

Esta documentación ha sido traducida automáticamente por IA.
Extensión de tipos de nodo
El tipo de un nodo es, en esencia, una instrucción operativa. Diferentes instrucciones representan distintas operaciones que se ejecutan en el flujo de trabajo.
De forma similar a los disparadores (triggers), la extensión de los tipos de nodo se divide en dos partes: el lado del servidor y el lado del cliente. El lado del servidor debe implementar la lógica para la instrucción registrada, mientras que el lado del cliente necesita proporcionar la configuración de la interfaz para los parámetros del nodo donde se encuentra la instrucción.
Lado del servidor
La instrucción de nodo más sencilla
El contenido principal de una instrucción es una función, lo que significa que el método run en la clase de la instrucción debe implementarse para ejecutar su lógica. Dentro de esta función, puede realizar cualquier operación necesaria, como operaciones de base de datos, operaciones de archivos, llamadas a APIs de terceros, etc.
Todas las instrucciones deben derivar de la clase base Instruction. La instrucción más sencilla solo necesita implementar una función run:
Y registre esta instrucción en el plugin de flujo de trabajo:
El valor de estado (status) en el objeto de retorno de la instrucción es obligatorio y debe ser uno de los valores de la constante JOB_STATUS. Este valor determinará el flujo del procesamiento posterior para este nodo en el flujo de trabajo. Normalmente, se utiliza JOB_STATUS.RESOVLED, lo que indica que el nodo se ha ejecutado correctamente y la ejecución continuará con los siguientes nodos. Si necesita guardar un valor de resultado de antemano, también puede llamar al método processor.saveJob y devolver su objeto de retorno. El ejecutor generará un registro de resultado de ejecución basado en este objeto.
Valor de resultado del nodo
Si hay un resultado de ejecución específico, especialmente datos preparados para ser utilizados por nodos posteriores, puede devolverlo a través de la propiedad result y guardarlo en el objeto de tarea del nodo:
Aquí, node.config es el elemento de configuración del nodo, que puede ser cualquier valor requerido. Se guardará como un campo de tipo JSON en el registro del nodo correspondiente en la base de datos.
Manejo de errores de la instrucción
Si pueden ocurrir excepciones durante la ejecución, puede capturarlas de antemano y devolver un estado de fallo:
Si no se capturan las excepciones predecibles, el motor del flujo de trabajo las capturará automáticamente y devolverá un estado de error para evitar que las excepciones no capturadas bloqueen el programa.
Nodos asíncronos
Cuando se necesita control de flujo de trabajo u operaciones de E/S asíncronas (que consumen tiempo), el método run puede devolver un objeto con un status de JOB_STATUS.PENDING, lo que indica al ejecutor que espere (suspenda) hasta que se complete alguna operación asíncrona externa, y luego notifique al motor del flujo de trabajo para que continúe la ejecución. Si se devuelve un valor de estado pendiente en la función run, la instrucción debe implementar el método resume; de lo contrario, la ejecución del flujo de trabajo no podrá reanudarse:
Aquí, paymentService se refiere a un servicio de pago. En la devolución de llamada (callback) del servicio, se activa el flujo de trabajo para reanudar la ejecución de la tarea correspondiente, y el proceso actual finaliza primero. Posteriormente, el motor del flujo de trabajo crea un nuevo procesador y lo pasa al método resume del nodo para continuar ejecutando el nodo que había sido suspendido previamente.
La "operación asíncrona" mencionada aquí no se refiere a las funciones async en JavaScript, sino a operaciones que no devuelven un resultado instantáneo al interactuar con otros sistemas externos, como un servicio de pago que necesita esperar otra notificación para conocer el resultado.
Estado del resultado del nodo
El estado de ejecución de un nodo afecta el éxito o el fracaso de todo el flujo de trabajo. Normalmente, sin ramificaciones, el fallo de un nodo provocará directamente el fallo de todo el flujo de trabajo. El escenario más común es que, si un nodo se ejecuta correctamente, se procede al siguiente nodo en la tabla de nodos hasta que no haya más nodos posteriores, momento en el que la ejecución completa del flujo de trabajo finaliza con un estado de éxito.
Si un nodo devuelve un estado de ejecución fallido durante su proceso, el motor lo manejará de manera diferente según las siguientes dos situaciones:
-
Si el nodo que devuelve un estado de fallo se encuentra en el flujo de trabajo principal, es decir, no está dentro de ninguna ramificación iniciada por un nodo anterior, entonces todo el flujo de trabajo principal se considerará fallido y el proceso finalizará.
