

Questa documentazione è stata tradotta automaticamente dall'IA.
Estensione dei tipi di nodo
Il tipo di un nodo è essenzialmente un'istruzione operativa. Istruzioni diverse rappresentano operazioni diverse eseguite nel flusso di lavoro.
Similmente ai trigger, l'estensione dei tipi di nodo è divisa in due parti: lato server e lato client. Il lato server deve implementare la logica per l'istruzione registrata, mentre il lato client deve fornire la configurazione dell'interfaccia per i parametri del nodo in cui si trova l'istruzione.
Lato server
L'istruzione nodo più semplice
Il contenuto principale di un'istruzione è una funzione, il che significa che il metodo run nella classe dell'istruzione deve essere implementato per eseguire la logica dell'istruzione. All'interno della funzione è possibile eseguire qualsiasi operazione necessaria, come operazioni su database, operazioni su file, chiamate ad API di terze parti e così via.
Tutte le istruzioni devono derivare dalla classe base Instruction. L'istruzione più semplice richiede solo l'implementazione di una funzione run:
E registrare questa istruzione con il plugin del flusso di lavoro:
Il valore di stato (status) nell'oggetto restituito dall'istruzione è obbligatorio e deve essere un valore della costante JOB_STATUS. Questo valore determina il flusso dell'elaborazione successiva per questo nodo nel flusso di lavoro. Tipicamente, si usa JOB_STATUS.RESOVLED, indicando che il nodo è stato eseguito con successo e l'esecuzione continuerà ai nodi successivi. Se c'è un valore di risultato che deve essere salvato in anticipo, può anche chiamare il metodo processor.saveJob e restituire il suo oggetto di ritorno. L'esecutore genererà un record del risultato dell'esecuzione basato su questo oggetto.
Valore del risultato del nodo
Se c'è un risultato di esecuzione specifico, in particolare dati preparati per l'uso da parte di nodi successivi, può essere restituito tramite la proprietà result e salvato nell'oggetto "job" del nodo:
Qui, node.config è l'elemento di configurazione del nodo, che può essere qualsiasi valore richiesto. Verrà salvato come campo di tipo JSON nel record del nodo corrispondente nel database.
Gestione degli errori dell'istruzione
Se possono verificarsi eccezioni durante l'esecuzione, può catturarle in anticipo e restituire uno stato di fallimento:
Se le eccezioni prevedibili non vengono catturate, il motore del flusso di lavoro le catturerà automaticamente e restituirà uno stato di errore per evitare che eccezioni non catturate causino il crash del programma.
Nodi asincroni
Quando sono necessarie operazioni di controllo del flusso o operazioni I/O asincrone (che richiedono tempo), il metodo run può restituire un oggetto con uno status di JOB_STATUS.PENDING, indicando all'esecutore di attendere (sospendere) fino al completamento di un'operazione asincrona esterna, e quindi notificare al motore del flusso di lavoro di continuare l'esecuzione. Se un valore di stato "in sospeso" viene restituito nella funzione run, l'istruzione deve implementare il metodo resume; altrimenti, l'esecuzione del flusso di lavoro non può essere ripresa:
Qui, paymentService si riferisce a un servizio di pagamento. Nella callback del servizio, il flusso di lavoro viene attivato per riprendere l'esecuzione del "job" corrispondente, e il processo corrente esce per primo. Successivamente, il motore del flusso di lavoro crea un nuovo processore e lo passa al metodo resume del nodo per continuare l'esecuzione del nodo precedentemente sospeso.
L'"operazione asincrona" menzionata qui non si riferisce alle funzioni async in JavaScript, ma piuttosto a operazioni con ritorno non immediato quando si interagisce con altri sistemi esterni, come un servizio di pagamento che deve attendere un'altra notifica per conoscere il risultato.
Stato del risultato del nodo
Lo stato di esecuzione di un nodo influisce sul successo o sul fallimento dell'intero flusso di lavoro. Tipicamente, senza ramificazioni, il fallimento di un nodo causerà direttamente il fallimento dell'intero flusso di lavoro. Lo scenario più comune è che se un nodo viene eseguito con successo, procede al nodo successivo nella tabella dei nodi fino a quando non ci sono più nodi successivi, a quel punto l'intero flusso di lavoro si completa con uno stato di successo.
Se un nodo restituisce uno stato di esecuzione fallito durante l'esecuzione, il motore lo gestirà in modo diverso a seconda delle seguenti due situazioni:
-
Il nodo che restituisce uno stato di fallimento si trova nel flusso di lavoro principale, il che significa che non si trova all'interno di alcun flusso di lavoro ramificato aperto da un nodo a monte. In questo caso, l'intero flusso di lavoro principale viene giudicato fallito e il processo si interrompe.
