Ten dokument został przetłumaczony przez AI. W przypadku niedokładności, proszę odnieść się do wersji angielskiej
Obliczenia JSON
Workflow: Obliczenia JSONCommunity Edition+Wprowadzenie
W oparciu o różne silniki obliczeń JSON, ten węzeł pozwala na przetwarzanie lub transformację złożonych danych JSON generowanych przez poprzedzające węzły, tak aby mogły być wykorzystane przez kolejne etapy przepływu pracy. Przykładowo, wyniki operacji SQL lub żądań HTTP mogą zostać przekształcone w wymagane wartości i formaty zmiennych, co ułatwi ich dalsze użycie.
Tworzenie węzła
W interfejsie konfiguracji przepływu pracy, proszę kliknąć przycisk plusa („+”) w procesie, aby dodać węzeł „Obliczenia JSON”:
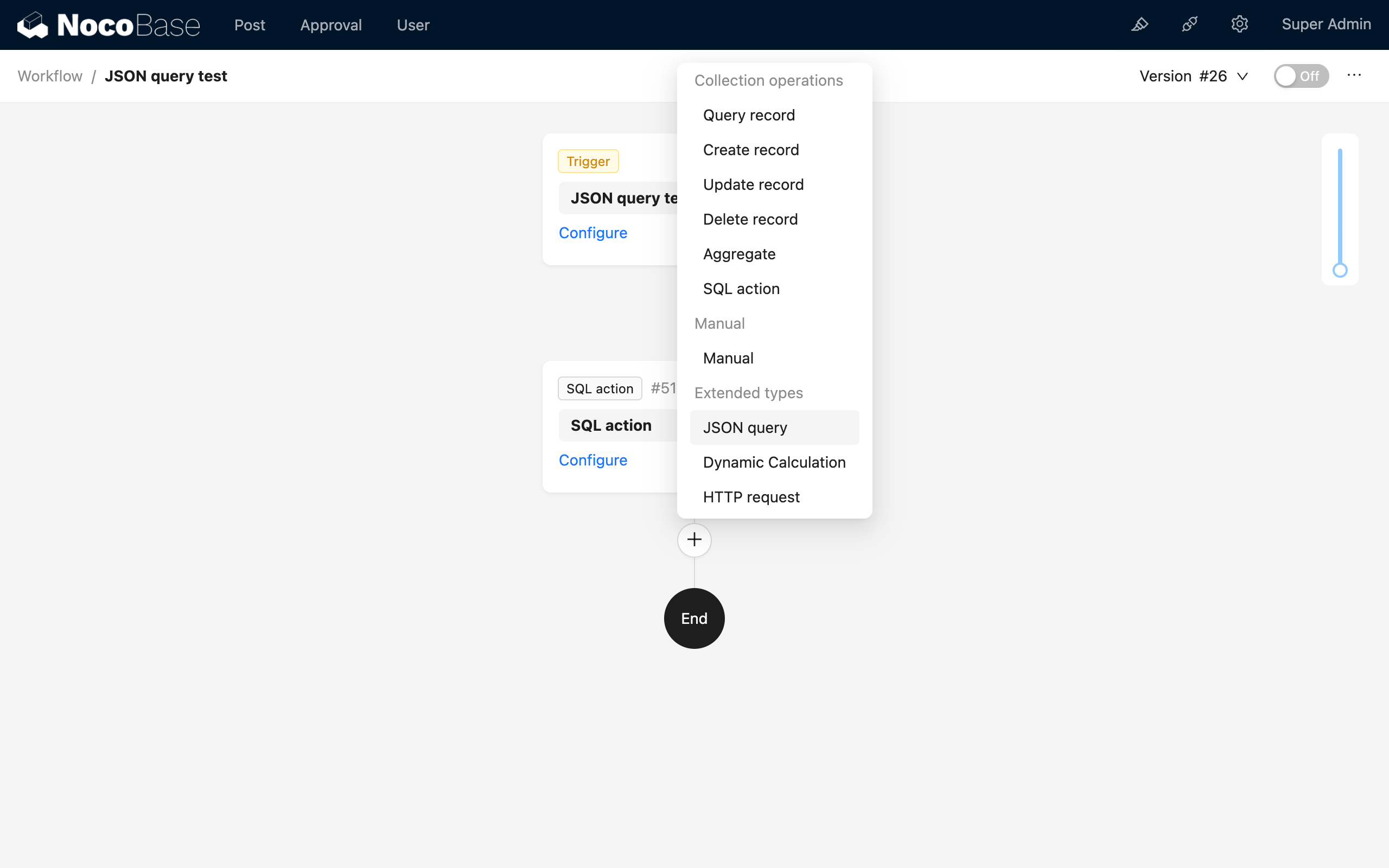
Zazwyczaj węzeł Obliczenia JSON tworzy się poniżej innych węzłów danych, aby móc je przetwarzać.
