

Tento dokument byl přeložen umělou inteligencí. V případě nepřesností se prosím obraťte na anglickou verzi
Rozšíření typů uzlů
Typ uzlu je v podstatě operační instrukce. Různé instrukce představují různé operace prováděné v rámci pracovního postupu.
Podobně jako u spouštěčů se i rozšíření typů uzlů dělí na dvě části: serverovou a klientskou. Serverová část musí implementovat logiku pro registrovanou instrukci, zatímco klientská část musí poskytovat konfiguraci uživatelského rozhraní pro parametry uzlu, ve kterém se instrukce nachází.
Serverová část
Nejjednodušší instrukce uzlu
Jádrem instrukce je funkce, což znamená, že metoda run ve třídě instrukce musí být implementována pro provedení logiky instrukce. V rámci funkce lze provádět libovolné potřebné operace, jako jsou databázové operace, operace se soubory, volání API třetích stran a podobně.
Všechny instrukce musí být odvozeny od základní třídy Instruction. Nejjednodušší instrukce vyžaduje pouze implementaci funkce run:
A tuto instrukci zaregistrujte do pluginu pracovního postupu:
Hodnota stavu (status) v návratovém objektu instrukce je povinná a musí být jednou z hodnot konstanty JOB_STATUS. Tato hodnota určuje směr následného zpracování daného uzlu v pracovním postupu. Obvykle se používá JOB_STATUS.RESOVLED, což znamená, že uzel byl úspěšně proveden a bude pokračovat v provádění dalších uzlů. Pokud je potřeba předem uložit hodnotu výsledku, můžete také zavolat metodu processor.saveJob a vrátit její návratový objekt. Procesor na základě tohoto objektu vygeneruje záznam o výsledku provedení.
Hodnota výsledku uzlu
Pokud existuje specifický výsledek provedení, zejména data připravená pro použití následnými uzly, lze je vrátit prostřednictvím vlastnosti result a uložit do objektu úlohy uzlu:
Zde node.config představuje konfigurační položku uzlu, která může nabývat libovolné požadované hodnoty a bude uložena jako pole typu JSON v odpovídajícím záznamu uzlu v databázi.
Zpracování chyb instrukce
Pokud během provádění může dojít k výjimkám, můžete je předem zachytit a vrátit stav selhání:
Pokud předvídatelné výjimky nebudou zachyceny, engine pracovního postupu je automaticky zachytí a vrátí stav chyby, aby se zabránilo pádu programu způsobenému nezachycenými výjimkami.
Asynchronní uzly
Pokud je potřeba řídit tok nebo provádět asynchronní (časově náročné) I/O operace, metoda run může vrátit objekt se stavem JOB_STATUS.PENDING, čímž vyzve exekutor k čekání (pozastavení). Po dokončení externích asynchronních operací pak oznámí enginu pracovního postupu, aby pokračoval v provádění. Pokud funkce run vrátí hodnotu stavu pozastavení, musí daná instrukce implementovat metodu resume, jinak nelze obnovit provádění pracovního postupu:
Zde paymentService odkazuje na platební službu. V callbacku služby se spustí obnovení provádění odpovídající úlohy v pracovním postupu a aktuální proces se nejprve ukončí. Následně engine pracovního postupu vytvoří nový procesor, který předá metodě resume uzlu, čímž se pokračuje v provádění dříve pozastaveného uzlu.
Zde zmíněná „asynchronní operace“ se nevztahuje na async funkce v JavaScriptu, ale spíše na operace, které nevracejí výsledek okamžitě při interakci s jinými externími systémy, například platební služba, která potřebuje počkat na další oznámení, aby zjistila výsledek.
Stav výsledku uzlu
Stav provedení uzlu ovlivňuje úspěch nebo selhání celého pracovního postupu. Obvykle, pokud nejsou přítomny žádné větve, selhání jednoho uzlu přímo způsobí selhání celého pracovního postupu. Nejběžnější scénář je, že pokud se uzel provede úspěšně, pokračuje se na další uzel v tabulce uzlů, dokud nejsou žádné další uzly, a celý pracovní postup se dokončí s úspěšným stavem.
Pokud některý uzel během provádění vrátí stav selhání, engine jej zpracuje odlišně v závislosti na následujících dvou situacích:
-
Uzel, který vrací stav selhání, se nachází v hlavním pracovním postupu, tj. není součástí žádného větvového pracovního postupu otevřeného nadřazeným uzlem. V takovém případě bude celý hlavní pracovní postup vyhodnocen jako selhaný a proces se ukončí.
