Questo documento è stato tradotto dall'IA. Per informazioni accurate, consultare la versione inglese.
Conversazione testuale
Dipendente AICommunity Edition+Introduzione
Utilizzando il nodo LLM del flusso di lavoro, è possibile avviare una conversazione con un servizio LLM online, sfruttando le capacità dei grandi modelli per assistere nel completamento di una serie di processi aziendali.
Nuovo nodo LLM
Poiché le conversazioni con i servizi LLM richiedono solitamente molto tempo, il nodo LLM può essere utilizzato solo in flussi di lavoro asincroni.
Selezione del modello
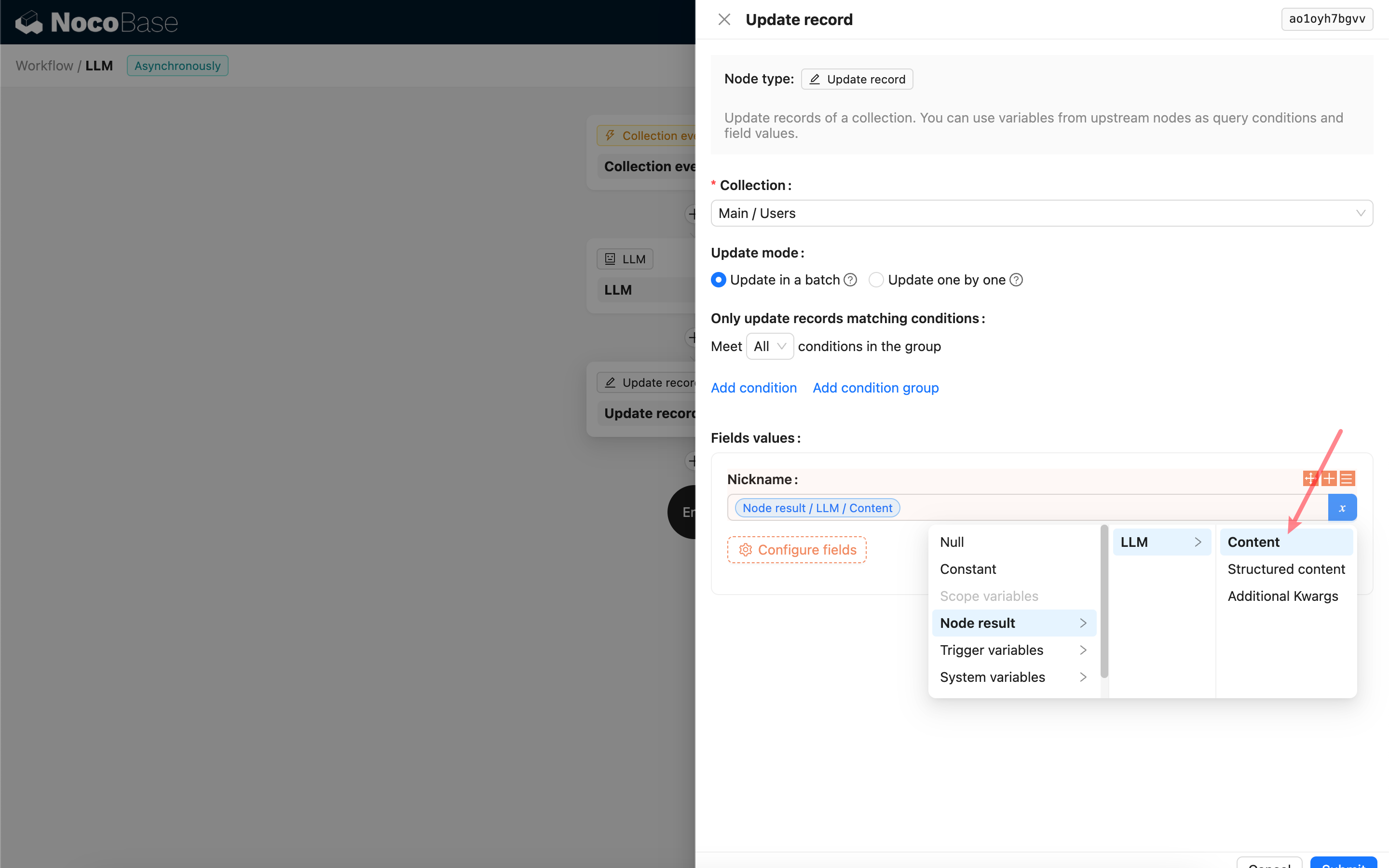
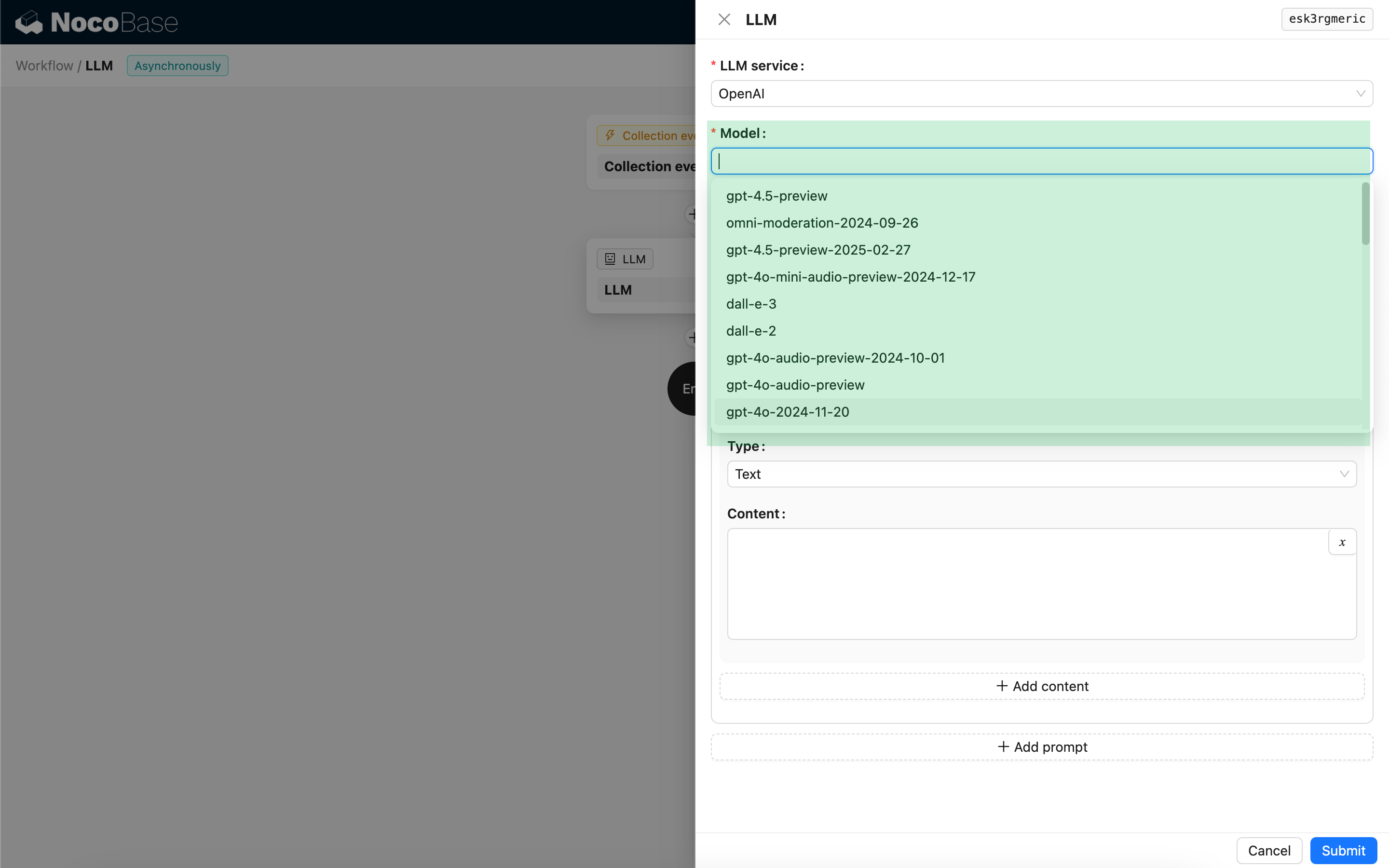
Innanzitutto, selezioni un servizio LLM già connesso; se non ha ancora connesso un servizio LLM, deve prima aggiungere una configurazione del servizio LLM. Riferimento: Gestione del servizio LLM
Dopo aver selezionato un servizio, l'applicazione tenterà di recuperare l'elenco dei modelli disponibili dal servizio LLM tra cui scegliere. Alcune interfacce di recupero dei modelli dei servizi LLM online potrebbero non essere conformi ai protocolli API standard; l'utente può anche inserire manualmente l'ID del modello.