-
Si el nodo que devuelve un estado de fallo se encuentra dentro de una ramificación del flujo de trabajo, la responsabilidad de determinar el siguiente estado del proceso se transfiere al nodo que inició esa ramificación. La lógica interna de dicho nodo decidirá el estado del flujo de trabajo subsiguiente, y esta decisión se propagará recursivamente hasta el flujo de trabajo principal.
Finalmente, el siguiente estado de todo el flujo de trabajo se determina en los nodos del flujo de trabajo principal. Si un nodo en el flujo de trabajo principal devuelve un fallo, todo el flujo de trabajo termina con un estado de fallo.
Si algún nodo devuelve un estado de "pendiente" después de su ejecución, todo el proceso de ejecución se interrumpirá y suspenderá temporalmente, esperando que un evento definido por el nodo correspondiente active la reanudación del flujo de trabajo. Por ejemplo, un nodo manual, al ejecutarse, se pausará en ese nodo con un estado de "pendiente", esperando la intervención humana para decidir si se aprueba. Si el estado introducido manualmente es de aprobación, los nodos posteriores del flujo de trabajo continuarán; de lo contrario, se manejará según la lógica de fallo descrita anteriormente.
Para obtener más información sobre los estados de retorno de las instrucciones, consulte la sección de Referencia de la API de Flujo de trabajo.
Salida anticipada
En algunos flujos de trabajo especiales, puede ser necesario finalizar el proceso directamente dentro de un nodo. Puede devolver null para indicar que se sale del flujo de trabajo actual y que los nodos posteriores no se ejecutarán.
Esta situación es común en nodos de tipo control de flujo de trabajo, como el Nodo de Ramificación Paralela (código de referencia), donde el flujo de trabajo del nodo actual finaliza, pero se inician nuevos flujos de trabajo para cada sub-ramificación y continúan ejecutándose.
:::warn{title=Advertencia} La programación de flujos de trabajo de ramificación con nodos extendidos tiene cierta complejidad y requiere un manejo cuidadoso y pruebas exhaustivas. :::
Más información
Las definiciones de los diversos parámetros para definir tipos de nodo se encuentran en la sección de Referencia de la API de Flujo de trabajo.
Lado del cliente
De forma similar a los disparadores, el formulario de configuración para una instrucción (tipo de nodo) debe implementarse en el lado del cliente.
La instrucción de nodo más sencilla
Todas las instrucciones deben derivar de la clase base Instruction. Las propiedades y métodos relacionados se utilizan para la configuración y el uso del nodo.
Por ejemplo, si necesitamos proporcionar una interfaz de configuración para el nodo de tipo cadena de número aleatorio (randomString) definido anteriormente en el lado del servidor, que tiene un elemento de configuración digit que representa el número de dígitos para el número aleatorio, usaríamos un campo de entrada numérica en el formulario de configuración para recibir la entrada del usuario.
El identificador del tipo de nodo registrado en el lado del cliente debe ser coherente con el del lado del servidor; de lo contrario, se producirán errores.
Proporcionar resultados del nodo como variables
Puede observar el método useVariables en el ejemplo anterior. Si necesita utilizar el resultado del nodo (la parte result) como una variable para nodos posteriores, debe implementar este método en la clase de instrucción heredada y devolver un objeto que cumpla con el tipo VariableOption. Este objeto sirve como una descripción estructural del resultado de la ejecución del nodo, proporcionando un mapeo de nombres de variables para su selección y uso en nodos posteriores.
El tipo VariableOption se define de la siguiente manera:
El núcleo es la propiedad value, que representa el valor de la ruta segmentada del nombre de la variable. label se utiliza para mostrar en la interfaz, y children se usa para representar una estructura de variable multinivel, lo cual es útil cuando el resultado del nodo es un objeto anidado.
Una variable utilizable se representa internamente en el sistema como una cadena de plantilla de ruta separada por ., por ejemplo, {{jobsMapByNodeKey.2dw92cdf.abc}}. Aquí, jobsMapByNodeKey representa el conjunto de resultados de todos los nodos (definido internamente, no necesita ser manejado), 2dw92cdf es la key del nodo, y abc es una propiedad personalizada en el objeto de resultado del nodo.
