

Ten dokument został przetłumaczony przez AI. W przypadku niedokładności, proszę odnieść się do wersji angielskiej
Rozszerzanie typów węzłów
Typ węzła to w zasadzie instrukcja operacyjna. Różne instrukcje reprezentują różne operacje wykonywane w ramach przepływu pracy.
Podobnie jak w przypadku wyzwalaczy, rozszerzanie typów węzłów dzieli się na dwie części: po stronie serwera i po stronie klienta. Strona serwera odpowiada za implementację logiki zarejestrowanej instrukcji, natomiast strona klienta musi zapewnić konfigurację interfejsu dla parametrów węzła, w którym znajduje się instrukcja.
Strona serwera
Najprostsza instrukcja węzła
Rdzeniem instrukcji jest funkcja, co oznacza, że metoda run w klasie instrukcji musi być zaimplementowana w celu wykonania logiki instrukcji. W funkcji można wykonywać dowolne niezbędne operacje, takie jak operacje na bazie danych, operacje na plikach, wywoływanie zewnętrznych API itp.
Wszystkie instrukcje muszą dziedziczyć z klasy bazowej Instruction. Najprostsza instrukcja wymaga jedynie zaimplementowania funkcji run:
I zarejestrować tę instrukcję w wtyczce przepływu pracy:
Wartość statusu (status) w obiekcie zwracanym przez instrukcję jest obowiązkowa i musi pochodzić ze stałej JOB_STATUS. Wartość ta decyduje o dalszym przebiegu przetwarzania tego węzła w przepływie pracy. Zazwyczaj używa się JOB_STATUS.RESOVLED, co oznacza, że węzeł został wykonany pomyślnie, a wykonanie będzie kontynuowane do kolejnych węzłów. Jeśli istnieje wartość wynikowa, którą należy zapisać z wyprzedzeniem, można również wywołać metodę processor.saveJob i zwrócić jej obiekt wynikowy. Wykonawca wygeneruje rekord wyniku wykonania na podstawie tego obiektu.
Wartość wynikowa węzła
Jeśli istnieje konkretny wynik wykonania, zwłaszcza dane przygotowane do użycia przez kolejne węzły, można go zwrócić za pomocą właściwości result i zapisać w obiekcie zadania węzła:
Tutaj node.config to element konfiguracji węzła, który może przyjmować dowolną wymaganą wartość. Zostanie on zapisany jako pole typu JSON w odpowiadającym rekordzie węzła w bazie danych.
Obsługa błędów instrukcji
Jeśli podczas wykonywania mogą wystąpić wyjątki, można je wcześniej przechwycić i zwrócić status błędu:
Jeśli przewidywalne wyjątki nie zostaną przechwycone, silnik przepływu pracy automatycznie je przechwyci i zwróci status błędu, aby zapobiec awarii programu z powodu nieprzechwyconych wyjątków.
Węzły asynchroniczne
Gdy potrzebna jest kontrola przepływu lub asynchroniczne (czasochłonne) operacje wejścia/wyjścia, metoda run może zwrócić obiekt ze statusem JOB_STATUS.PENDING, co spowoduje, że wykonawca będzie czekał (zawiesi się) do momentu zakończenia zewnętrznej operacji asynchronicznej, a następnie powiadomi silnik przepływu pracy o kontynuowaniu wykonywania. Jeśli w funkcji run zostanie zwrócona wartość statusu oczekującego, instrukcja musi zaimplementować metodę resume; w przeciwnym razie wykonanie przepływu pracy nie będzie mogło zostać wznowione:
Tutaj paymentService odnosi się do usługi płatniczej. W funkcji zwrotnej usługi wyzwalany jest przepływ pracy w celu wznowienia wykonania odpowiedniego zadania, a bieżący proces najpierw się kończy. Następnie silnik przepływu pracy tworzy nowy procesor i przekazuje go do metody resume węzła, aby kontynuować wykonywanie wcześniej zawieszonego węzła.
