Tento dokument byl přeložen umělou inteligencí. V případě nepřesností se prosím obraťte na anglickou verzi
JSON Výpočet
Pracovní postup: JSON výpočetCommunity Edition+Úvod
Na základě různých JSON výpočetních enginů tento uzel počítá nebo transformuje komplexní JSON data generovaná předchozími uzly, aby je mohly využít následné uzly. Například výsledky SQL operací a uzlů HTTP požadavků lze pomocí tohoto uzlu transformovat do požadovaných hodnot a formátů proměnných pro další zpracování.
Vytvoření uzlu
V rozhraní konfigurace pracovního postupu klikněte na tlačítko plus („+“) v procesu a přidejte uzel „JSON Výpočet“:
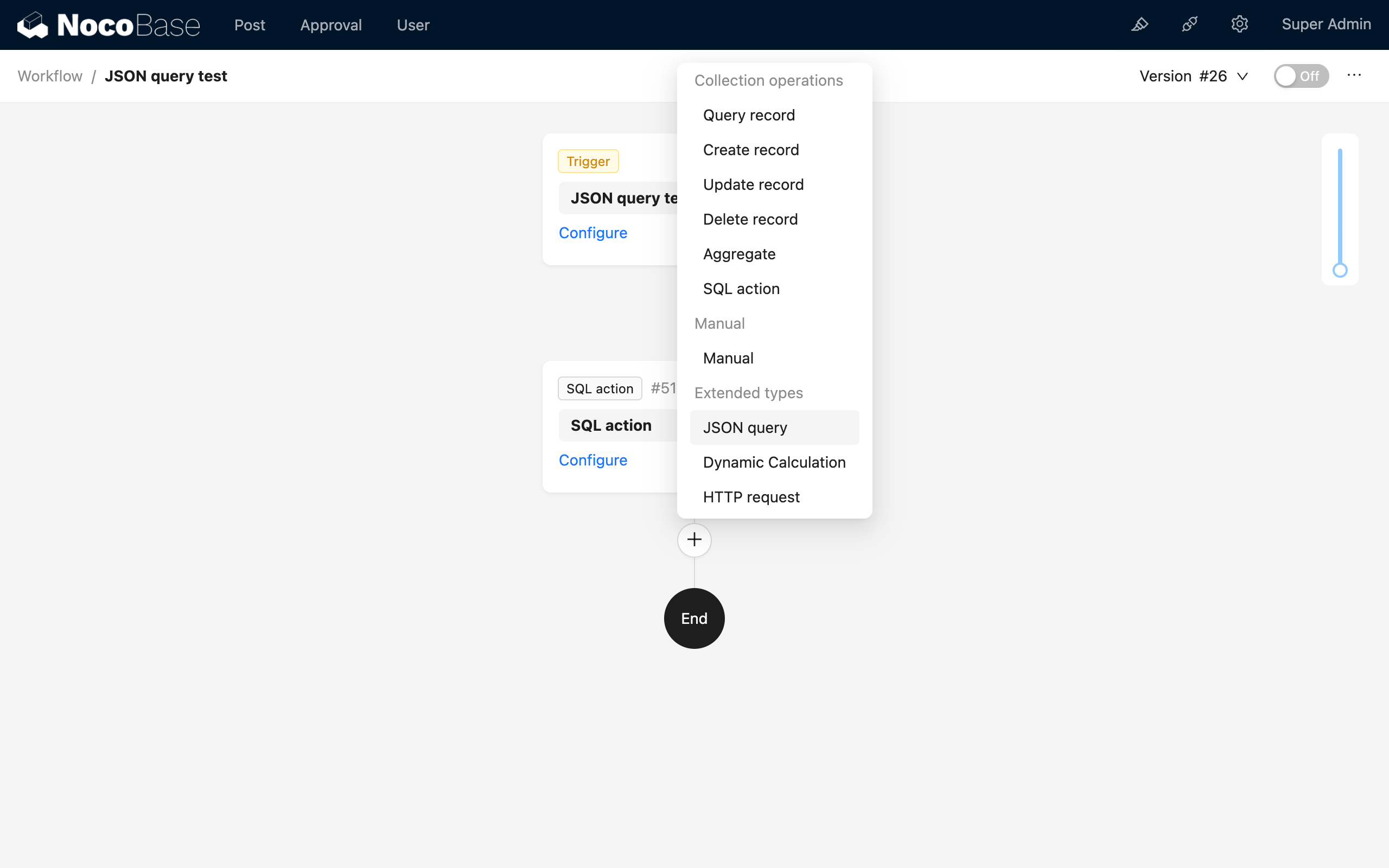
Uzel JSON Výpočet se obvykle vytváří pod jinými datovými uzly, aby je bylo možné analyzovat.