Además, dado que el resultado de un nodo también puede ser un valor simple, al proporcionar variables de nodo, el primer nivel debe ser la descripción del propio nodo:
Es decir, el primer nivel es la key y el título del nodo. Por ejemplo, en el código de referencia del nodo de cálculo, al usar el resultado de este nodo, las opciones de la interfaz son las siguientes:
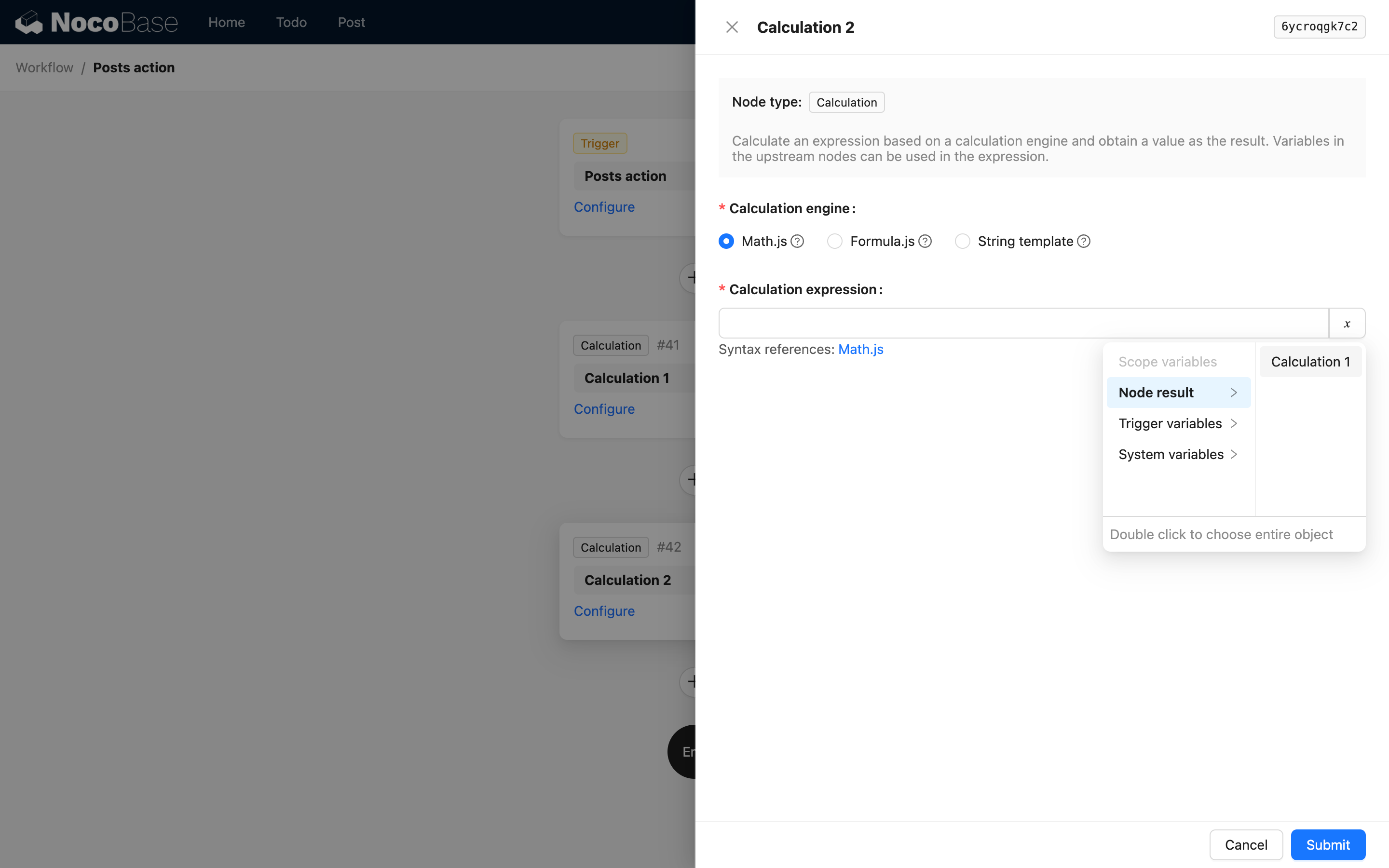
Cuando el resultado del nodo es un objeto complejo, puede usar children para seguir describiendo propiedades anidadas. Por ejemplo, una instrucción personalizada podría devolver los siguientes datos JSON:
Entonces puede devolverlo a través del método useVariables de la siguiente manera:
De esta manera, en los nodos posteriores, podrá usar la siguiente interfaz para seleccionar las variables:
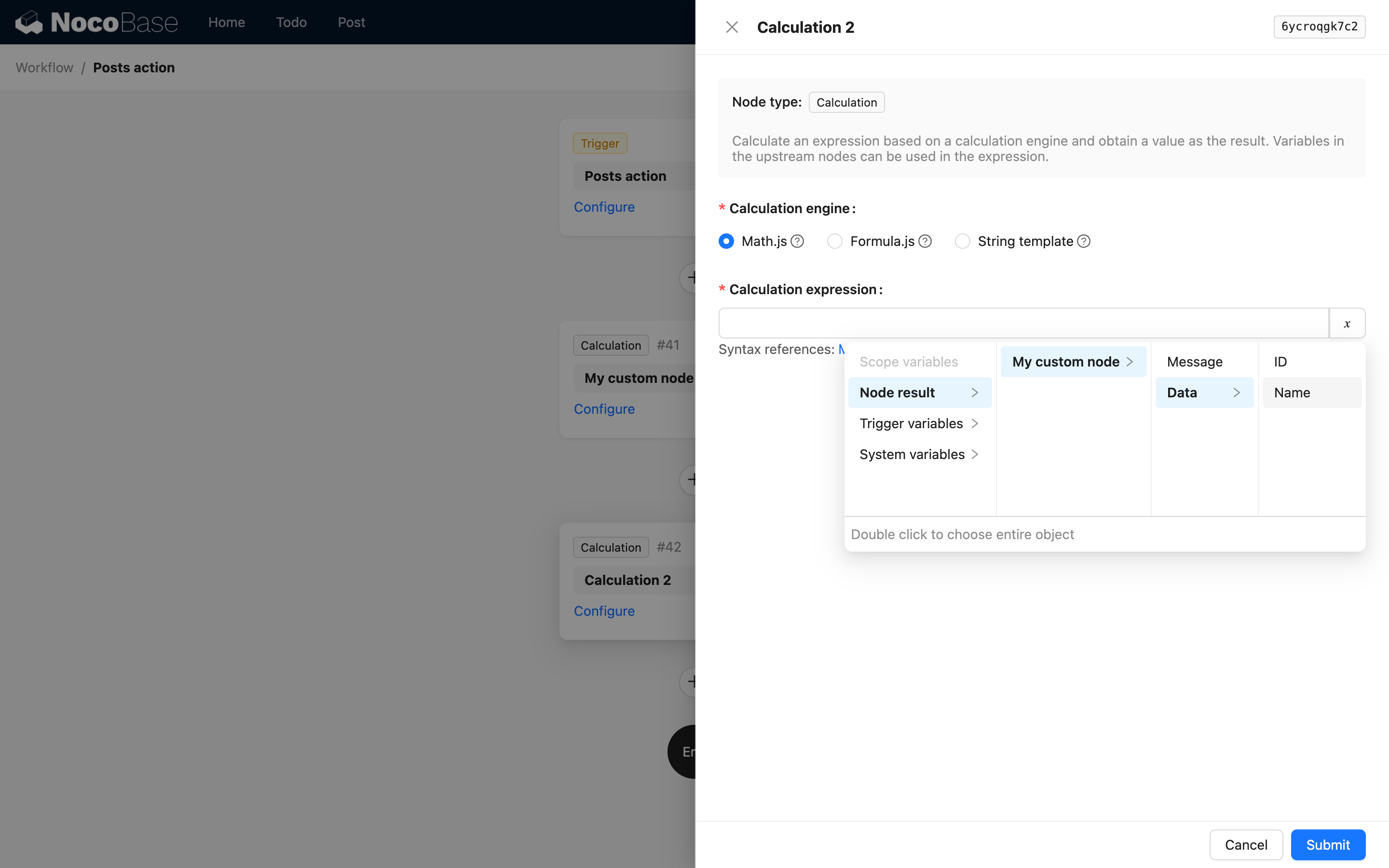
Cuando una estructura en el resultado es un array de objetos anidados, también puede usar children para describir la ruta, pero no puede incluir índices de array. Esto se debe a que, en el manejo de variables del flujo de trabajo de NocoBase, la descripción de la ruta de una variable para un array de objetos se aplana automáticamente en un array de valores anidados cuando se usa, y no se puede acceder a un valor específico por su índice.
Disponibilidad del nodo
Por defecto, se puede añadir cualquier nodo a un flujo de trabajo. Sin embargo, en algunos casos, un nodo puede no ser aplicable en ciertos tipos de flujos de trabajo o ramificaciones. En estas situaciones, puede configurar la disponibilidad del nodo utilizando isAvailable:
El método isAvailable devuelve true si el nodo está disponible y false si no lo está. El parámetro ctx contiene la información de contexto del nodo actual, que puede utilizar para determinar si el nodo está disponible.
Si no tiene requisitos especiales, no necesita implementar el método isAvailable, ya que los nodos están disponibles por defecto. El escenario más común que requiere configuración es cuando un nodo podría ser una operación que consume mucho tiempo y no es adecuado para ejecutarse en un flujo de trabajo síncrono. Puede usar el método isAvailable para restringir su uso. Por ejemplo:
Más información
Las definiciones de los diversos parámetros para definir tipos de nodo se encuentran en la sección de Referencia de la API de Flujo de trabajo.