Wspomniana tutaj „operacja asynchroniczna” nie odnosi się do funkcji async w JavaScript, lecz do operacji, które nie zwracają wyniku natychmiastowo podczas interakcji z innymi systemami zewnętrznymi, np. usługa płatnicza, która musi czekać na inne powiadomienie, aby poznać wynik.
Status wyniku węzła
Status wykonania węzła wpływa na sukces lub porażkę całego przepływu pracy. Zazwyczaj, bez rozgałęzień, awaria jednego węzła bezpośrednio spowoduje awarię całego przepływu pracy. Najczęstszy scenariusz to taki, w którym węzeł wykonuje się pomyślnie, przechodzi do następnego węzła w tabeli węzłów, aż do momentu, gdy nie ma już kolejnych węzłów, po czym cały przepływ pracy kończy się ze statusem sukcesu.
Jeśli węzeł zwróci status niepowodzenia podczas wykonywania, silnik obsłuży to inaczej w zależności od dwóch poniższych sytuacji:
-
Węzeł, który zwraca status niepowodzenia, znajduje się w głównym przepływie pracy, co oznacza, że nie jest częścią żadnego rozgałęzionego przepływu pracy otwartego przez węzeł nadrzędny. W takim przypadku cały główny przepływ pracy zostaje uznany za nieudany, a proces zostaje zakończony.
-
Węzeł, który zwraca status niepowodzenia, znajduje się w rozgałęzionym przepływie pracy. W takim przypadku odpowiedzialność za określenie następnego stanu przepływu pracy zostaje przekazana węzłowi, który otworzył rozgałęzienie. Wewnętrzna logika tego węzła zdecyduje o stanie kolejnego przepływu pracy, a ta decyzja będzie rekurencyjnie propagowana w górę do głównego przepływu pracy.
Ostatecznie, następny stan całego przepływu pracy jest określany na węzłach głównego przepływu pracy. Jeśli węzeł w głównym przepływie pracy zwróci błąd, cały przepływ pracy kończy się statusem niepowodzenia.
Jeśli jakikolwiek węzeł zwróci status „oczekujący” po wykonaniu, cały proces wykonania zostanie tymczasowo przerwany i zawieszony, czekając na zdarzenie zdefiniowane przez odpowiedni węzeł, które wywoła wznowienie przepływu pracy. Na przykład, węzeł ręczny, po wykonaniu, zatrzyma się w tym węźle ze statusem „oczekujący”, czekając na ręczną interwencję w celu podjęcia decyzji o zatwierdzeniu. Jeśli ręcznie wprowadzony status to zatwierdzenie, kolejne węzły przepływu pracy będą kontynuowane; w przeciwnym razie zostanie to obsłużone zgodnie z wcześniej opisaną logiką niepowodzenia.
Więcej informacji na temat statusów zwracanych przez instrukcje znajdą Państwo w sekcji Referencje API przepływu pracy.
Wczesne zakończenie
W niektórych specjalnych przepływach pracy może być konieczne bezpośrednie zakończenie przepływu pracy w obrębie węzła. Mogą Państwo zwrócić null, aby wskazać zakończenie bieżącego przepływu pracy, a kolejne węzły nie zostaną wykonane.
Taka sytuacja jest powszechna w węzłach typu kontroli przepływu, takich jak węzeł rozgałęzienia równoległego (referencja kodu), gdzie przepływ pracy bieżącego węzła kończy się, ale dla każdej podgałęzi uruchamiane są nowe przepływy pracy, które kontynuują wykonywanie.
:::warn{title=Ostrzeżenie} Planowanie rozgałęzionych przepływów pracy za pomocą rozszerzonych węzłów wiąże się z pewną złożonością i wymaga ostrożnego postępowania oraz dokładnych testów. :::
Dowiedz się więcej
Definicje różnych parametrów do definiowania typów węzłów znajdą Państwo w sekcji Referencje API przepływu pracy.
Strona klienta
Podobnie jak w przypadku wyzwalaczy, formularz konfiguracji dla instrukcji (typu węzła) musi być zaimplementowany po stronie klienta.
Najprostsza instrukcja węzła
Wszystkie instrukcje muszą dziedziczyć z klasy bazowej Instruction. Powiązane właściwości i metody służą do konfigurowania i używania węzła.