Impostazione dei parametri di chiamata
È possibile regolare i parametri per la chiamata del modello LLM secondo le necessità.
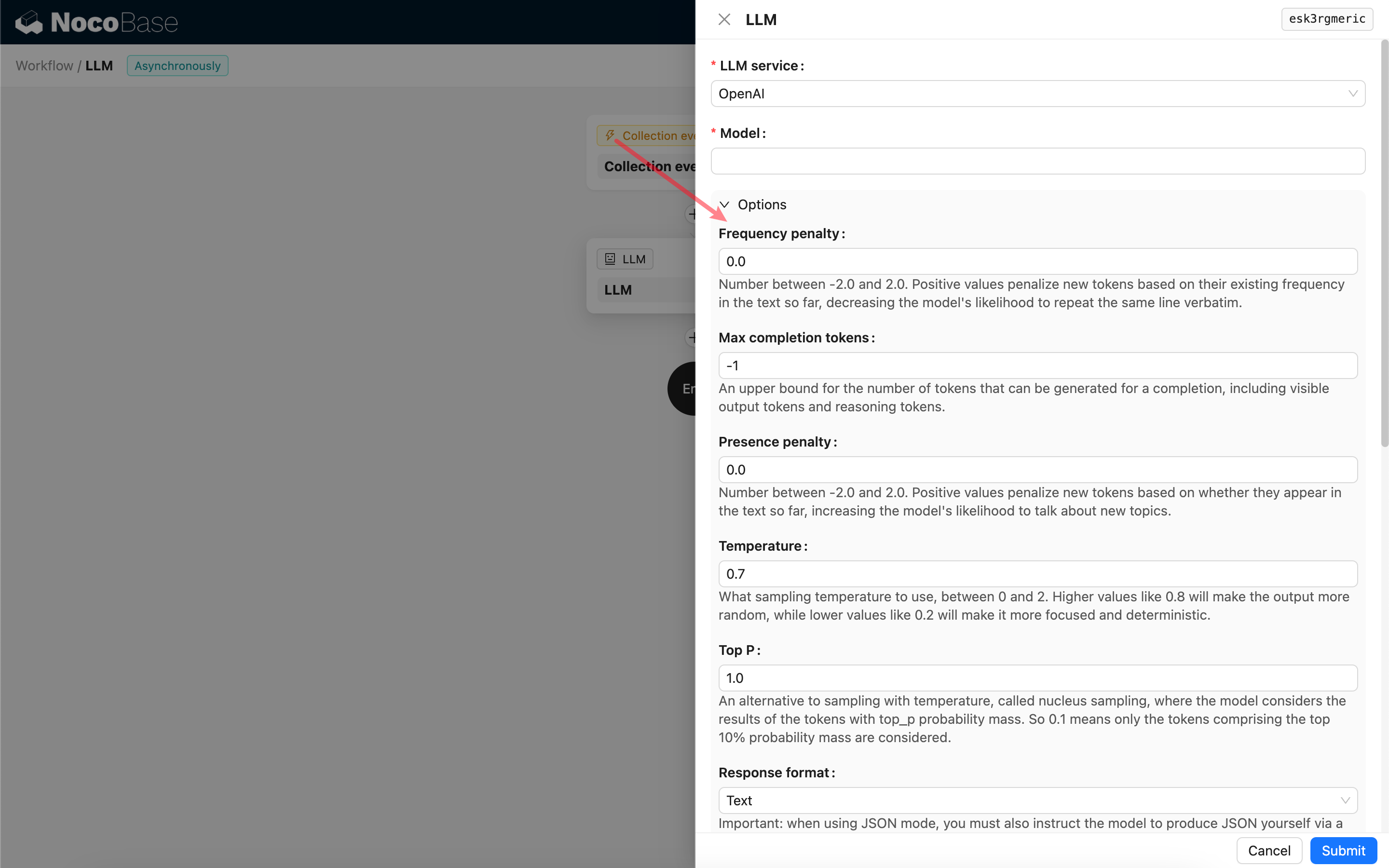
Response format
Tra queste, vale la pena notare l'impostazione Response format, utilizzata per suggerire al grande modello il formato del contenuto della risposta, che può essere testo o JSON. Se si seleziona la modalità JSON, occorre prestare attenzione a:
- Il modello LLM corrispondente deve supportare la chiamata in modalità JSON; allo stesso tempo, l'utente deve indicare esplicitamente nel Prompt che l'LLM risponda in formato JSON, ad esempio: "Tell me a joke about cats, respond in JSON with `setup` and `punchline` keys". In caso contrario, potrebbe non esserci alcun risultato di risposta, con l'errore
400 status code (no body). - Il risultato della risposta è una stringa JSON; l'utente deve utilizzare le capacità di altri nodi del flusso di lavoro per analizzarla prima di poter utilizzare il contenuto strutturato al suo interno. È anche possibile utilizzare la funzione Output strutturato.