-
Il nodo che restituisce uno stato di fallimento si trova all'interno di un flusso di lavoro ramificato. In questo caso, la responsabilità di determinare lo stato successivo del flusso di lavoro viene trasferita al nodo che ha aperto la ramificazione. La logica interna di quel nodo deciderà lo stato del flusso di lavoro successivo, e questa decisione si propagherà ricorsivamente fino al flusso di lavoro principale.
In definitiva, lo stato successivo dell'intero flusso di lavoro viene determinato ai nodi del flusso di lavoro principale. Se un nodo nel flusso di lavoro principale restituisce un fallimento, l'intero flusso di lavoro termina con uno stato di fallimento.
Se un nodo restituisce uno stato "in sospeso" dopo l'esecuzione, l'intero processo di esecuzione verrà temporaneamente interrotto e sospeso, in attesa che un evento definito dal nodo corrispondente attivi la ripresa del flusso di lavoro. Ad esempio, il nodo manuale, quando eseguito, si fermerà a quel nodo con uno stato "in sospeso", in attesa di un intervento manuale per decidere se approvare. Se lo stato inserito manualmente è di approvazione, i nodi successivi del flusso di lavoro continueranno; altrimenti, verrà gestito secondo la logica di fallimento descritta in precedenza.
Per ulteriori stati di ritorno delle istruzioni, si prega di fare riferimento alla sezione Riferimento API del flusso di lavoro.
Uscita anticipata
In alcuni flussi di lavoro speciali, potrebbe essere necessario terminare il flusso di lavoro direttamente all'interno di un nodo. Può restituire null per indicare l'uscita dal flusso di lavoro corrente, e i nodi successivi non verranno eseguiti.
Questa situazione è comune nei nodi di controllo del flusso, come il nodo di ramificazione parallela (riferimento al codice), dove il flusso di lavoro del nodo corrente termina, ma nuovi flussi di lavoro vengono avviati per ogni sotto-ramificazione e continuano l'esecuzione.
:::warn{title=Attenzione} La pianificazione di flussi di lavoro ramificati con nodi estesi presenta una certa complessità e richiede un'attenta gestione e test approfonditi. :::
Per saperne di più
Per le definizioni dei vari parametri per la definizione dei tipi di nodo, consulti la sezione Riferimento API del flusso di lavoro.
Lato client
Similmente ai trigger, il modulo di configurazione per un'istruzione (tipo di nodo) deve essere implementato lato client.
L'istruzione nodo più semplice
Tutte le istruzioni devono derivare dalla classe base Instruction. Le proprietà e i metodi correlati vengono utilizzati per configurare e utilizzare il nodo.
Ad esempio, se dobbiamo fornire un'interfaccia di configurazione per il nodo di tipo stringa numerica casuale (randomString) definito lato server sopra, che ha un elemento di configurazione digit che rappresenta il numero di cifre per il numero casuale, useremmo una casella di input numerica nel modulo di configurazione per ricevere l'input dell'utente.
L'identificatore del tipo di nodo registrato lato client deve essere coerente con quello lato server, altrimenti causerà errori.
Fornire i risultati del nodo come variabili
Potrebbe notare il metodo useVariables nell'esempio precedente. Se ha bisogno di utilizzare il risultato del nodo (la parte result) come variabile per i nodi successivi, deve implementare questo metodo nella classe di istruzione ereditata e restituire un oggetto che sia conforme al tipo VariableOption. Questo oggetto serve come descrizione strutturale del risultato dell'esecuzione del nodo, fornendo una mappatura dei nomi delle variabili per la selezione e l'uso nei nodi successivi.
Il tipo VariableOption è definito come segue:
Il nucleo è la proprietà value, che rappresenta il valore del percorso segmentato del nome della variabile. label viene utilizzato per la visualizzazione sull'interfaccia, e children viene utilizzato per rappresentare una struttura di variabili multilivello, che si usa quando il risultato del nodo è un oggetto annidato in profondità.
Una variabile utilizzabile è rappresentata internamente nel sistema come una stringa template di percorso separata da ., ad esempio, {{jobsMapByNodeKey.2dw92cdf.abc}}. Qui, jobsMapByNodeKey rappresenta l'insieme dei risultati di tutti i nodi (definito internamente, non è necessario gestirlo), 2dw92cdf è la key del nodo, e abc è una proprietà personalizzata nell'oggetto risultato del nodo.
