Questa documentazione è stata tradotta automaticamente dall'IA.
Utilizzo delle variabili
Concetti chiave
Proprio come le variabili in un linguaggio di programmazione, le variabili in un flusso di lavoro sono uno strumento importante per connettere e organizzare i processi.
Quando ogni nodo viene eseguito dopo l'attivazione di un flusso di lavoro, alcune opzioni di configurazione possono utilizzare le variabili. La fonte di queste variabili è il dato proveniente dai nodi a monte del nodo corrente, e include le seguenti categorie:
- Dati di contesto del trigger: In casi come i trigger di azione o i trigger di collezione, un singolo oggetto dato può essere utilizzato come variabile da tutti i nodi. Le specifiche variano a seconda dell'implementazione di ciascun trigger.
- Dati dei nodi a monte: Quando il processo raggiunge un qualsiasi nodo, si tratta dei dati risultanti dai nodi precedentemente completati.
- Variabili locali: Quando un nodo si trova all'interno di particolari strutture a ramo, può utilizzare variabili locali specifiche di quel ramo. Ad esempio, in una struttura a ciclo, è possibile utilizzare l'oggetto dato di ogni iterazione.
- Variabili di sistema: Alcuni parametri di sistema integrati, come l'ora corrente.
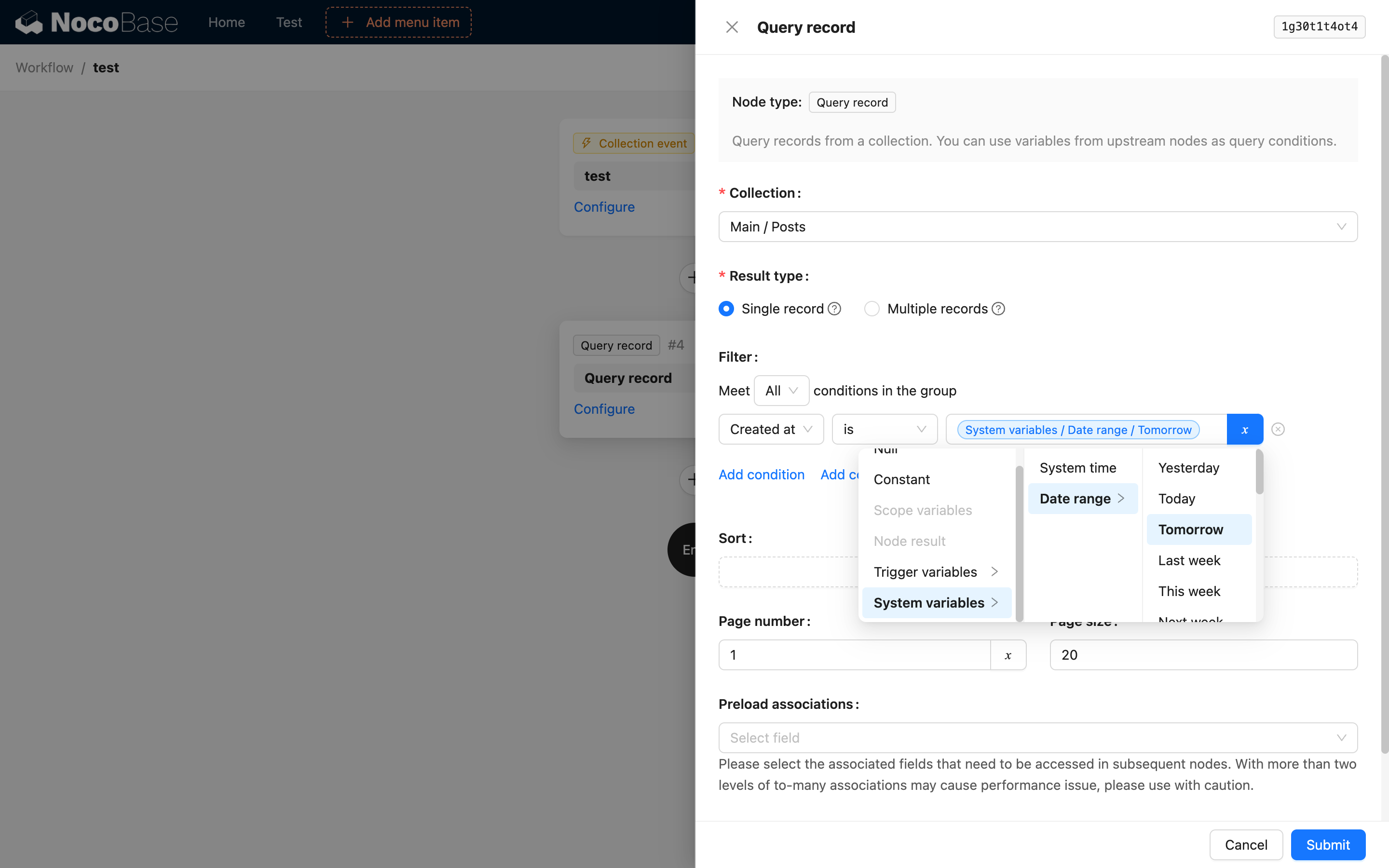
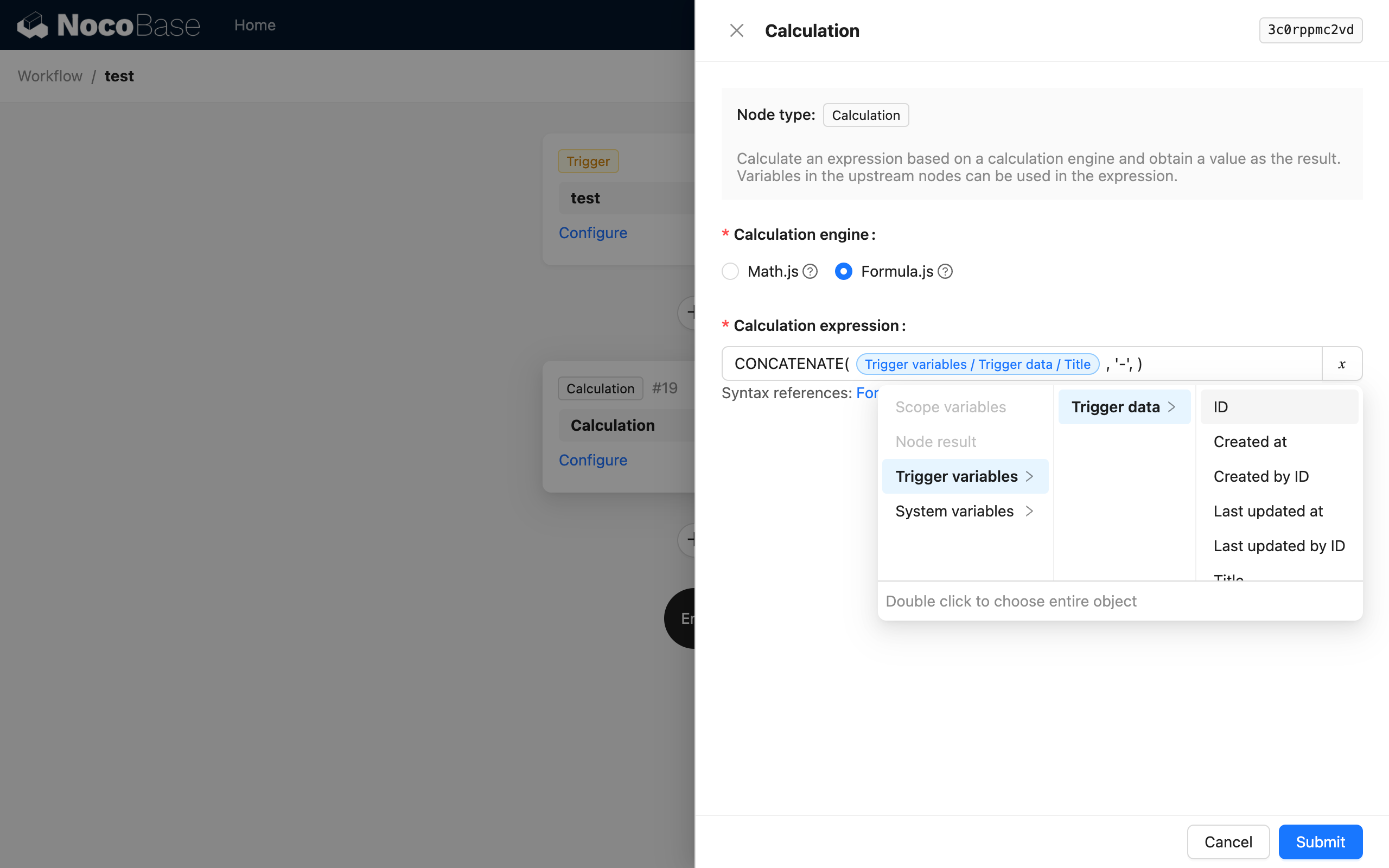
Abbiamo già utilizzato più volte la funzionalità delle variabili in Guida rapida. Ad esempio, in un nodo di calcolo, possiamo usare le variabili per fare riferimento ai dati di contesto del trigger per eseguire calcoli:
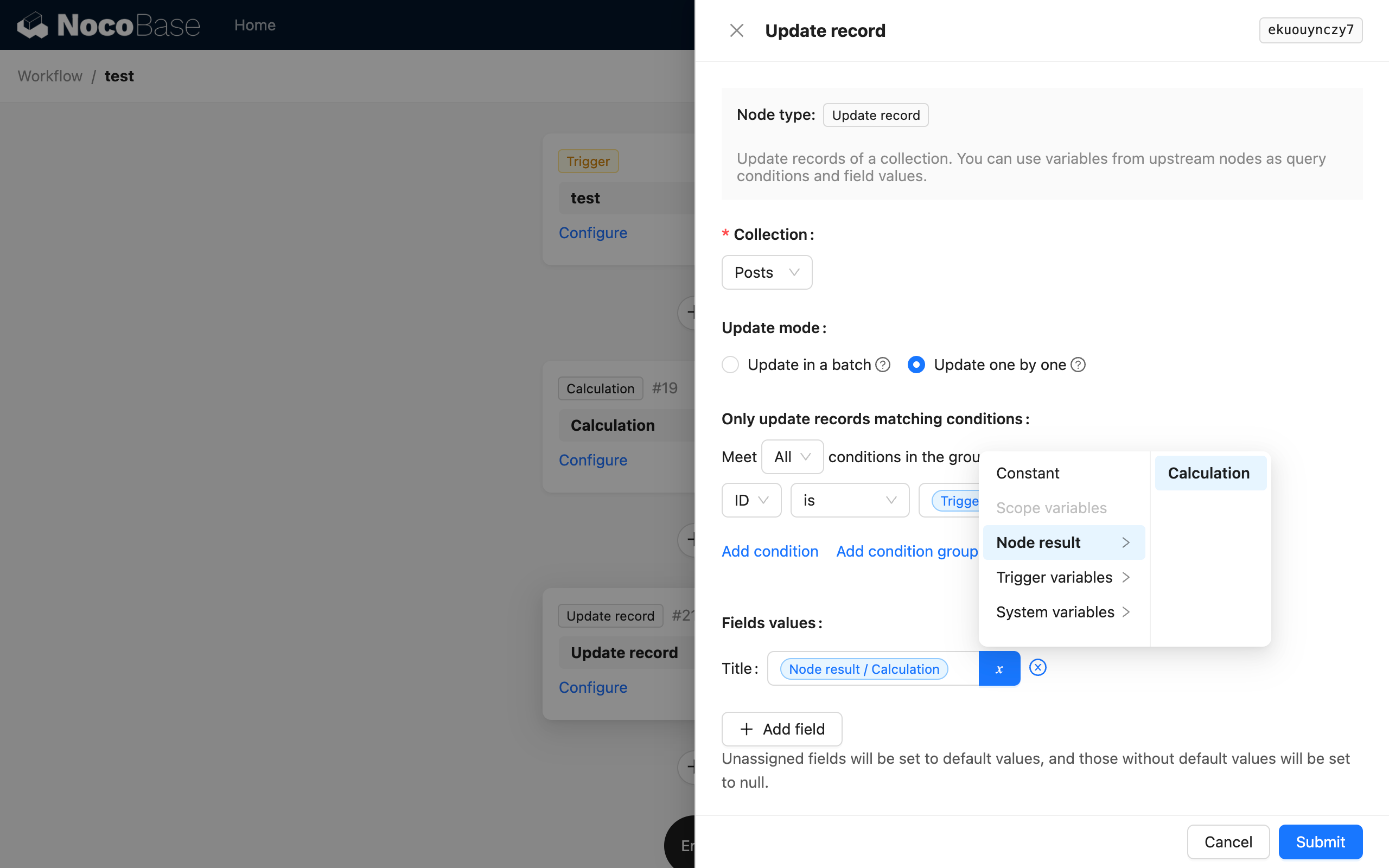
In un nodo di aggiornamento, si utilizzano i dati di contesto del trigger come variabile per la condizione di filtro, e si fa riferimento al risultato del nodo di calcolo come variabile per il valore del campo da aggiornare:
Struttura dei dati
Internamente, una variabile è una struttura JSON, e di solito è possibile utilizzare una parte specifica dei dati tramite il suo percorso JSON. Poiché molte variabili si basano sulla