Konfiguracja węzła
Silnik parsowania
Węzeł Obliczenia JSON obsługuje różne składnie dzięki różnym silnikom parsowania. Mogą Państwo wybrać silnik w zależności od swoich preferencji i specyfiki każdego z nich. Obecnie obsługiwane są trzy silniki parsowania:
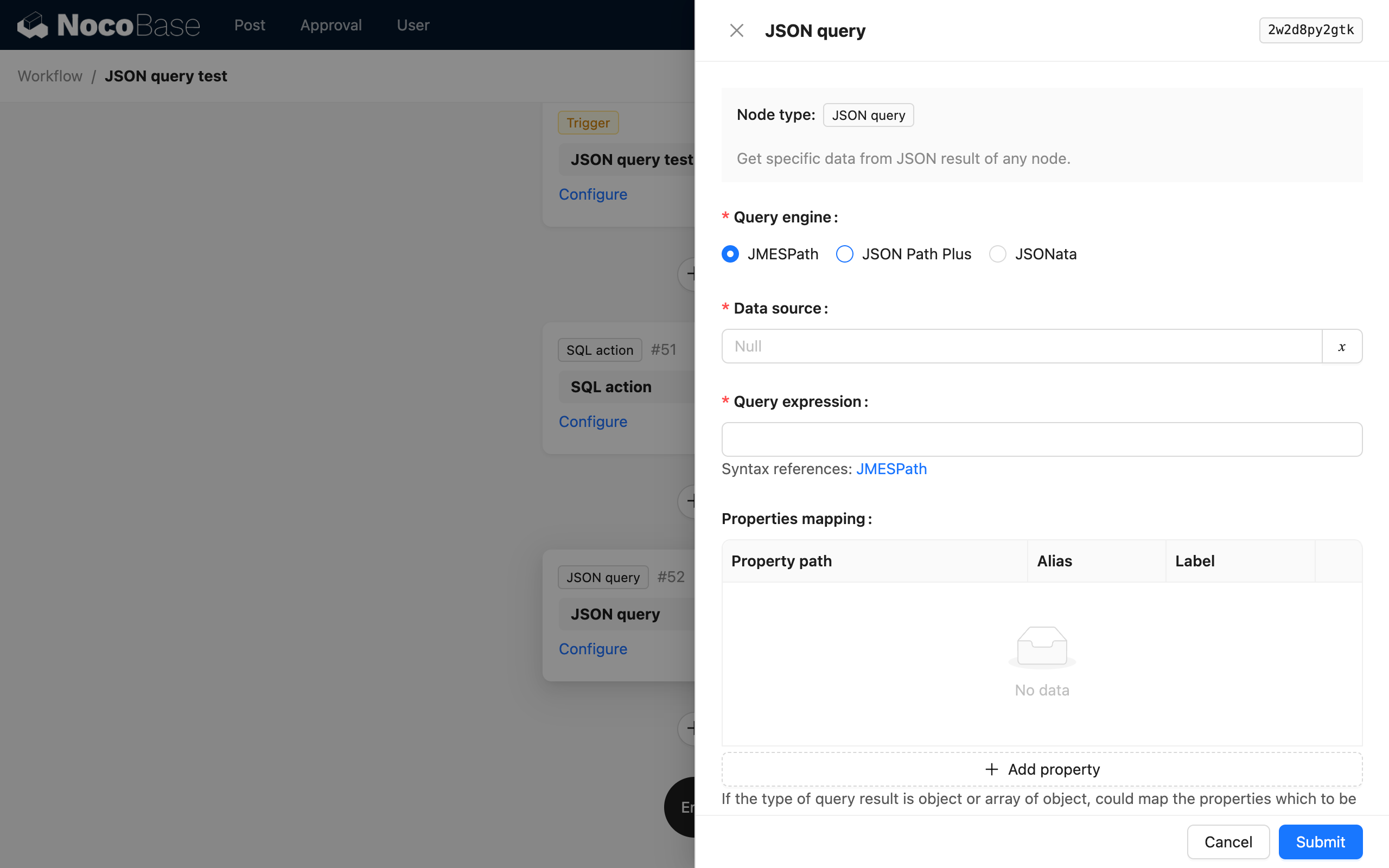
Źródło danych
Źródłem danych może być wynik poprzedzającego węzła lub obiekt danych w kontekście przepływu