Inoltre, poiché il risultato di un nodo può anche essere un valore semplice, quando si forniscono variabili di nodo, il primo livello deve essere la descrizione del nodo stesso:
Cioè, il primo livello è la key e il titolo del nodo. Ad esempio, nel riferimento al codice del nodo di calcolo, quando si utilizza il risultato del nodo di calcolo, le opzioni dell'interfaccia sono le seguenti:
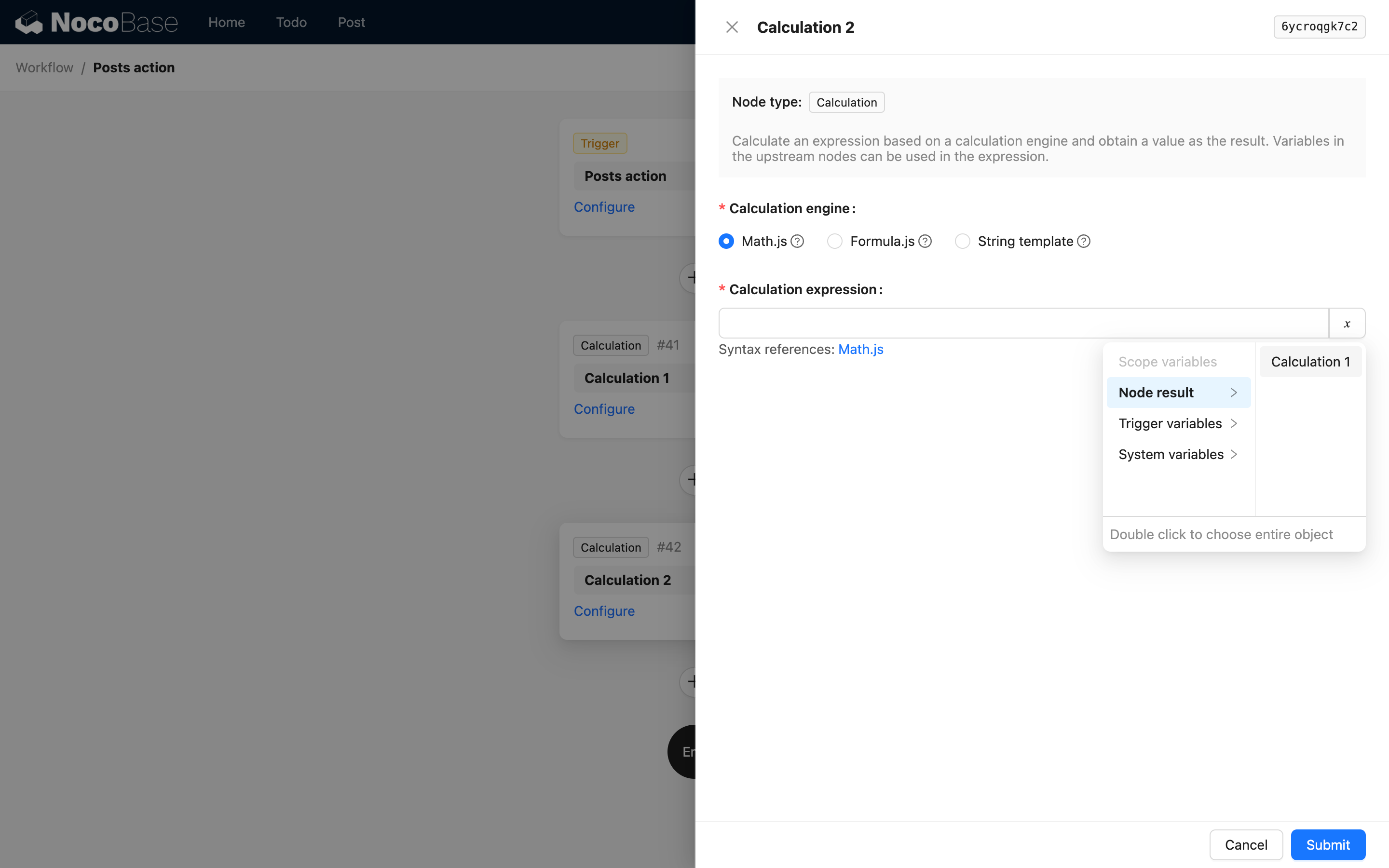
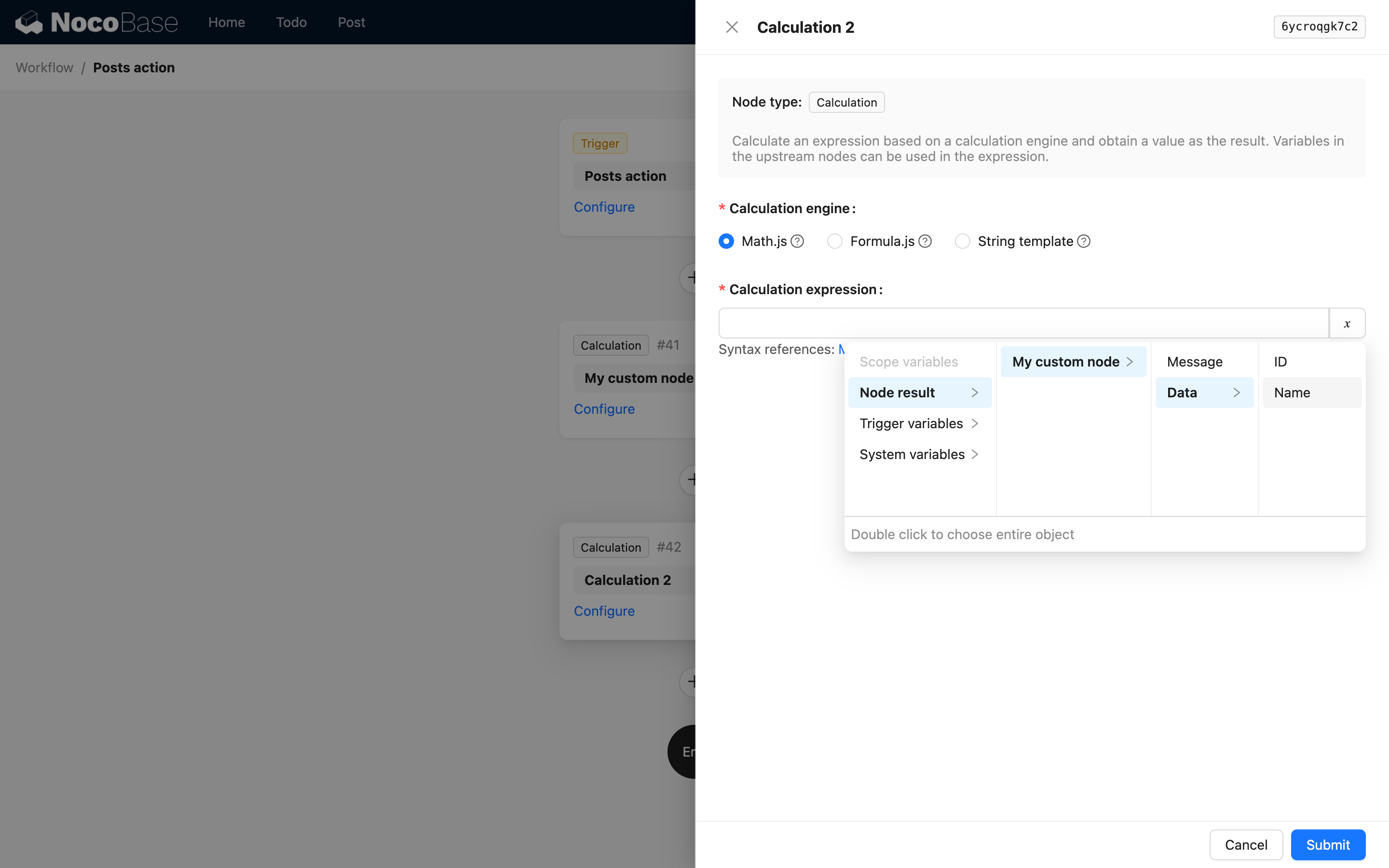
Quando il risultato del nodo è un oggetto complesso, può utilizzare children per continuare a descrivere le proprietà annidate. Ad esempio, un'istruzione personalizzata potrebbe restituire i seguenti dati JSON:
Quindi può restituirlo tramite il metodo useVariables come segue:
In questo modo, nei nodi successivi, può utilizzare la seguente interfaccia per selezionare le variabili da esso:
Quando una struttura nel risultato è un array di oggetti annidati in profondità, può anche utilizzare children per descrivere il percorso, ma non può includere indici di array. Questo perché nella gestione delle variabili del flusso di lavoro di NocoBase, la descrizione del percorso della variabile per un array di oggetti viene automaticamente appiattita in un array di valori profondi quando utilizzata, e non è possibile accedere a un valore specifico tramite il suo indice.
Disponibilità del nodo
Per impostazione predefinita, qualsiasi nodo può essere aggiunto a un flusso di lavoro. Tuttavia, in alcuni casi, un nodo potrebbe non essere applicabile in determinati tipi di flussi di lavoro o ramificazioni. In tali situazioni, può configurare la disponibilità del nodo utilizzando isAvailable:
Il metodo isAvailable restituisce true se il nodo è disponibile, e false se non lo è. Il parametro ctx contiene le informazioni di contesto del nodo corrente, che possono essere utilizzate per determinarne la disponibilità.
Se non ci sono requisiti speciali, non è necessario implementare il metodo isAvailable, poiché i nodi sono disponibili per impostazione predefinita. Lo scenario più comune che richiede configurazione è quando un nodo potrebbe essere un'operazione che richiede molto tempo e non è adatta per l'esecuzione in un flusso di lavoro sincrono. Può utilizzare il metodo isAvailable per limitarne l'uso. Ad esempio:
Per saperne di più
Per le definizioni dei vari parametri per la definizione dei tipi di nodo, consulti la sezione Riferimento API del flusso di lavoro.