-
Uzel, který vrací stav selhání, se nachází v rámci větvového pracovního postupu. V takovém případě je odpovědnost za určení dalšího stavu pracovního postupu předána uzlu, který větev otevřel. Vnitřní logika tohoto uzlu rozhodne o stavu následného pracovního postupu a toto rozhodnutí se rekurzivně propaguje až k hlavnímu pracovnímu postupu.
Nakonec je další stav celého pracovního postupu určen na uzlech hlavního pracovního postupu. Pokud uzel v hlavním pracovním postupu vrátí selhání, celý pracovní postup skončí stavem selhání.
Pokud kterýkoli uzel po provedení vrátí stav „čekání“, celý proces provádění bude dočasně přerušen a pozastaven, čekající na událost definovanou odpovídajícím uzlem, která spustí obnovení provádění pracovního postupu. Například u manuálního uzlu se po jeho provedení proces pozastaví ve stavu „čekání“, dokud nedojde k manuálnímu zásahu do tohoto procesu, který rozhodne o schválení či neschválení. Pokud je ručně zadaný stav schválení, pokračuje se v následných uzlech pracovního postupu; v opačném případě se postupuje podle dříve popsané logiky selhání.
Další stavy návratových instrukcí naleznete v části Referenční příručka API pracovního postupu.
Předčasné ukončení
V některých speciálních pracovních postupech může být nutné ukončit proces přímo v určitém uzlu. Můžete vrátit null, což znamená ukončení aktuálního procesu a nebudou se provádět žádné následné uzly.
Tato situace je běžná u uzlů typu řízení toku, například u uzlu paralelní větve (odkaz na kód), kde se proces aktuálního uzlu ukončí, ale pro každou podvětev se spustí nové procesy a pokračuje se v jejich provádění.
:::warn{title=Upozornění} Plánování větvových pracovních postupů s rozšířenými uzly má určitou složitost a vyžaduje pečlivé zacházení a důkladné testování. :::
Další informace
Definice jednotlivých parametrů pro definování typů uzlů naleznete v části Referenční příručka API pracovního postupu.
Klientská část
Podobně jako u spouštěčů musí být konfigurační formulář pro instrukci (typ uzlu) implementován na straně klienta.
Nejjednodušší instrukce uzlu
Všechny instrukce musí být odvozeny od základní třídy Instruction. Související vlastnosti a metody se používají pro konfiguraci a použití uzlu.
Například, pokud potřebujeme poskytnout konfigurační rozhraní pro uzel typu náhodného číselného řetězce (randomString), který jsme definovali na serverové straně, a který má konfigurační položku digit představující počet číslic pro náhodné číslo, použijeme v konfiguračním formuláři číselné vstupní pole pro příjem uživatelského vstupu.
Identifikátor typu uzlu registrovaný na klientské straně musí být konzistentní s identifikátorem na serverové straně, jinak dojde k chybám.
Poskytování výsledků uzlů jako proměnných
Všimněte si metody useVariables v příkladu výše. Pokud potřebujete použít výsledek uzlu (část result) jako proměnnou pro následné uzly, musíte tuto metodu implementovat v děděné třídě instrukce a vrátit objekt, který odpovídá typu VariableOption. Tento objekt slouží jako strukturální popis výsledku provedení uzlu, poskytující mapování názvů proměnných pro výběr a použití v následných uzlech.
Typ VariableOption je definován následovně:
Jádrem je vlastnost value, která představuje segmentovanou hodnotu cesty názvu proměnné. label se používá pro zobrazení v rozhraní a children se používá k reprezentaci víceúrovňové struktury proměnných, což se uplatní, když je výsledek uzlu hluboce vnořený objekt.
Použitelná proměnná je v systému interně reprezentována jako řetězec šablony cesty oddělený znakem ., například {{jobsMapByNodeKey.2dw92cdf.abc}}. Zde $jobsMapByNodeKey představuje sadu výsledků všech uzlů (interně definováno, není třeba zpracovávat), 2dw92cdf je key uzlu a abc je vlastní vlastnost v objektu výsledku uzlu.
