Esta documentación ha sido traducida automáticamente por IA.
Uso de variables
Conceptos clave
Al igual que las variables en un lenguaje de programación, las variables en un flujo de trabajo son una herramienta fundamental para conectar y organizar procesos.
Cuando se ejecuta cada nodo después de que se activa un flujo de trabajo, algunas configuraciones pueden usar variables. El origen de estas variables es la información de los nodos anteriores (o "upstream") al nodo actual, e incluyen las siguientes categorías:
- Datos del contexto del disparador: En situaciones como disparadores de acciones o de colección, un objeto de datos de una sola fila puede ser utilizado como variable por todos los nodos. Los detalles específicos varían según la implementación de cada disparador.
- Datos de nodos anteriores: Cuando el proceso llega a cualquier nodo, se refiere a los datos resultantes de los nodos que ya se completaron.
- Variables locales: Cuando un nodo se encuentra dentro de estructuras de ramificación especiales, puede usar variables locales específicas de esa rama. Por ejemplo, en una estructura de bucle, se puede usar el objeto de datos de cada iteración.
- Variables del sistema: Algunos parámetros del sistema incorporados, como la hora actual.
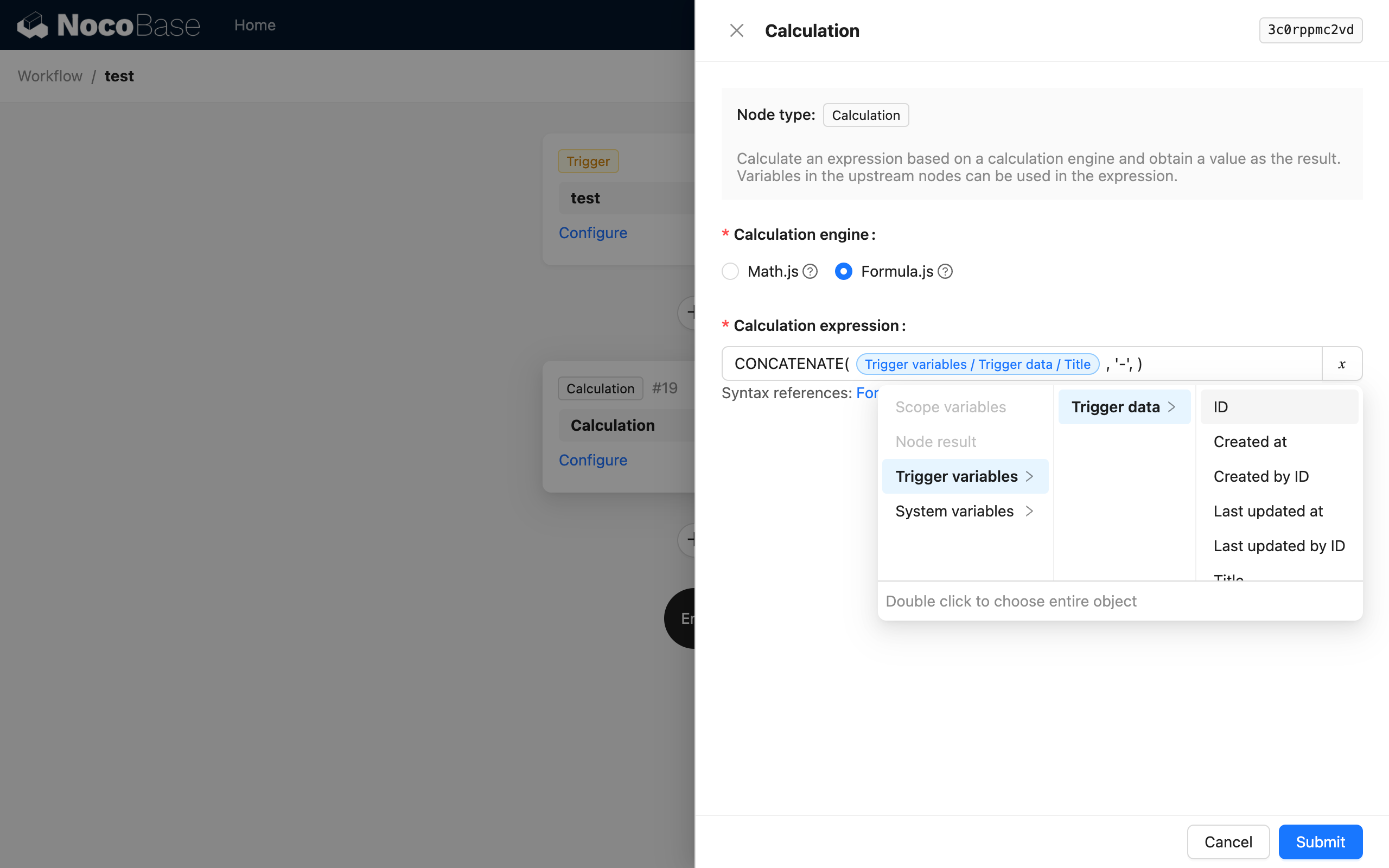