Konfigurace uzlu
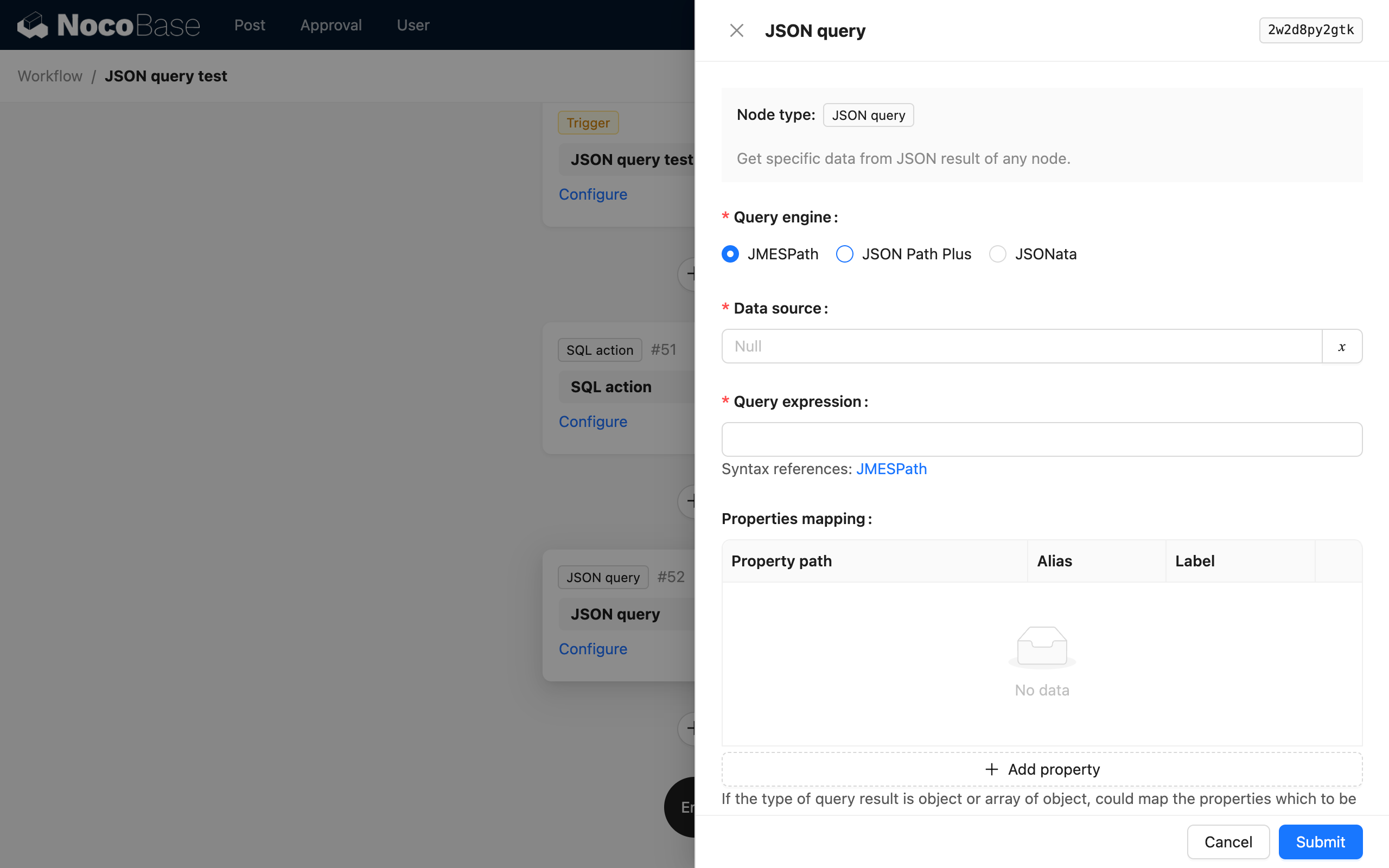
Parsovací engine
Uzel JSON Výpočet podporuje různé syntaxe prostřednictvím různých parsovacích enginů. Můžete si vybrat na základě svých preferencí a funkcí jednotlivých enginů. V současné době jsou podporovány tři parsovací enginy:
Zdroj dat
Zdroj dat může být výsledek předchozího uzlu nebo datový objekt v kontextu pracovního postupu. Obvykle se jedná o datový objekt bez vestavěné struktury, například výsledek SQL uzlu nebo uzlu HTTP požadavku.