Kromě toho, jelikož výsledek uzlu může být také jednoduchá hodnota, je při poskytování proměnných uzlu vyžadováno, aby první úroveň musela být popisem samotného uzlu:
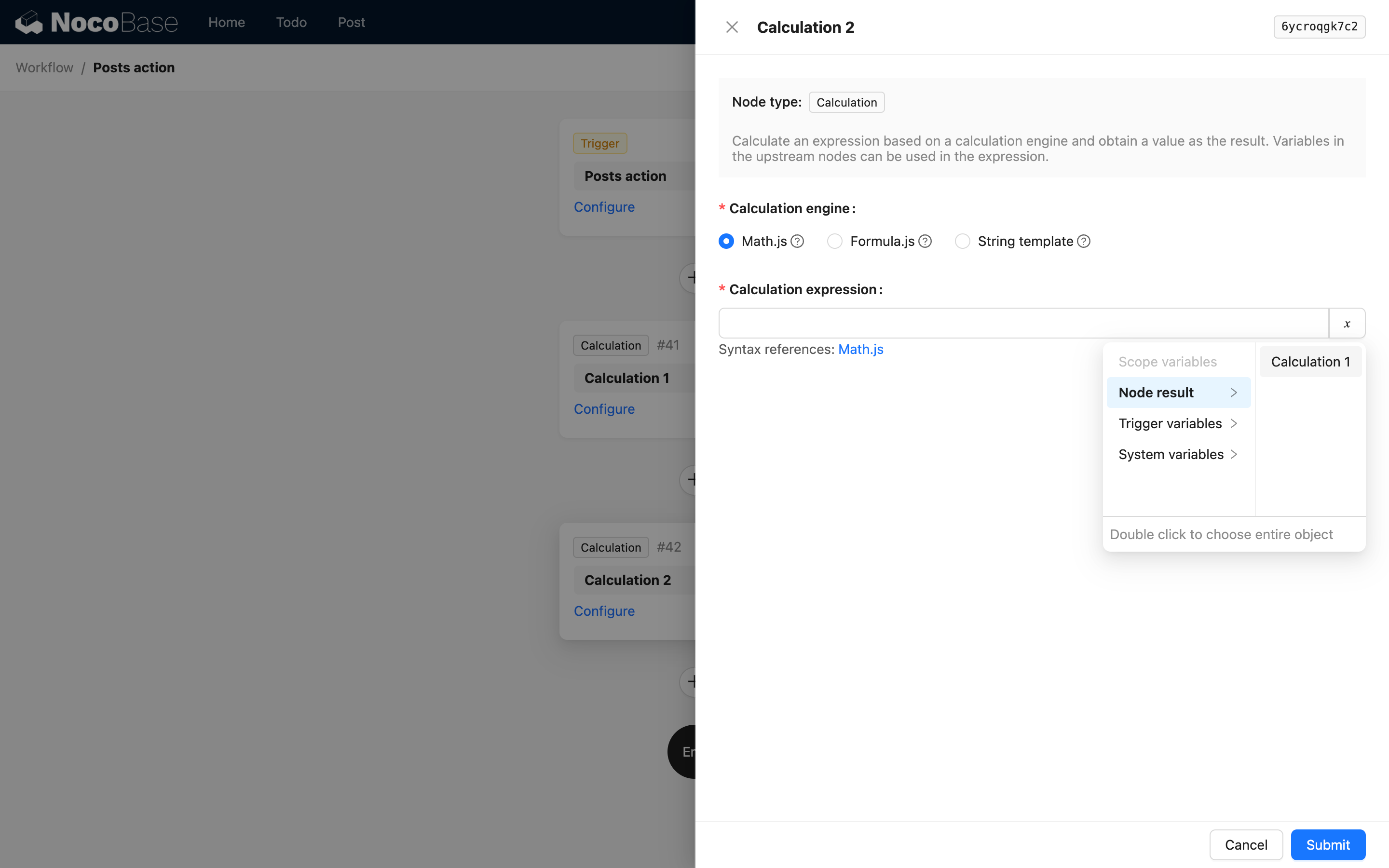
To znamená, že první úroveň je key a název uzlu. Například u odkazu na kód výpočetního uzlu, při použití výsledku výpočetního uzlu, jsou možnosti rozhraní následující:
Když je výsledek uzlu složitý objekt, můžete použít children k dalšímu popisu vnořených vlastností. Například vlastní instrukce může vrátit následující JSON data:
Pak ji můžete vrátit pomocí metody useVariables následovně:
Tímto způsobem můžete v následných uzlech použít následující rozhraní pro výběr proměnných:
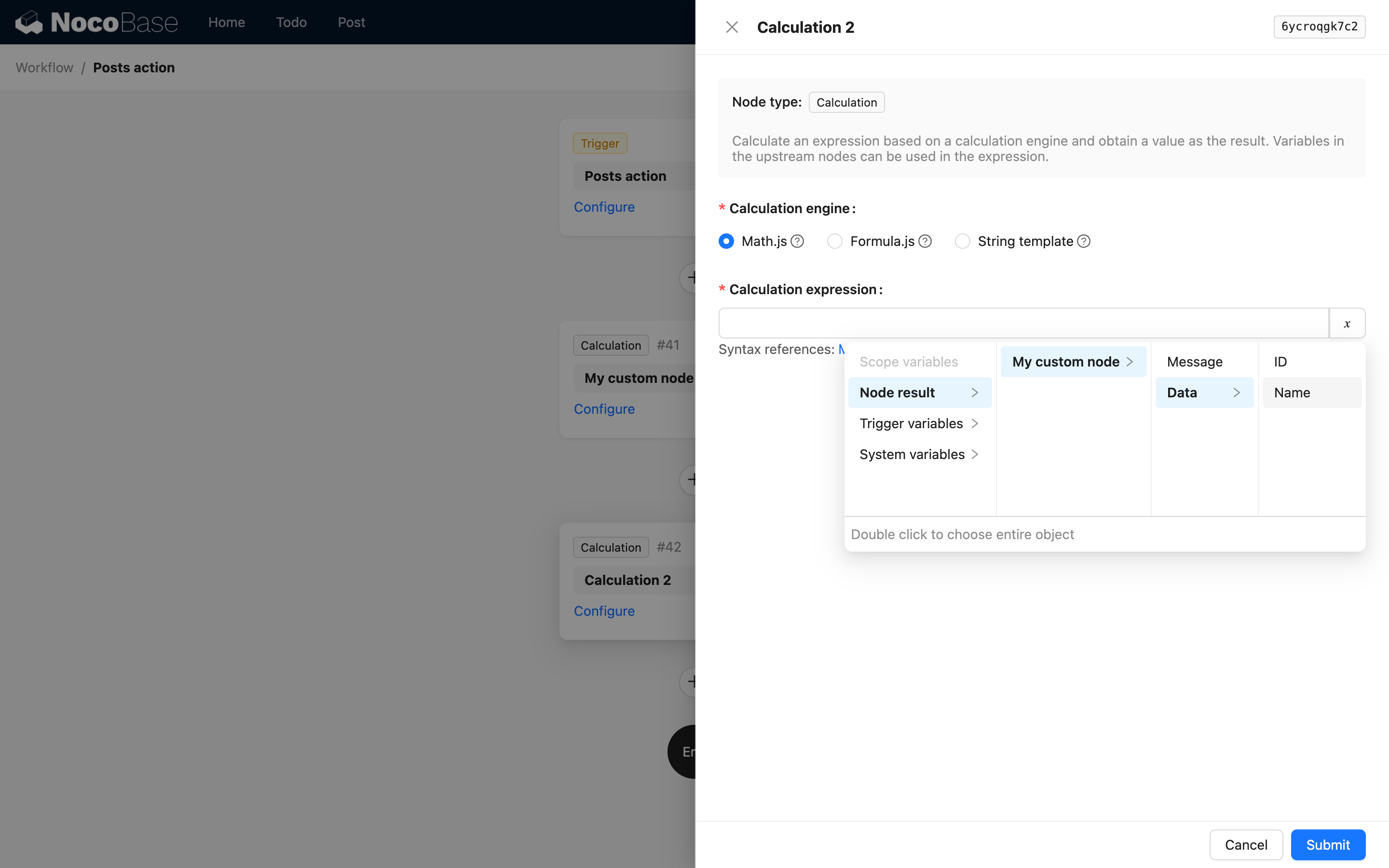
Pokud je struktura ve výsledku polem hluboce vnořených objektů, můžete také použít children k popisu cesty, ale nesmí obsahovat indexy pole. Je to proto, že v NocoBase zpracování proměnných pracovního postupu se popis cesty proměnné pro pole objektů při použití automaticky zploští do pole hlubokých hodnot a nelze přistupovat k určité hodnotě pomocí jejího indexu.
Dostupnost uzlu
Ve výchozím nastavení lze do pracovního postupu přidat libovolný uzel. V některých případech však uzel nemusí být použitelný v určitých typech pracovních postupů nebo větví. V takových situacích můžete konfigurovat dostupnost uzlu pomocí isAvailable:
Metoda isAvailable vrátí true, pokud je uzel dostupný, a false, pokud není. Parametr ctx obsahuje kontextové informace aktuálního uzlu, které lze použít k určení jeho dostupnosti.
Pokud nemáte žádné speciální požadavky, nemusíte metodu isAvailable implementovat, protože uzly jsou ve výchozím nastavení dostupné. Nejčastější situace, kdy je potřeba konfigurace, nastává, když uzel může být časově náročná operace a není vhodný pro provedení v synchronním pracovním postupu. V takovém případě můžete použít metodu isAvailable k omezení použití uzlu. Například:
Další informace
Definice jednotlivých parametrů pro definování typů uzlů naleznete v části Referenční příručka API pracovního postupu.