Diese Dokumentation wurde automatisch von KI übersetzt.
JSON Berechnung
Workflow: JSON-BerechnungCommunity Edition+Einführung
Basierend auf verschiedenen JSON-Berechnungs-Engines berechnet oder transformiert dieser Knoten komplexe JSON-Daten, die von vorhergehenden Knoten erzeugt wurden, damit sie von nachfolgenden Knoten verwendet werden können. Zum Beispiel können die Ergebnisse von SQL-Operationen und HTTP-Anfrage-Knoten durch diesen Knoten in die benötigten Werte und Variablenformate umgewandelt werden, um von nachfolgenden Knoten genutzt zu werden.
Knoten erstellen
In der Konfigurationsoberfläche des Workflows klicken Sie auf das Plus-Symbol („+“) im Prozess, um einen „JSON Berechnung“-Knoten hinzuzufügen:
Normalerweise wird der JSON Berechnung-Knoten unterhalb anderer Datenknoten erstellt, um diese zu parsen.
Knotenkonfiguration
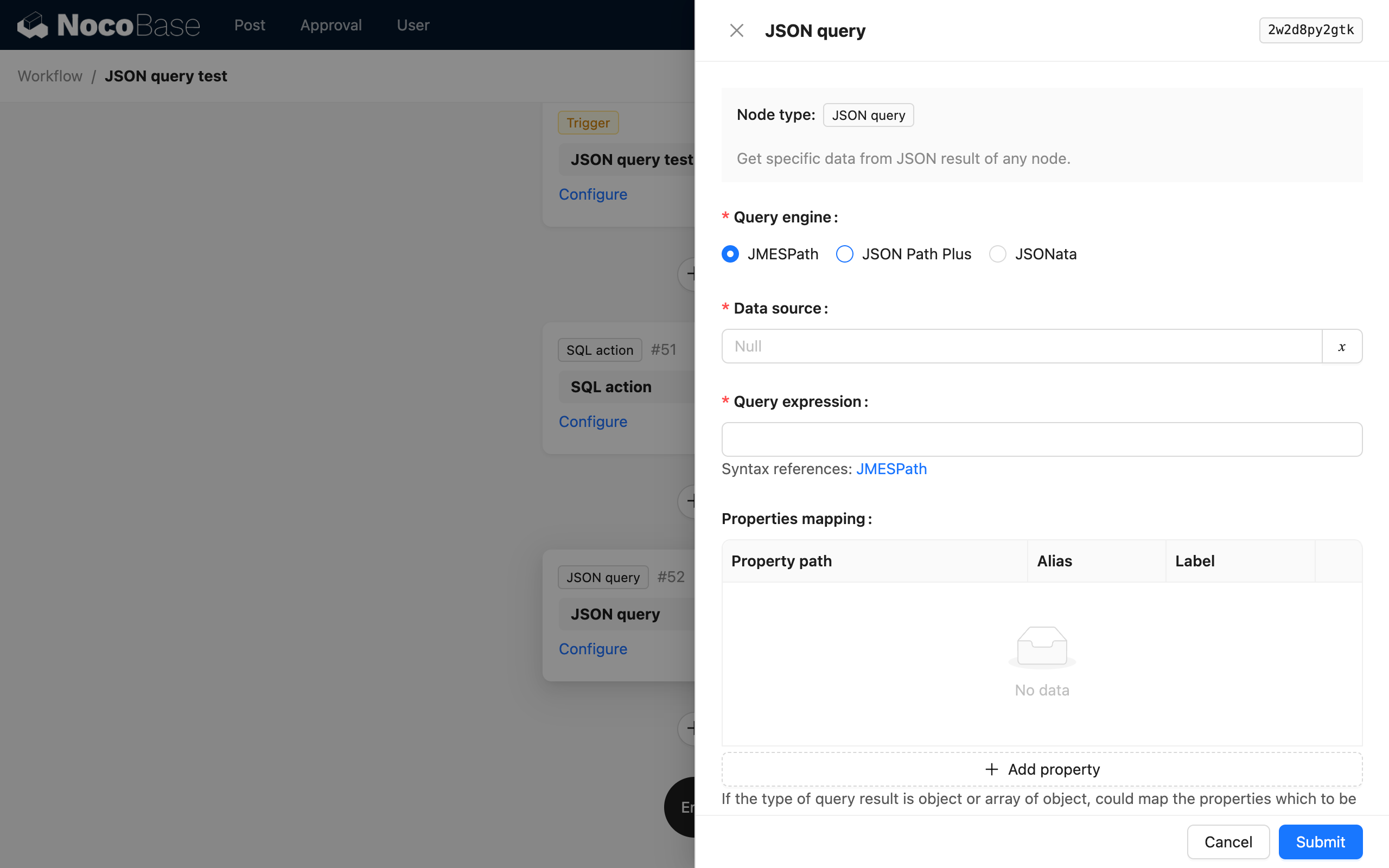
Parsing-Engine
Der JSON Berechnung-Knoten unterstützt verschiedene Syntaxen durch unterschiedliche Parsing-Engines. Sie können basierend auf Ihren Präferenzen und den Besonderheiten der jeweiligen Engine wählen. Derzeit werden drei Parsing-Engines unterstützt:
Datenquelle
Die Datenquelle kann das Ergebnis eines vorhergehenden Knotens oder ein Datenobjekt im Workflow-Kontext sein. Dabei handelt es sich typischerweise um ein Datenobjekt ohne integrierte Struktur, wie zum Beispiel das Ergebnis eines SQL-Knotens oder eines HTTP-Anfrage-Knotens.