Na przykład, jeśli chcemy zapewnić interfejs konfiguracji dla węzła typu ciągu losowych liczb (randomString) zdefiniowanego wcześniej po stronie serwera, który posiada element konfiguracji digit reprezentujący liczbę cyfr dla liczby losowej, użyjemy pola wprowadzania liczby w formularzu konfiguracji do odbierania danych od użytkownika.
Identyfikator typu węzła zarejestrowany po stronie klienta musi być zgodny z identyfikatorem po stronie serwera, w przeciwnym razie spowoduje to błędy.
Udostępnianie wyników węzła jako zmiennych
Mogą Państwo zauważyć metodę useVariables w powyższym przykładzie. Jeśli chcą Państwo użyć wyniku węzła (części result) jako zmiennej dla kolejnych węzłów, należy zaimplementować tę metodę w dziedziczącej klasie instrukcji i zwrócić obiekt zgodny z typem VariableOption. Obiekt ten służy jako strukturalny opis wyniku wykonania węzła, zapewniając mapowanie nazw zmiennych do wyboru i użycia w kolejnych węzłach.
Typ VariableOption jest zdefiniowany w następujący sposób:
Kluczowa jest właściwość value, która reprezentuje segmentową wartość ścieżki nazwy zmiennej. label służy do wyświetlania w interfejsie, a children do reprezentowania wielopoziomowej struktury zmiennych, co jest używane, gdy wynik węzła jest głęboko zagnieżdżonym obiektem.