Ya hemos utilizado la función de variables varias veces en Inicio rápido. Por ejemplo, en un nodo de cálculo, podemos usar variables para referenciar datos del contexto del disparador y realizar operaciones:
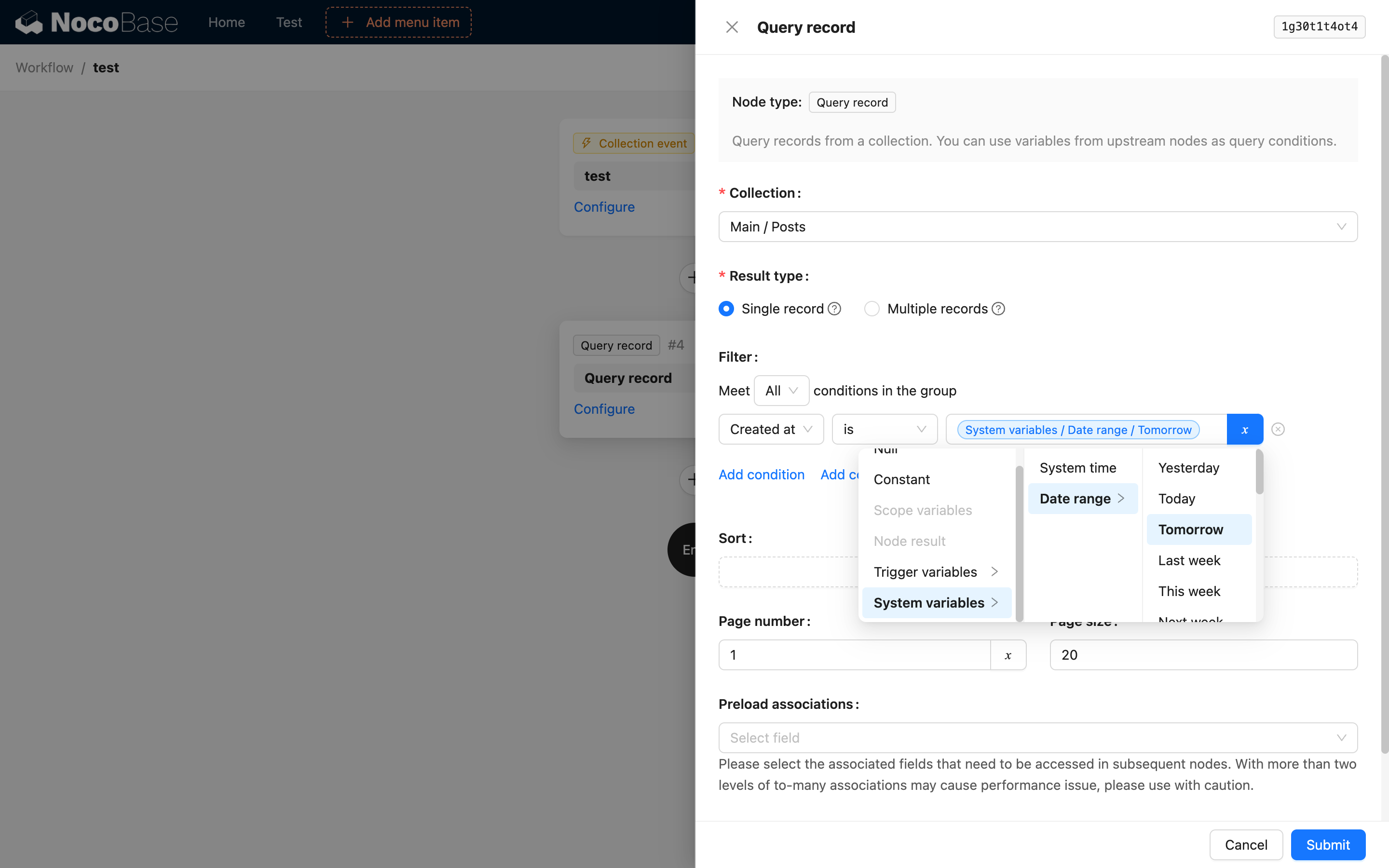
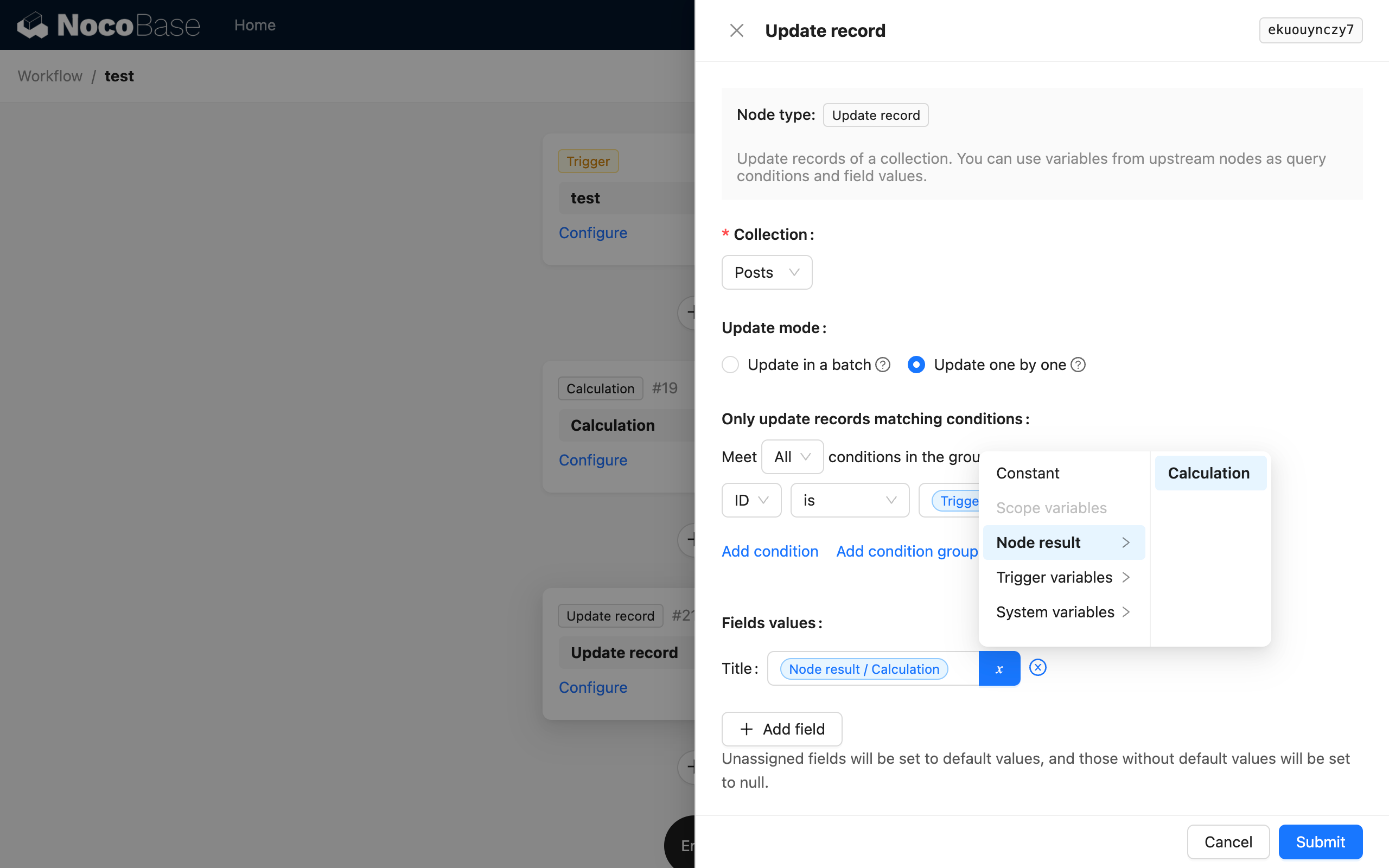
En un nodo de actualización, use los datos del contexto del disparador como variable para la condición de filtro, y referencie el resultado del nodo de cálculo como variable para el valor del campo a actualizar:
Estructura de datos
Internamente, una variable es una estructura JSON, y normalmente puede usar una parte específica de los datos mediante su ruta JSON. Dado que muchas variables se basan en la estructura de colección de NocoBase, los datos de asociación se estructurarán jerárquicamente como propiedades de objetos, formando una estructura similar a un árbol. Por ejemplo, podemos seleccionar el valor de un campo específico de los datos de asociación de la información consultada. Además, cuando los datos de asociación tienen una estructura de "uno a muchos", la variable puede ser un array.
Al seleccionar una variable, la mayoría de las veces necesitará elegir el atributo de valor del último nivel, que suele ser un tipo de dato simple como un número o una cadena de texto. Sin embargo, cuando hay un array en la jerarquía de la variable, el atributo del último nivel también se mapeará a un