pracy. Zazwyczaj jest to obiekt danych bez wbudowanej struktury, na przykład wynik węzła SQL lub węzła żądania HTTP.
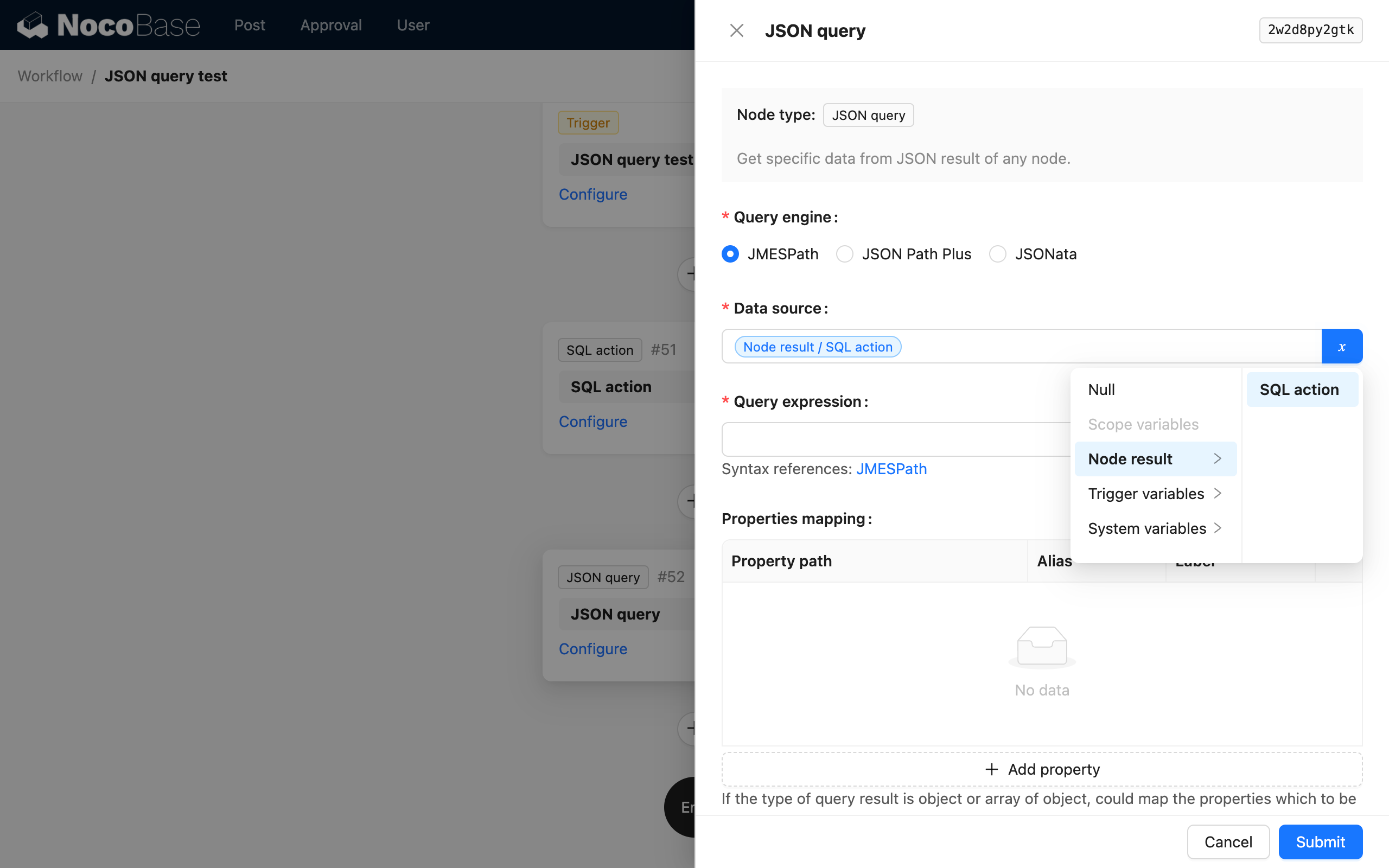
Zazwyczaj obiekty danych z węzłów związanych z kolekcjami są już ustrukturyzowane za pomocą informacji konfiguracyjnych kolekcji i zazwyczaj nie wymagają parsowania przez węzeł Obliczenia JSON.
Wyrażenie parsowania
