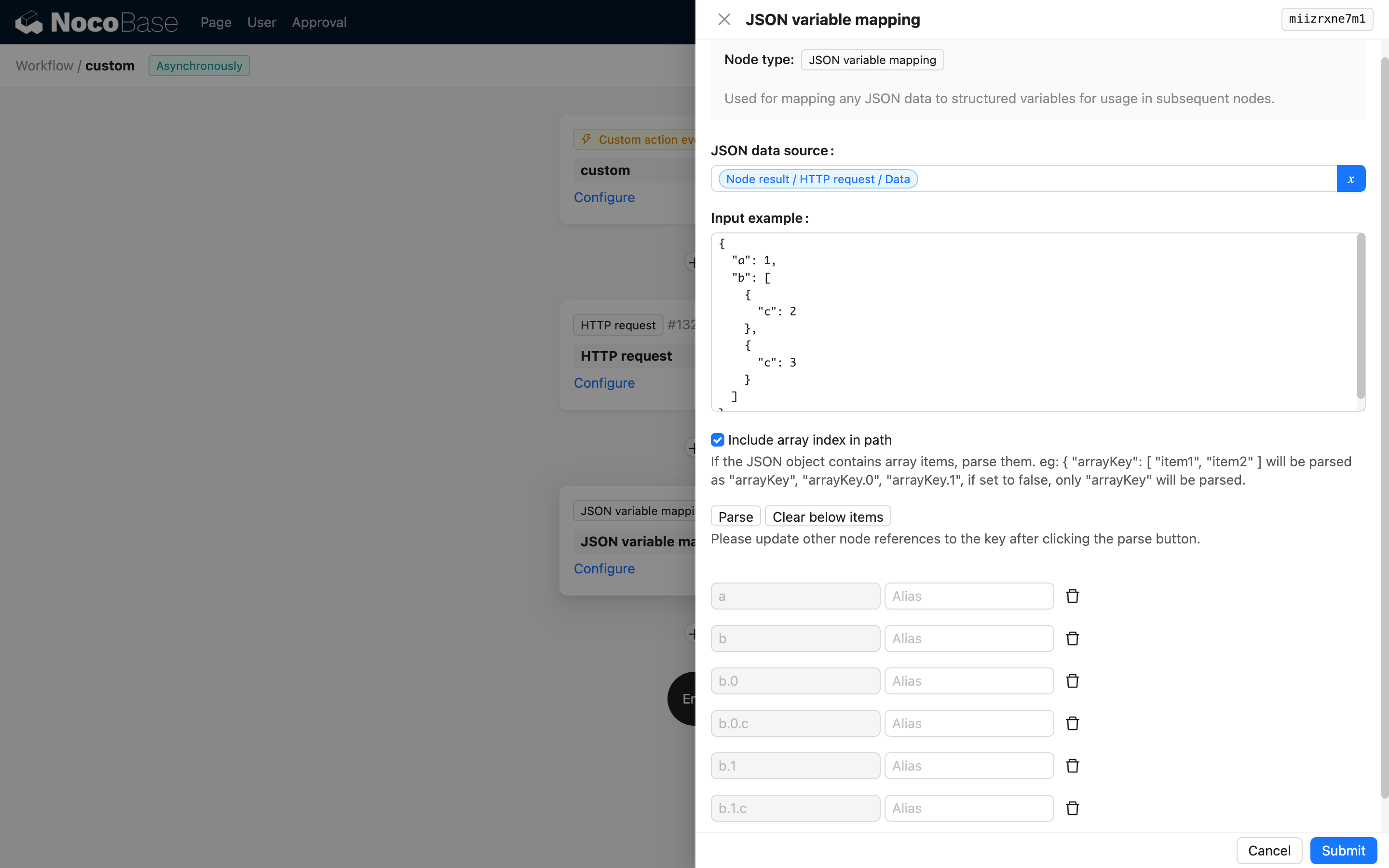
W przypadku uwzględniania indeksów tablicy należy upewnić się, że indeksy tablicy w danych wejściowych są spójne; w przeciwnym razie może to spowodować błąd parsowania.
