

Ten dokument został przetłumaczony przez AI. W przypadku niedokładności, proszę odnieść się do wersji angielskiej
Zapytanie o dane
Umożliwia wyszukiwanie i pobieranie rekordów z kolekcji, które spełniają określone warunki.
Można skonfigurować zapytanie tak, aby pobierało pojedynczy rekord lub wiele rekordów. Wynik zapytania może być użyty jako zmienna w kolejnych węzłach. Gdy zapytanie zwraca wiele rekordów, wynik jest tablicą. Jeśli wynik zapytania jest pusty, można zdecydować, czy kontynuować wykonywanie kolejnych węzłów.
Tworzenie węzła
W interfejsie konfiguracji przepływu pracy proszę kliknąć przycisk plusa („+”) w przepływie, aby dodać węzeł „Zapytanie o dane”:
Konfiguracja węzła
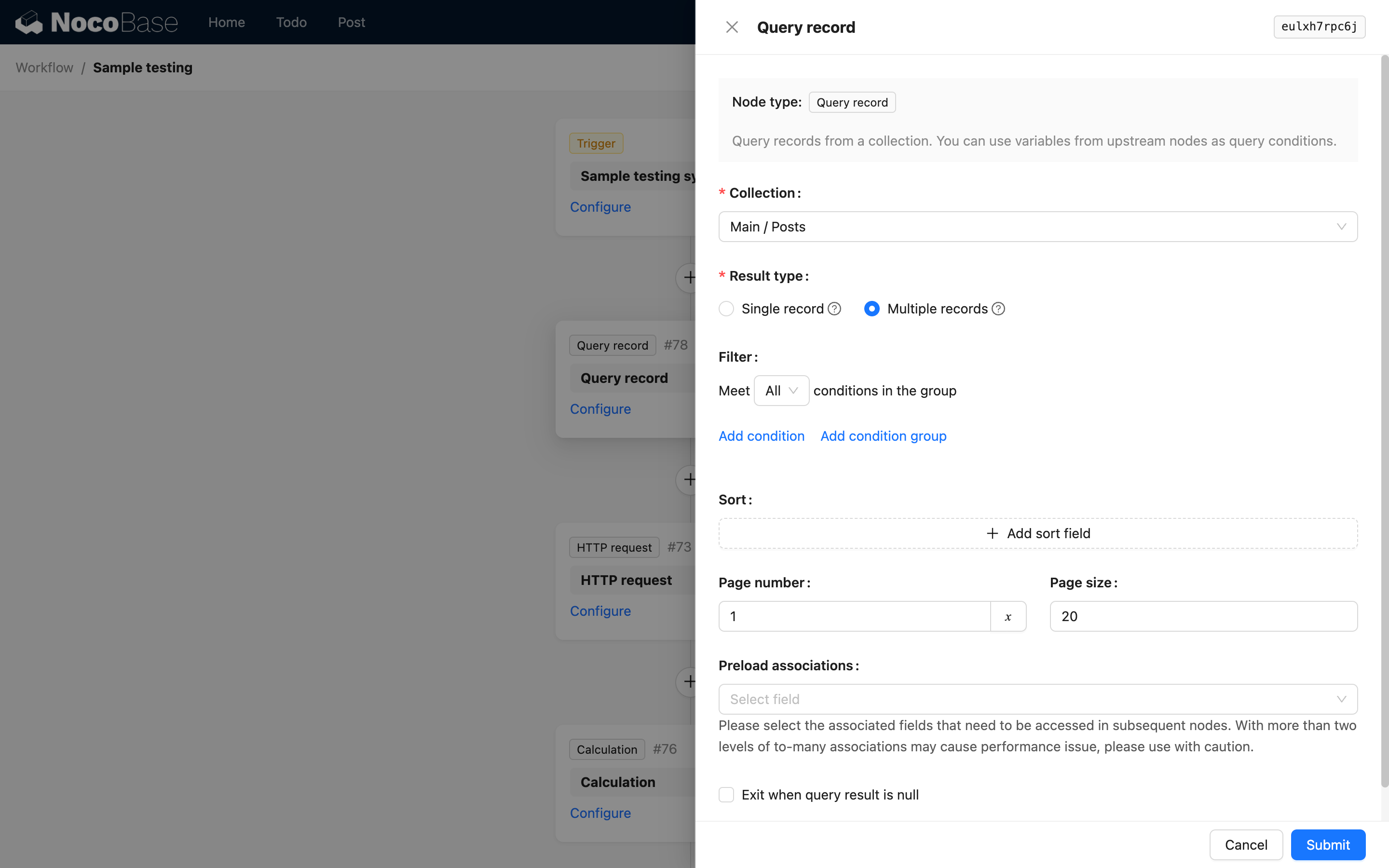
Kolekcja
Proszę wybrać kolekcję, z której mają być pobierane dane.
Typ wyniku
Typ wyniku dzieli się na „Pojedynczy rekord” i „Wiele rekordów”:
- Pojedynczy rekord: Wynikiem jest obiekt, zawierający tylko pierwszy pasujący rekord lub wartość
null. - Wiele rekordów: Wynikiem będzie tablica zawierająca rekordy spełniające warunki. Jeśli nie ma pasujących rekordów, będzie to pusta tablica. Można je przetwarzać pojedynczo za pomocą węzła pętli.
Warunki filtrowania
Podobnie jak w przypadku warunków filtrowania w zwykłym zapytaniu do kolekcji, można używać zmiennych kontekstowych przepływu pracy.
Sortowanie
Podczas wysyłania zapytania o jeden lub wiele rekordów, można użyć reguł sortowania, aby kontrolować pożądany wynik. Na przykład, aby znaleźć najnowszy rekord, można posortować dane według pola „Czas utworzenia” w kolejności malejącej.
Stronicowanie
Gdy zestaw wyników może być bardzo duży, można użyć stronicowania, aby kontrolować liczbę wyników zapytania. Na przykład, aby pobrać 10 najnowszych rekordów, można posortować dane według pola „Czas utworzenia” w kolejności malejącej, a następnie ustawić stronicowanie na 1 stronę z 10 rekordami.
Obsługa pustych wyników
W trybie pojedynczego rekordu, jeśli żadne dane nie spełniają warunków, wynik zapytania będzie null. W trybie wielu rekordów będzie to pusta tablica ([]). Mogą Państwo zdecydować, czy zaznaczyć opcję „Wyjdź z przepływu pracy, gdy wynik zapytania jest pusty”. Po zaznaczeniu tej opcji, jeśli wynik zapytania będzie pusty, kolejne węzły nie zostaną wykonane, a przepływ pracy zakończy się wcześniej ze statusem błędu.