Niestandardowe wyrażenia parsowania, dostosowane do wymagań parsowania i wybranego silnika parsowania.
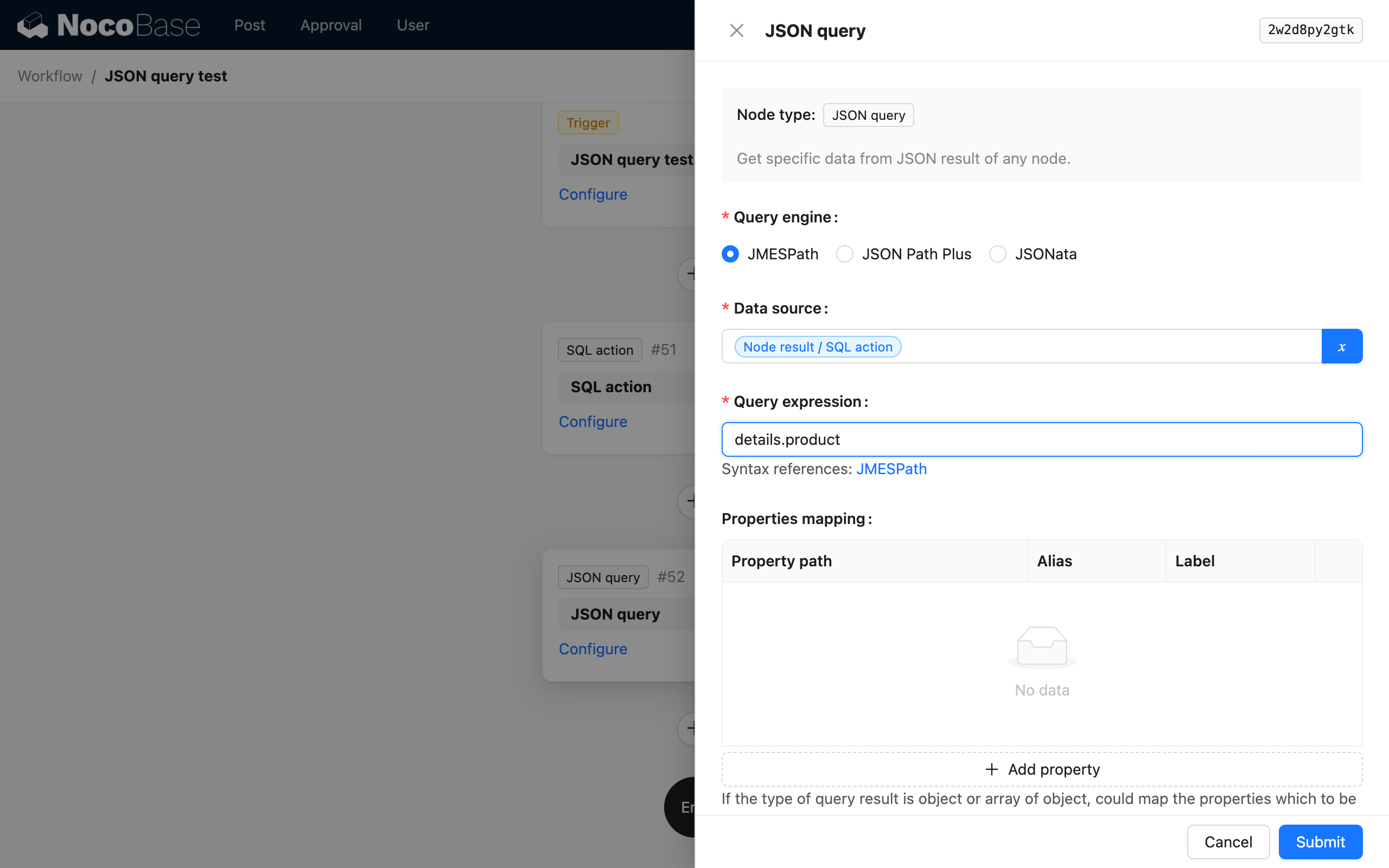
Różne silniki oferują różne składnie parsowania. Szczegóły znajdą Państwo w dokumentacji dostępnej pod linkami.
Od wersji v1.0.0-alpha.15 wyrażenia obsługują zmienne. Zmienne są wstępnie parsowane przed wykonaniem przez konkretny silnik, zastępując je określonymi wartościami tekstowymi zgodnie z regułami