array. Solo si el nodo correspondiente admite arrays, se podrán procesar los datos del array correctamente. Por ejemplo, en un nodo de cálculo, algunos motores de cálculo tienen funciones específicas para manejar arrays. Otro ejemplo es en un nodo de bucle, donde el objeto de bucle también puede ser un array directamente.
Por ejemplo, cuando un nodo de consulta busca múltiples datos, el resultado del nodo será un array que contiene varias filas de datos homogéneos:
Sin embargo, al usarlo como variable en nodos posteriores, si la variable seleccionada tiene la forma Datos del nodo/Nodo de consulta/Título, obtendrá un array mapeado a los valores de los campos correspondientes:
Si se trata de un array multidimensional (como un campo de relación de "muchos a muchos"), obtendrá un array unidimensional con el campo correspondiente aplanado.
Variables del sistema integradas
Hora del sistema
Obtiene la hora del sistema en el momento en que se ejecuta el nodo. La zona horaria de esta hora es la configurada en el servidor.
Parámetros de rango de fechas
Se puede usar al configurar condiciones de filtro de campos de fecha en nodos de consulta, actualización y eliminación. Solo se admite para comparaciones de "igual a". Tanto la hora de inicio como la de finalización del rango de fechas se basan en la zona horaria configurada en el servidor.