Użyteczna zmienna jest wewnętrznie reprezentowana w systemie jako ciąg szablonu ścieżki oddzielony kropkami, na przykład {{jobsMapByNodeKey.2dw92cdf.abc}}. Tutaj jobsMapByNodeKey reprezentuje zbiór wyników wszystkich węzłów (zdefiniowany wewnętrznie, nie wymaga obsługi), 2dw92cdf to key węzła, a abc to niestandardowa właściwość w obiekcie wyniku węzła.
Dodatkowo, ponieważ wynik węzła może być również prostą wartością, podczas udostępniania zmiennych węzła, pierwszy poziom musi być opisem samego węzła:
To znaczy, pierwszy poziom to key i tytuł węzła. Na przykład, w referencji kodu węzła obliczeniowego, podczas używania wyniku węzła obliczeniowego, opcje interfejsu są następujące:
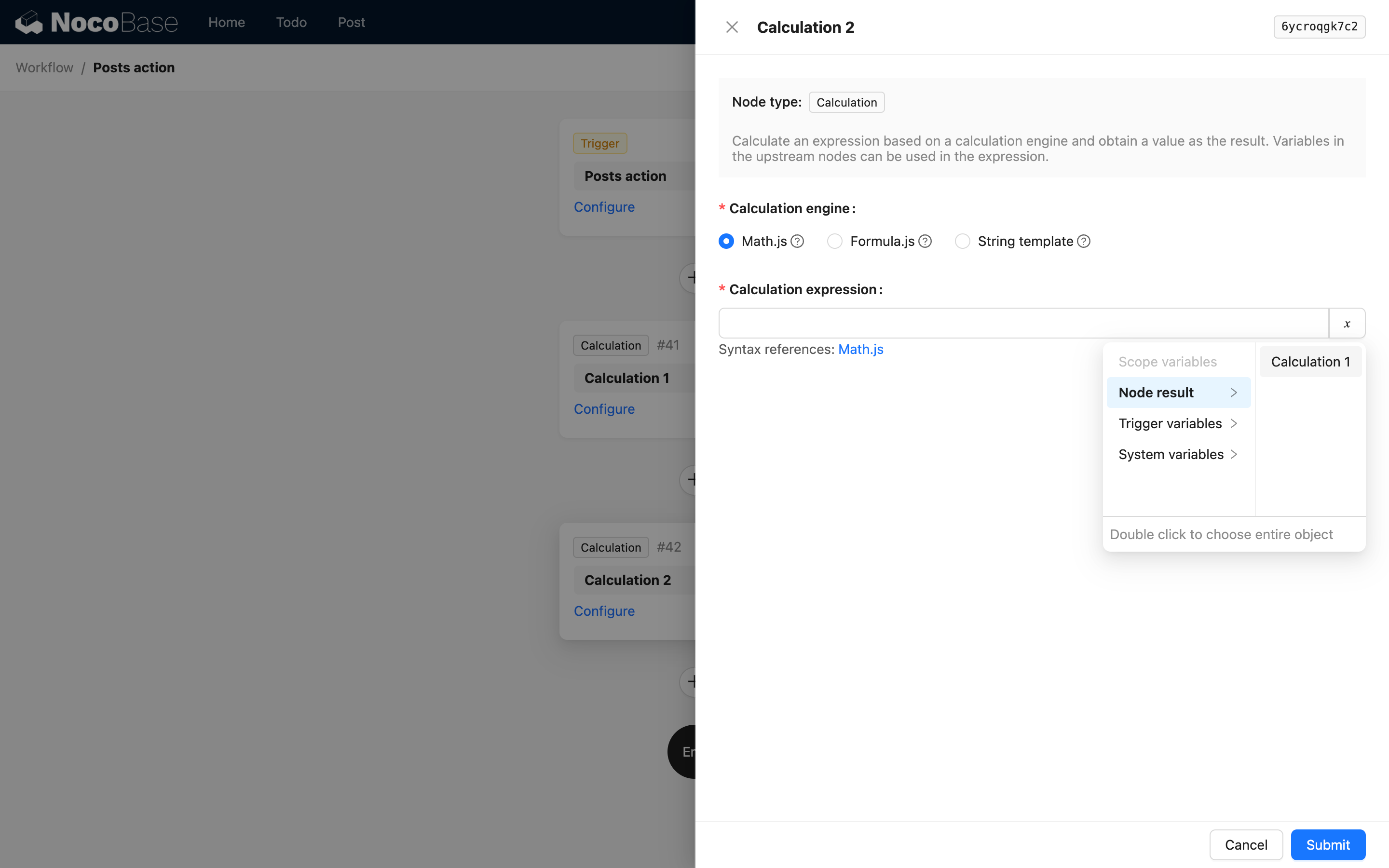
Gdy wynik węzła jest złożonym obiektem, można użyć children do dalszego opisywania zagnieżdżonych właściwości. Na przykład, niestandardowa instrukcja może zwrócić następujące dane JSON:
Wówczas można to zwrócić za pomocą metody useVariables w następujący sposób:
W ten sposób, w kolejnych węzłach, można użyć następującego interfejsu do wyboru zmiennych z niego:
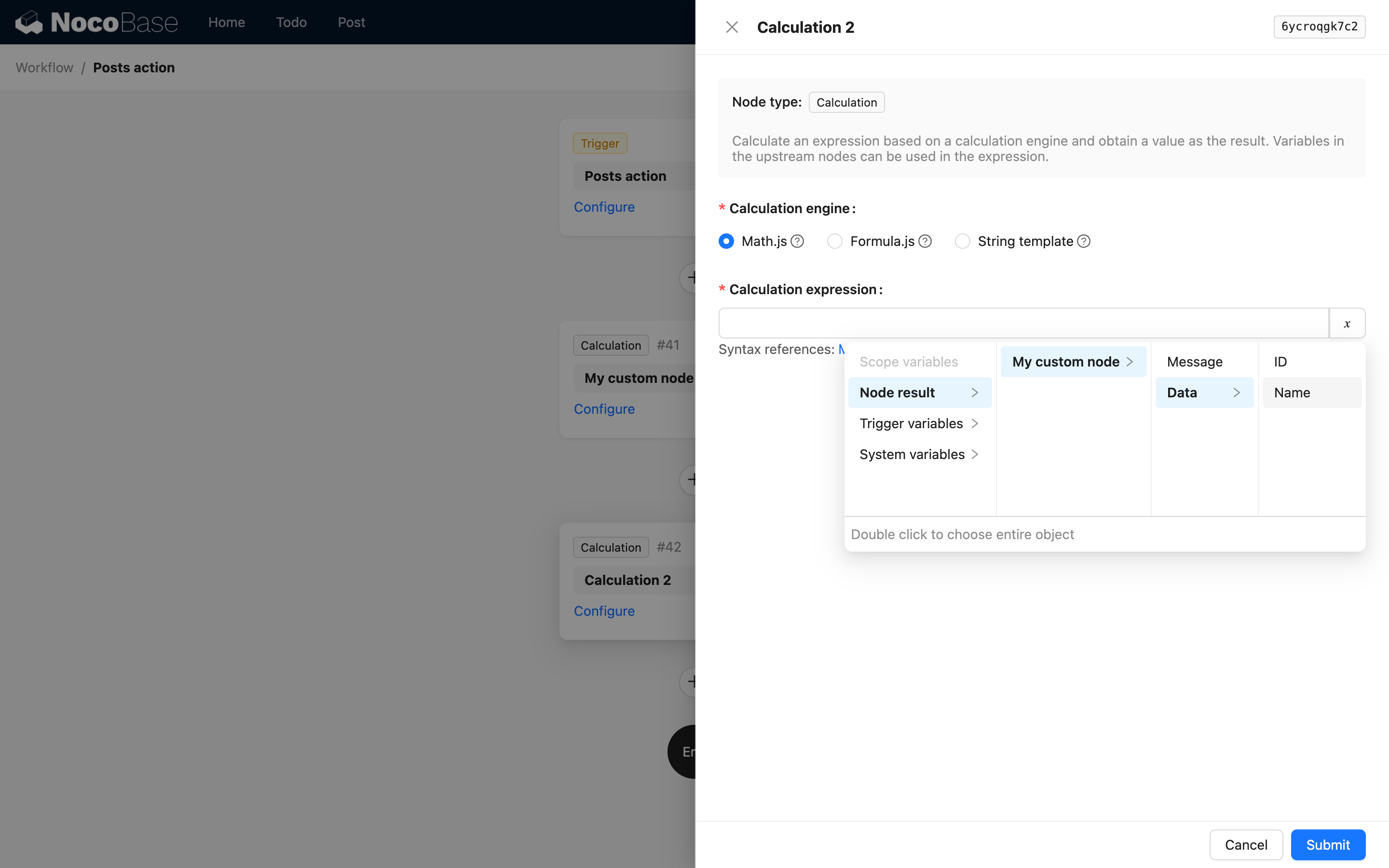