szablonów ciągów znaków, a następnie łączone z innymi statycznymi ciągami w wyrażeniu, tworząc ostateczne wyrażenie. Ta funkcja jest bardzo przydatna, gdy trzeba dynamicznie budować wyrażenia, na przykład gdy część zawartości JSON wymaga dynamicznego klucza do parsowania.
Mapowanie właściwości
Gdy wynikiem obliczeń jest obiekt (lub tablica obiektów), mogą Państwo dalej mapować wymagane właściwości na zmienne podrzędne za pomocą mapowania właściwości, aby mogły być użyte przez kolejne węzły.
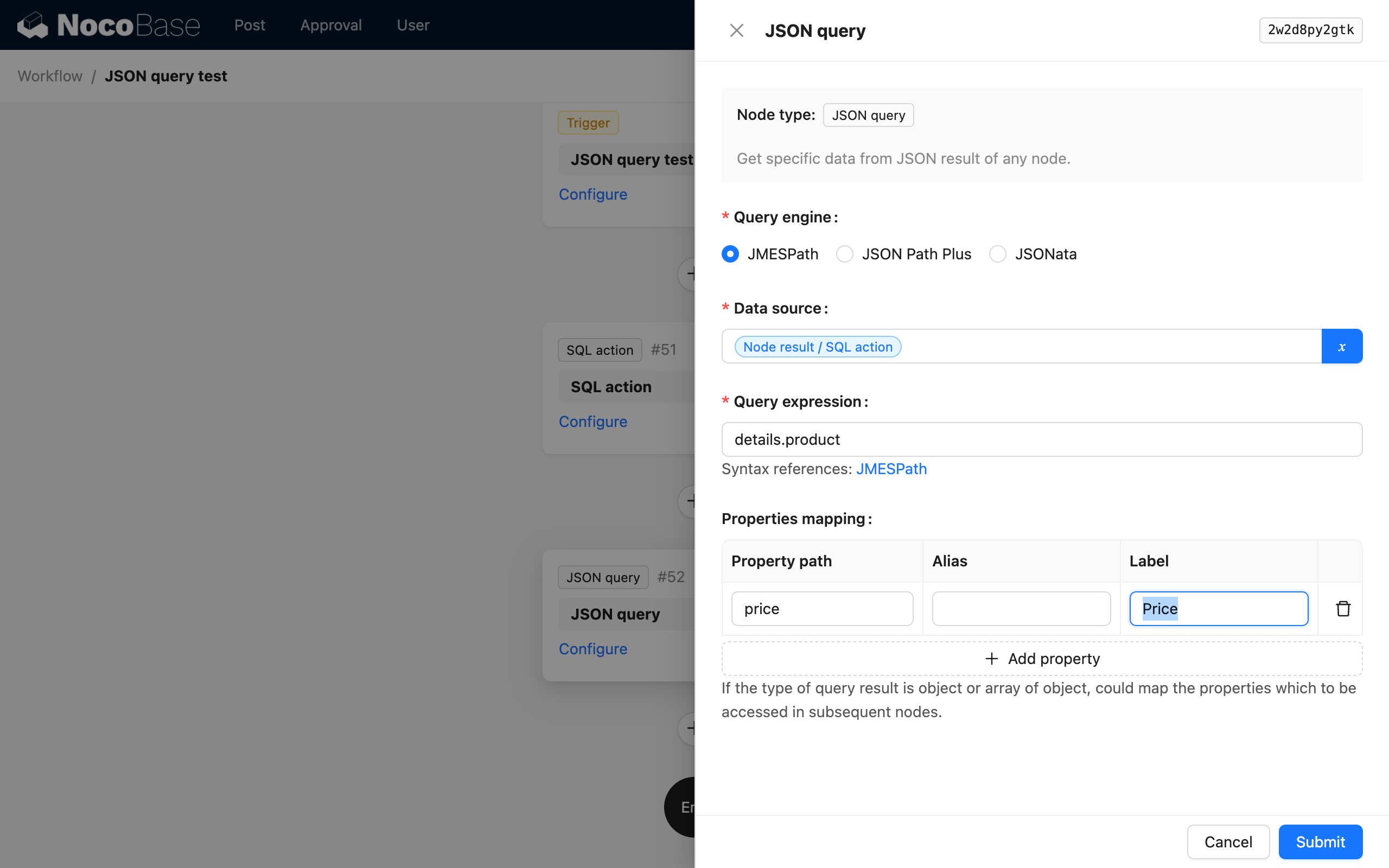
Dla wyniku będącego obiektem (lub tablicą obiektów), jeśli mapowanie właściwości nie zostanie wykonane, cały obiekt (lub tablica obiektów) zostanie zapisany jako pojedyncza zmienna w wyniku węzła, a wartości właściwości obiektu nie będą mogły być używane bezpośrednio jako zmienne.