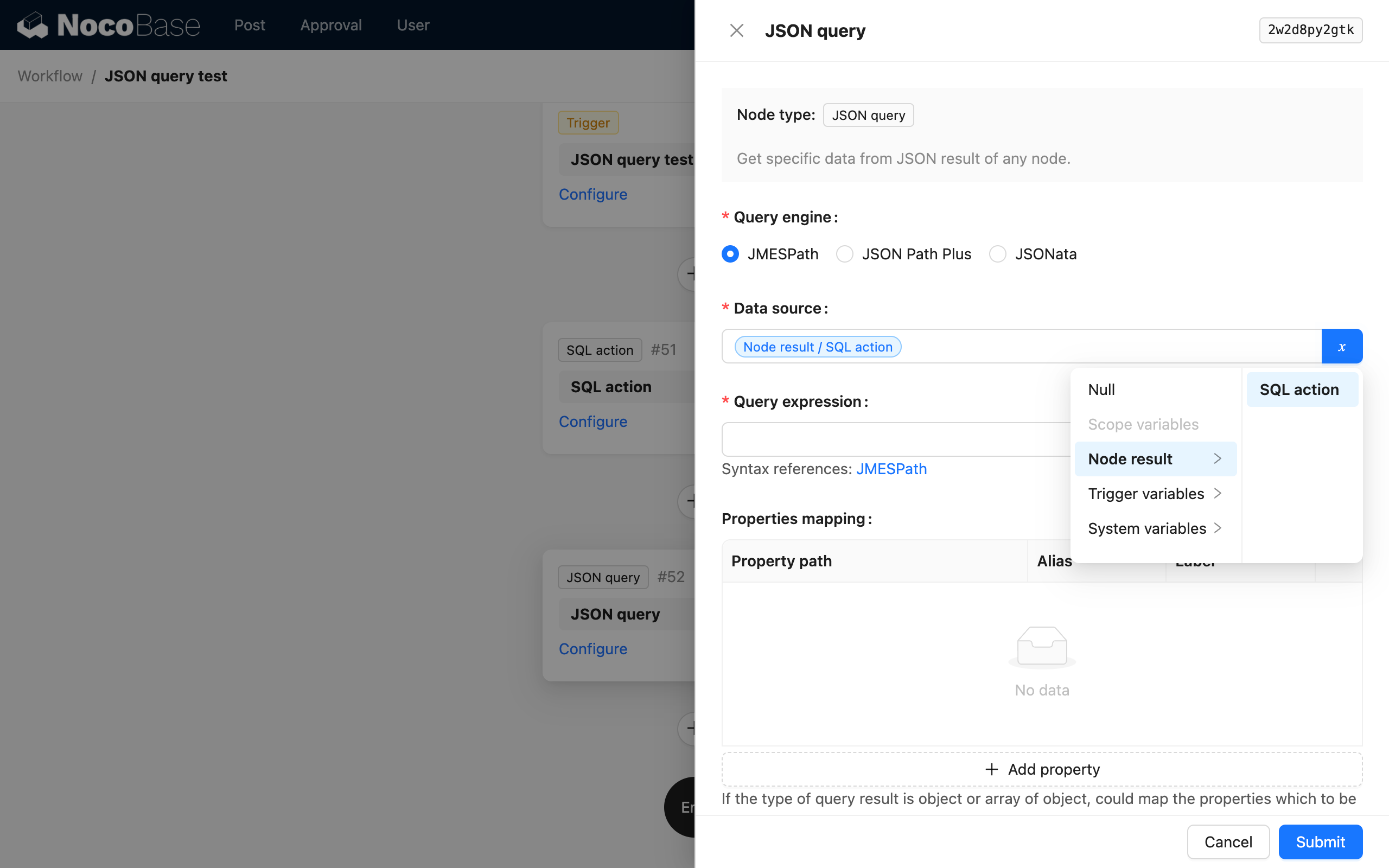
Normalerweise sind die Datenobjekte von Sammlung-bezogenen Knoten durch die Sammlung-Konfigurationsinformationen strukturiert und müssen in der Regel nicht durch den JSON Berechnung-Knoten geparst werden.
Parsing-Ausdruck
Benutzerdefinierte Parsing-Ausdrücke basierend auf den Parsing-Anforderungen und der gewählten Parsing-Engine.