Gdy struktura w wyniku jest tablicą głęboko zagnieżdżonych obiektów, można również użyć children do opisania ścieżki, ale nie może ona zawierać indeksów tablicy. Dzieje się tak, ponieważ w obsłudze zmiennych w przepływie pracy NocoBase, opis ścieżki zmiennej dla tablicy obiektów jest automatycznie spłaszczany do tablicy głębokich wartości podczas użycia, i nie można uzyskać dostępu do konkretnej wartości za pomocą jej indeksu.
Dostępność węzła
Domyślnie, każdy węzeł może zostać dodany do przepływu pracy. Jednak w niektórych przypadkach węzeł może nie być odpowiedni w określonych typach przepływów pracy lub rozgałęzień. W takich sytuacjach można skonfigurować dostępność węzła za pomocą isAvailable:
Metoda isAvailable zwraca true, jeśli węzeł jest dostępny, i false, jeśli nie jest. Parametr ctx zawiera informacje kontekstowe bieżącego węzła, które można wykorzystać do określenia jego dostępności.
Jeśli nie ma specjalnych wymagań, nie trzeba implementować metody isAvailable, ponieważ węzły są domyślnie dostępne. Najczęstszy scenariusz wymagający konfiguracji to sytuacja, gdy węzeł może być operacją czasochłonną i nie nadaje się do wykonania w synchronicznym przepływie pracy. Mogą Państwo użyć metody isAvailable, aby ograniczyć jego użycie. Na przykład:
Dowiedz się więcej
Definicje różnych parametrów do definiowania typów węzłów znajdą Państwo w sekcji Referencje API przepływu pracy.