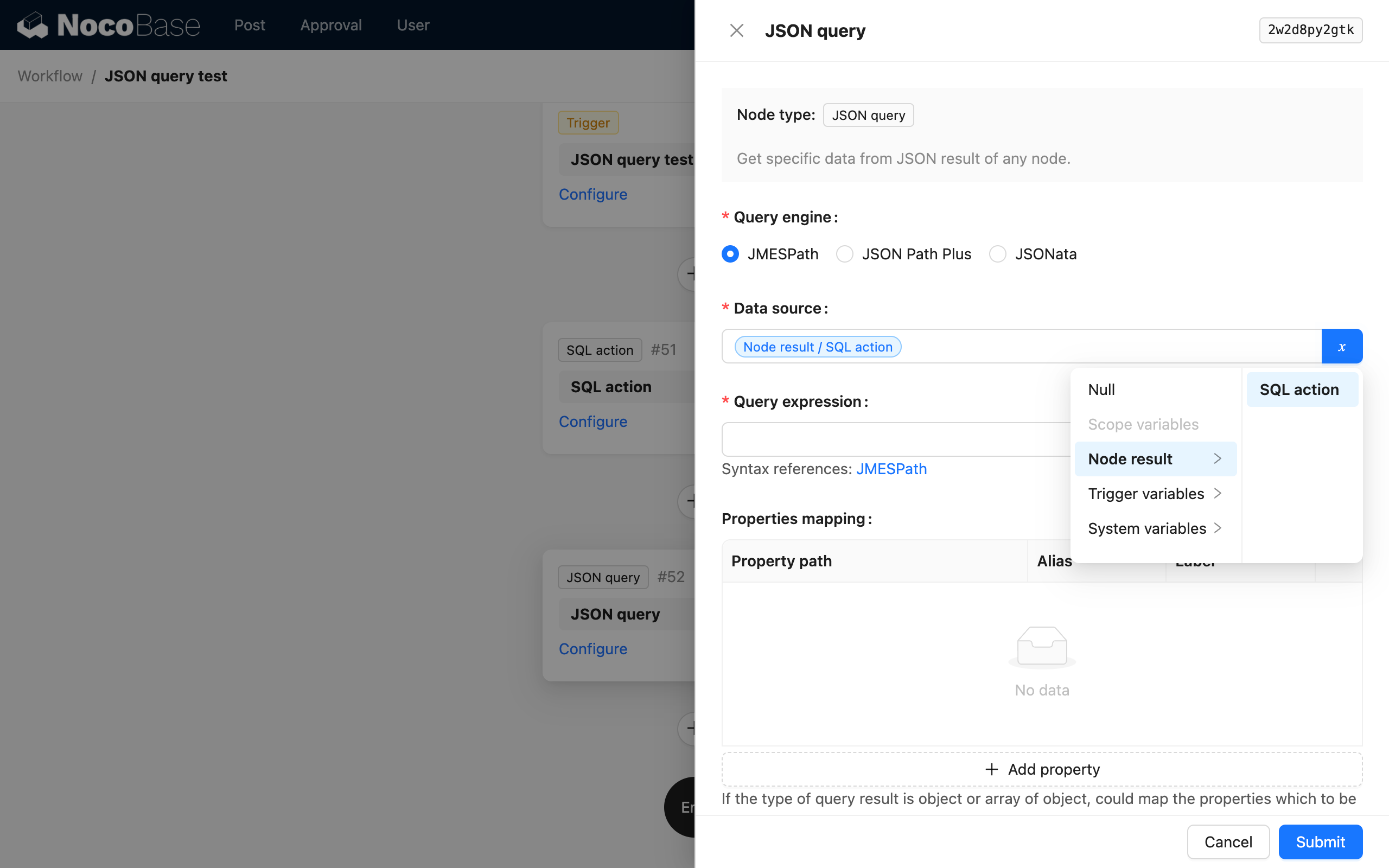
Datové objekty uzlů souvisejících s kolekcemi jsou obvykle strukturovány pomocí konfiguračních informací kolekce a obecně není nutné je parsovat uzlem JSON Výpočet.
Parsovací výraz
Vlastní parsovací výrazy na základě požadavků na parsování a zvoleného parsovacího enginu.
Různé enginy poskytují různé parsovací syntaxe. Podrobnosti naleznete v dokumentaci na odkazech.
Od verze v1.0.0-alpha.15 výrazy podporují proměnné. Proměnné jsou před spuštěním konkrétního enginu předparsovány, přičemž se nahradí konkrétními řetězcovými hodnotami podle pravidel řetězcových šablon a spojí se s ostatními statickými řetězci ve výrazu, čímž se vytvoří konečný výraz. Tato funkce je velmi užitečná, když potřebujete dynamicky vytvářet výrazy, například když některý JSON obsah vyžaduje dynamický klíč pro parsování.
Mapování vlastností
Když je výsledek výpočtu objekt (nebo pole objektů), můžete pomocí mapování vlastností dále mapovat požadované vlastnosti na podřízené proměnné pro použití následnými uzly.
Pro výsledek objektu (nebo pole objektů), pokud není provedeno mapování vlastností, bude celý objekt (nebo pole objektů) uložen jako jedna proměnná ve výsledku uzlu a hodnoty vlastností objektu nelze přímo použít jako proměnné.