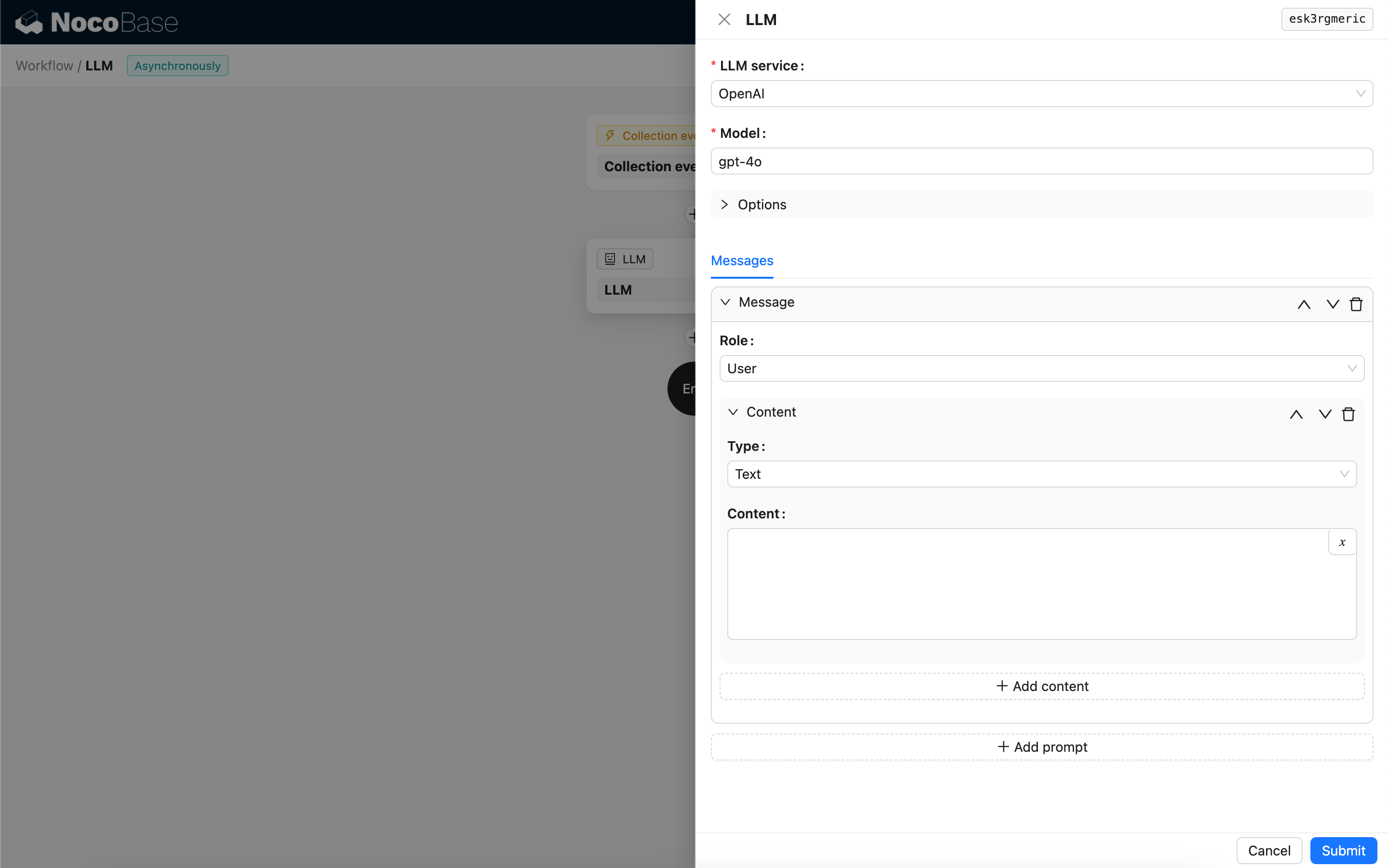
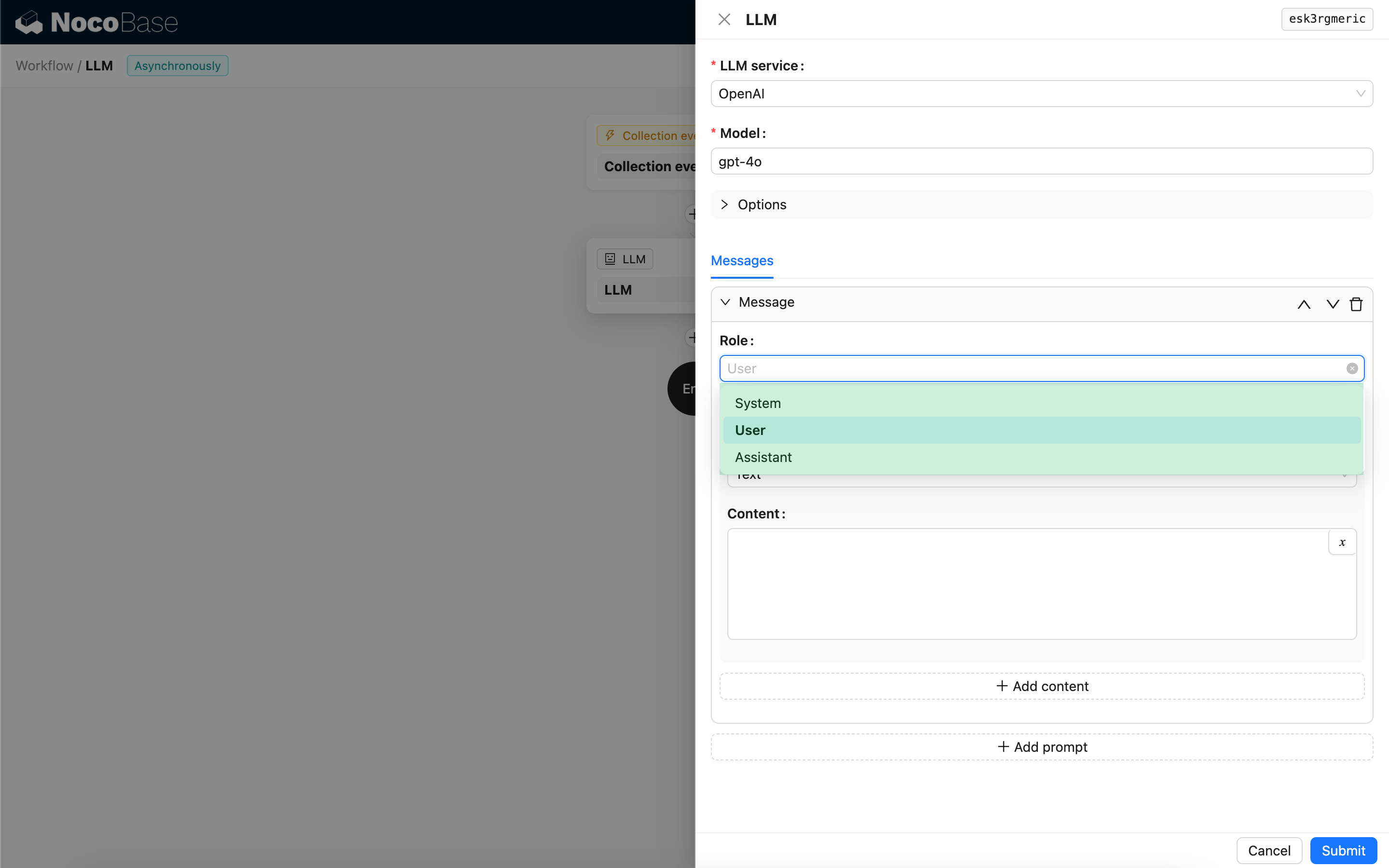
Messaggi
Un array di messaggi inviati al modello LLM, che può contenere un insieme di messaggi storici. I messaggi supportano tre tipi:
- System - Solitamente utilizzato per definire il ruolo e il comportamento del modello LLM nella conversazione.
- User - Il contenuto inserito dall'utente.
- Assistant - Il contenuto della risposta del modello.