Przykład
Załóżmy, że dane do parsowania pochodzą z poprzedzającego węzła SQL, który służy do pobierania danych, a jego wynikiem jest zestaw danych zamówień:
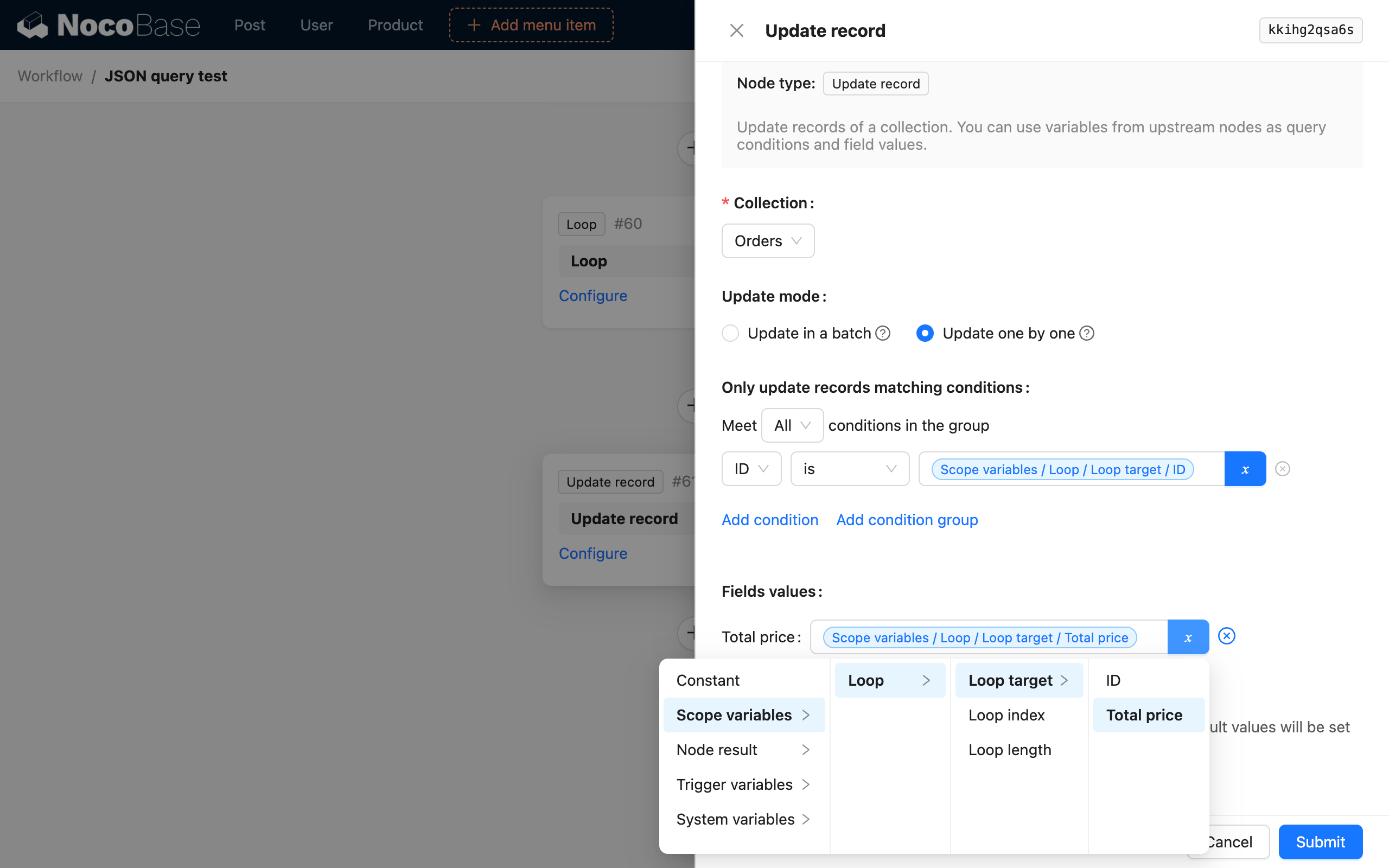
Jeśli chcemy sparsować i obliczyć całkowitą cenę dwóch zamówień z danych, a następnie połączyć ją z odpowiadającym ID zamówienia w obiekt, aby zaktualizować całkowitą cenę zamówienia, możemy to skonfigurować w następujący sposób:
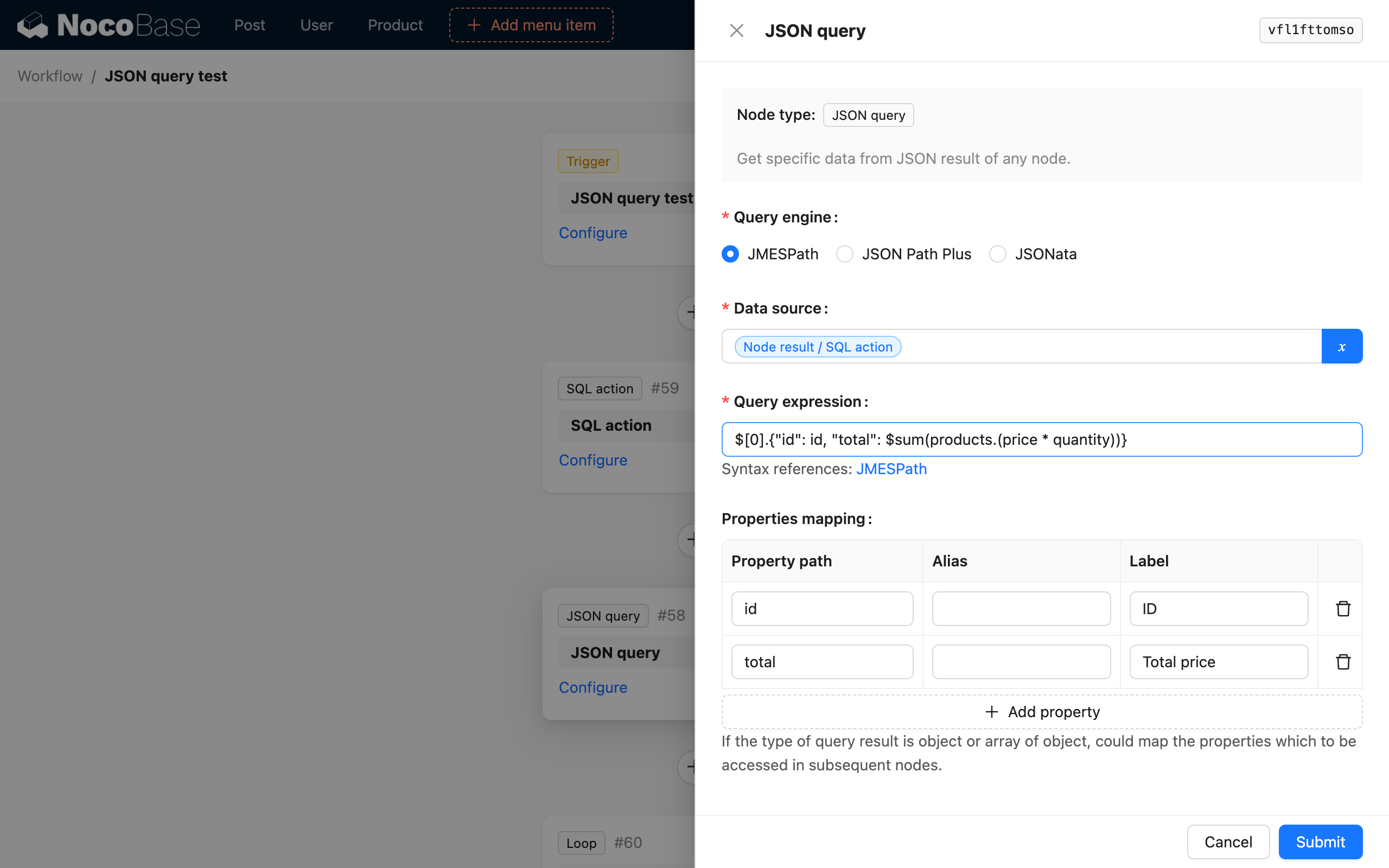
- Proszę wybrać silnik parsowania JSONata;
- Proszę wybrać wynik węzła SQL jako źródło danych;
- Proszę użyć wyrażenia JSONata
$[0].{"id": id, "total": products.(price * quantity)}do parsowania; - Proszę wybrać mapowanie właściwości, aby zmapować
iditotalna zmienne podrzędne;
Ostateczny wynik parsowania jest następujący:
Następnie, proszę iterować przez wynikową tablicę zamówień, aby zaktualizować całkowitą cenę zamówień.