Příklad
Předpokládejme, že data k parsování pocházejí z předchozího SQL uzlu, který sloužil k dotazování dat, a jehož výsledkem je sada dat objednávek:
Pokud potřebujeme analyzovat a vypočítat celkovou cenu dvou objednávek v datech a sestavit ji s odpovídajícím ID objednávky do objektu pro aktualizaci celkové ceny objednávky, můžeme ji nakonfigurovat následovně:
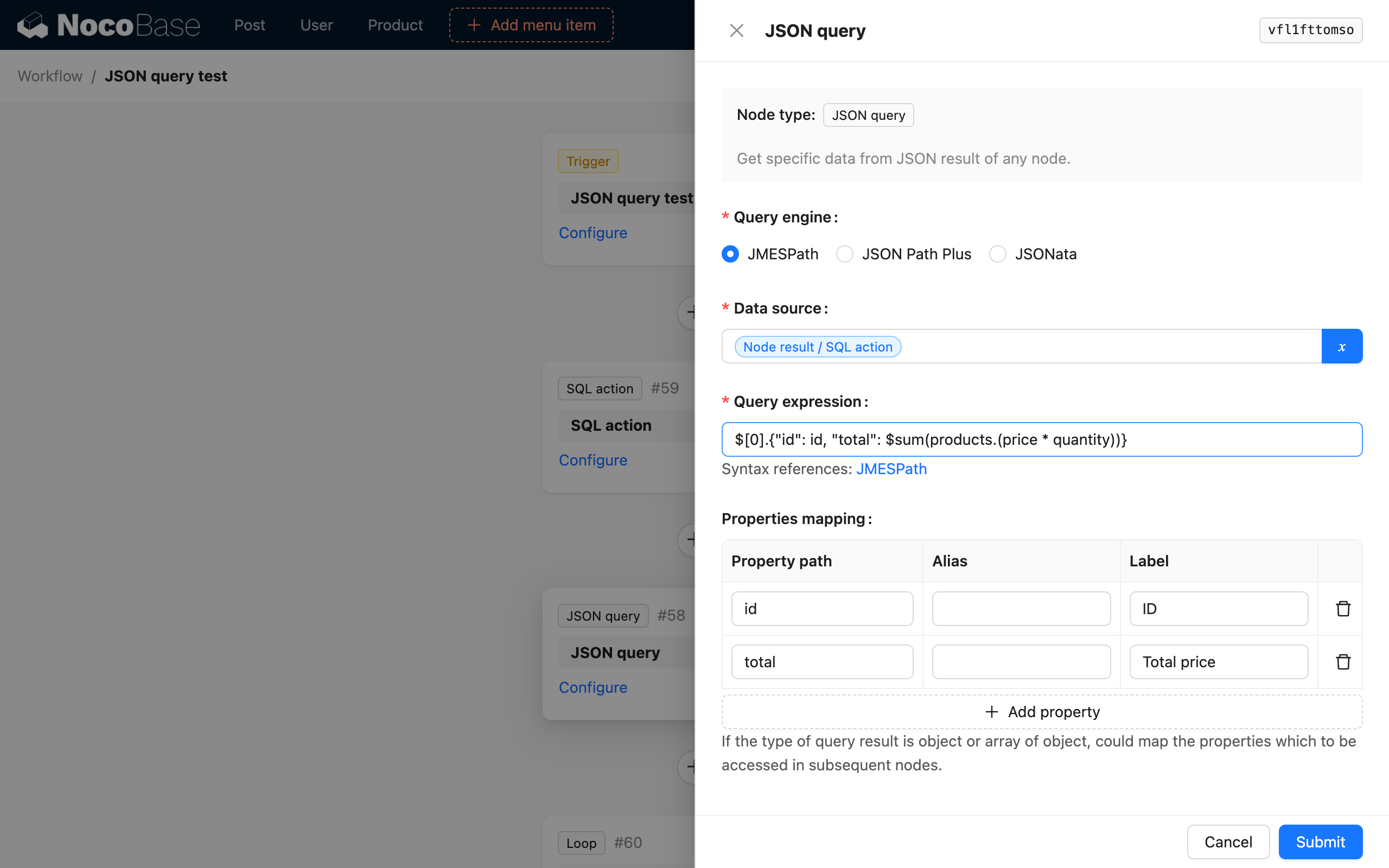
- Vyberte parsovací engine JSONata;
- Vyberte výsledek SQL uzlu jako zdroj dat;
- Použijte JSONata výraz
$[0].{"id": id, "total": products.(price * quantity)}pro parsování; - Vyberte mapování vlastností pro mapování
idatotalna podřízené proměnné;
Konečný výsledek parsování je následující:
Poté projděte výsledné pole objednávek a aktualizujte celkovou cenu objednávek.