Per i messaggi utente, se il modello lo supporta, è possibile aggiungere più contenuti in un singolo prompt, corrispondenti al parametro content. Se il modello utilizzato supporta solo il parametro content sotto forma di stringa (la maggior parte dei modelli che non supportano conversazioni multimodali appartiene a questa categoria), la preghiamo di suddividere il messaggio in più prompt, mantenendo un solo contenuto per ogni prompt; in questo modo, il nodo invierà il contenuto sotto forma di stringa.
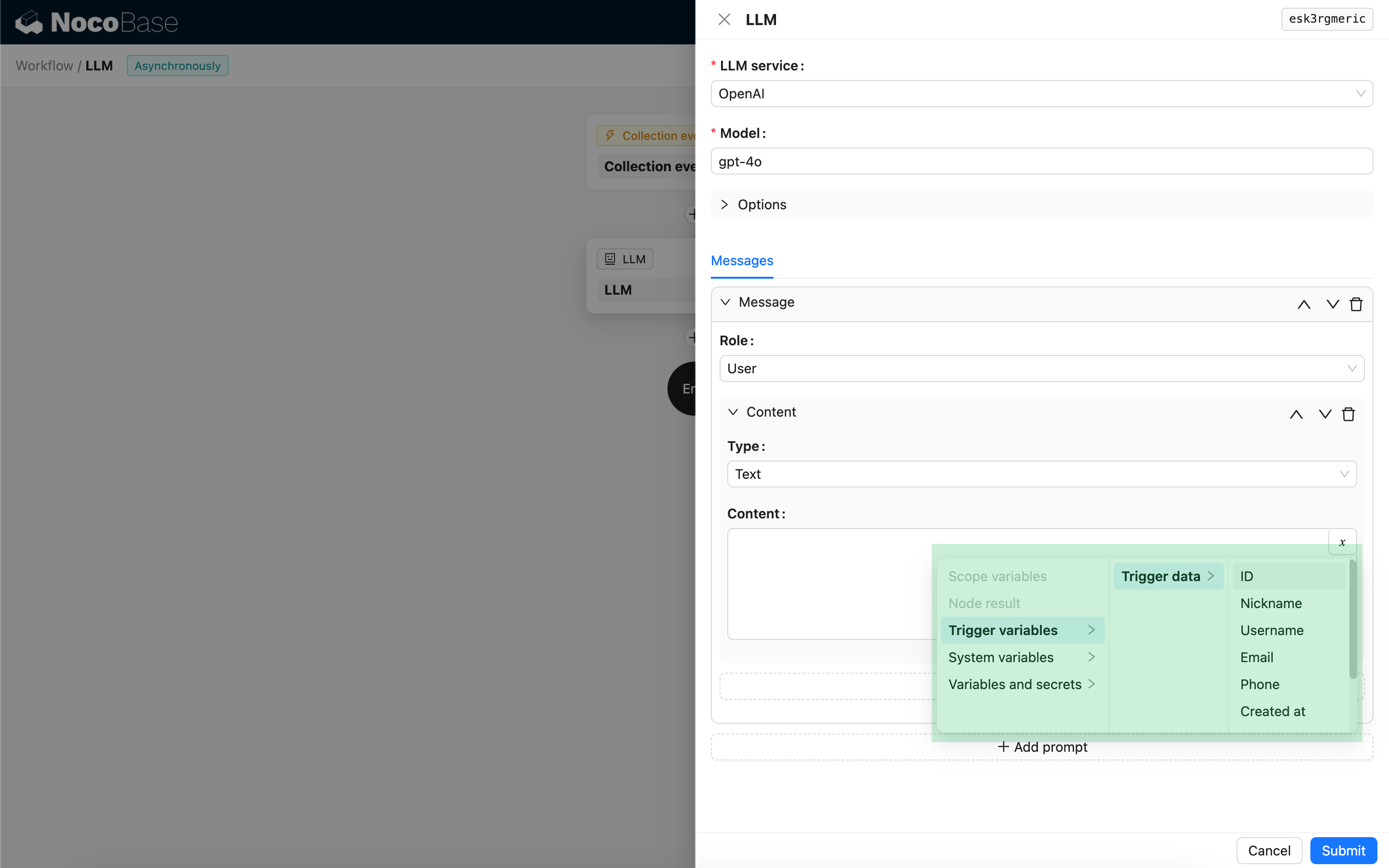
Nel contenuto del messaggio è possibile utilizzare variabili per fare riferimento al contesto del flusso di lavoro.
Utilizzo del contenuto della risposta del nodo LLM
È possibile utilizzare il contenuto della risposta del nodo LLM come variabile in altri nodi.