Użycie w kolejnych węzłach
W konfiguracji kolejnych węzłów mogą Państwo używać zmiennych wygenerowanych przez węzeł mapowania zmiennych JSON:
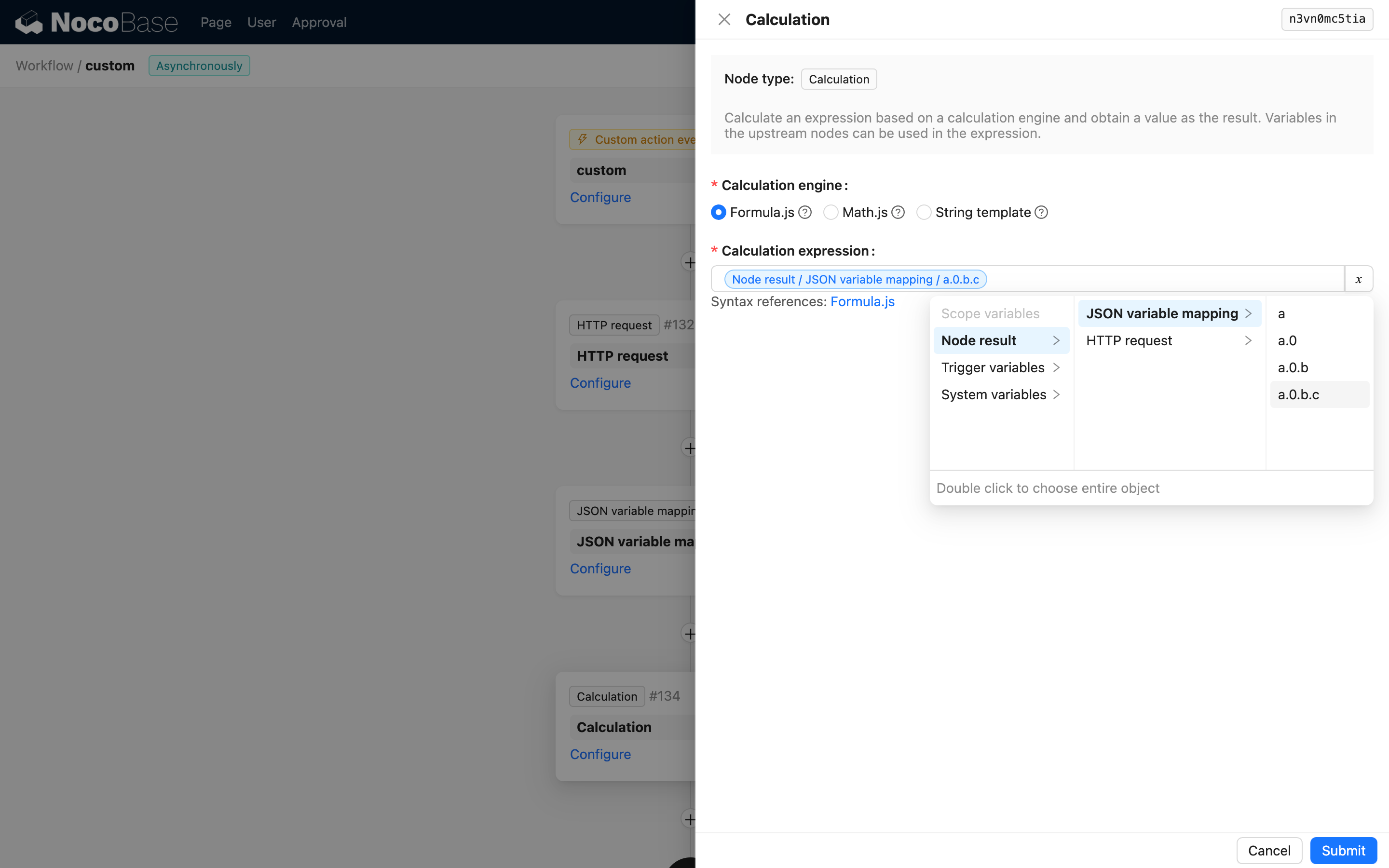
Chociaż struktura JSON może być złożona, po zmapowaniu wystarczy wybrać zmienną dla odpowiedniej ścieżki.