struttura delle collezione di NocoBase, i dati di associazione saranno strutturati gerarchicamente come proprietà di oggetti, formando una struttura simile ad un albero. Ad esempio, possiamo selezionare il valore di un campo specifico dai dati di associazione dei dati interrogati. Inoltre, quando i dati di associazione hanno una struttura "uno a molti", la variabile potrebbe essere un array.
Quando si seleziona una variabile, il più delle volte sarà necessario selezionare l'attributo di valore finale, che di solito è un tipo di dato semplice come un numero o una stringa. Tuttavia, quando c'è un array nella gerarchia delle variabili, l'attributo di ultimo livello verrà anch'esso mappato a un array. Solo se il nodo corrispondente supporta gli array, i dati dell'array potranno essere elaborati correttamente. Ad esempio, in un nodo di calcolo, alcuni motori di calcolo hanno funzioni specifiche per la gestione degli array. Un altro esempio è in un nodo di ciclo, dove l'oggetto del ciclo può anche essere un array.
Ad esempio, quando un nodo di query interroga più dati, il risultato del nodo sarà un array contenente più righe di dati omogenei:
Tuttavia, quando lo si utilizza come variabile nei nodi successivi, se la variabile selezionata è nella forma Dati nodo/Nodo di query/Titolo, si otterrà un array mappato ai valori dei campi corrispondenti:
Se si tratta di un array multidimensionale (come un campo di relazione molti a molti), si otterrà un array unidimensionale con il campo corrispondente appiattito.
Variabili di sistema integrate
Ora di sistema
Ottiene l'ora di sistema al momento dell'esecuzione del nodo. Il fuso orario di questa ora è quello impostato sul server.
Parametri dell'intervallo di date
Può essere utilizzato quando si configurano le condizioni di filtro del campo data nei nodi di query, aggiornamento ed eliminazione. È supportato solo per i confronti "è uguale a". Sia l'ora di inizio che quella di fine dell'intervallo di date si basano sul fuso orario impostato sul server.