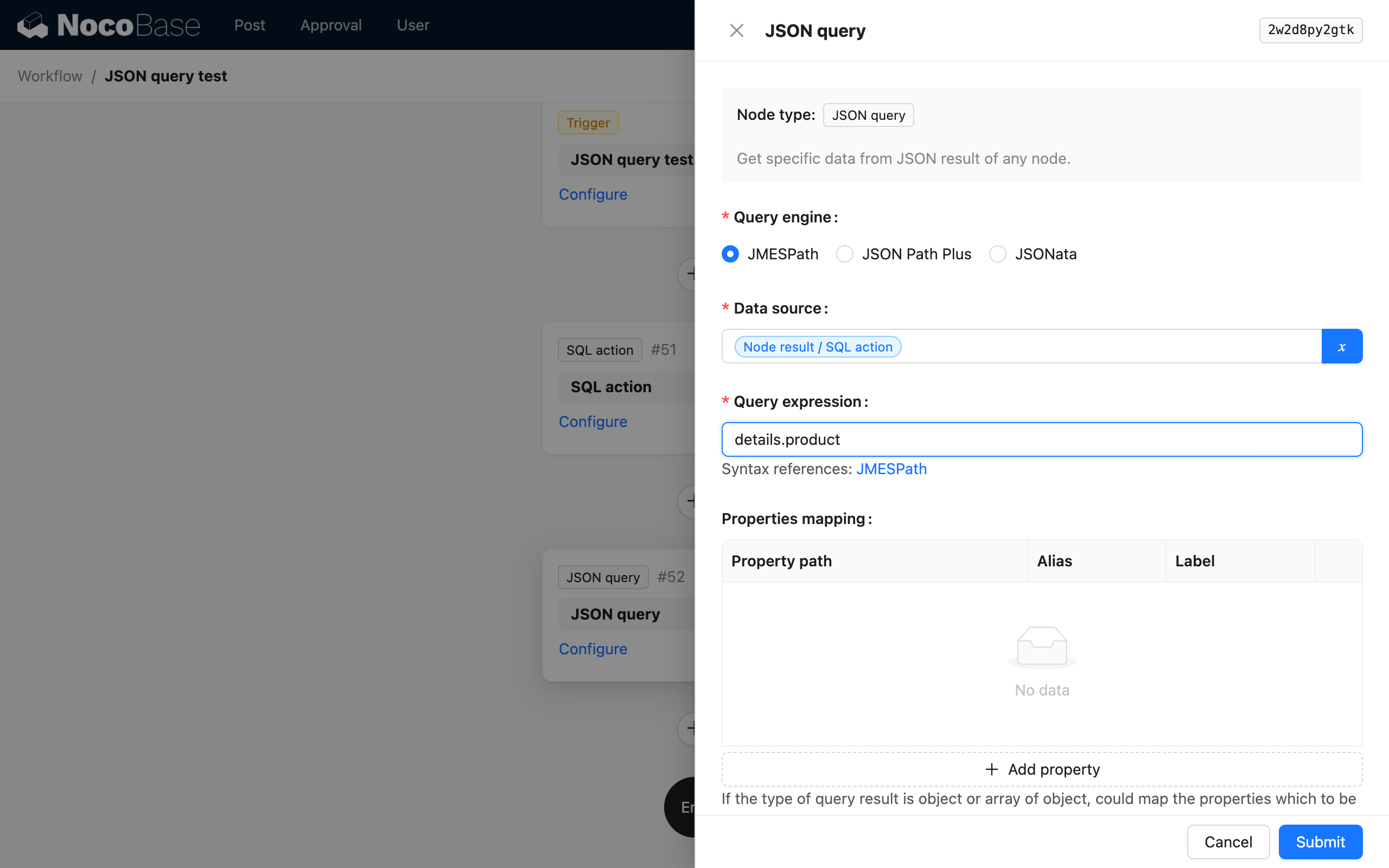
Verschiedene Engines bieten unterschiedliche Parsing-Syntaxen. Details entnehmen Sie bitte der Dokumentation in den Links.
Seit Version v1.0.0-alpha.15 unterstützen Ausdrücke Variablen. Variablen werden vor der Ausführung durch die jeweilige Engine vorab geparst, wobei die Variablen gemäß den Regeln von String-Templates durch spezifische String-Werte ersetzt und mit anderen statischen Strings im Ausdruck zum finalen Ausdruck zusammengefügt werden. Diese Funktion ist sehr nützlich, wenn Sie Ausdrücke dynamisch erstellen müssen, zum Beispiel, wenn bestimmte JSON-Inhalte einen dynamischen Schlüssel zum Parsen benötigen.
Eigenschaftszuordnung
Wenn das Berechnungsergebnis ein Objekt (oder ein Array von Objekten) ist, können Sie die benötigten Eigenschaften durch Eigenschaftszuordnung weiter als untergeordnete Variablen zuordnen, damit sie von nachfolgenden Knoten verwendet werden können.
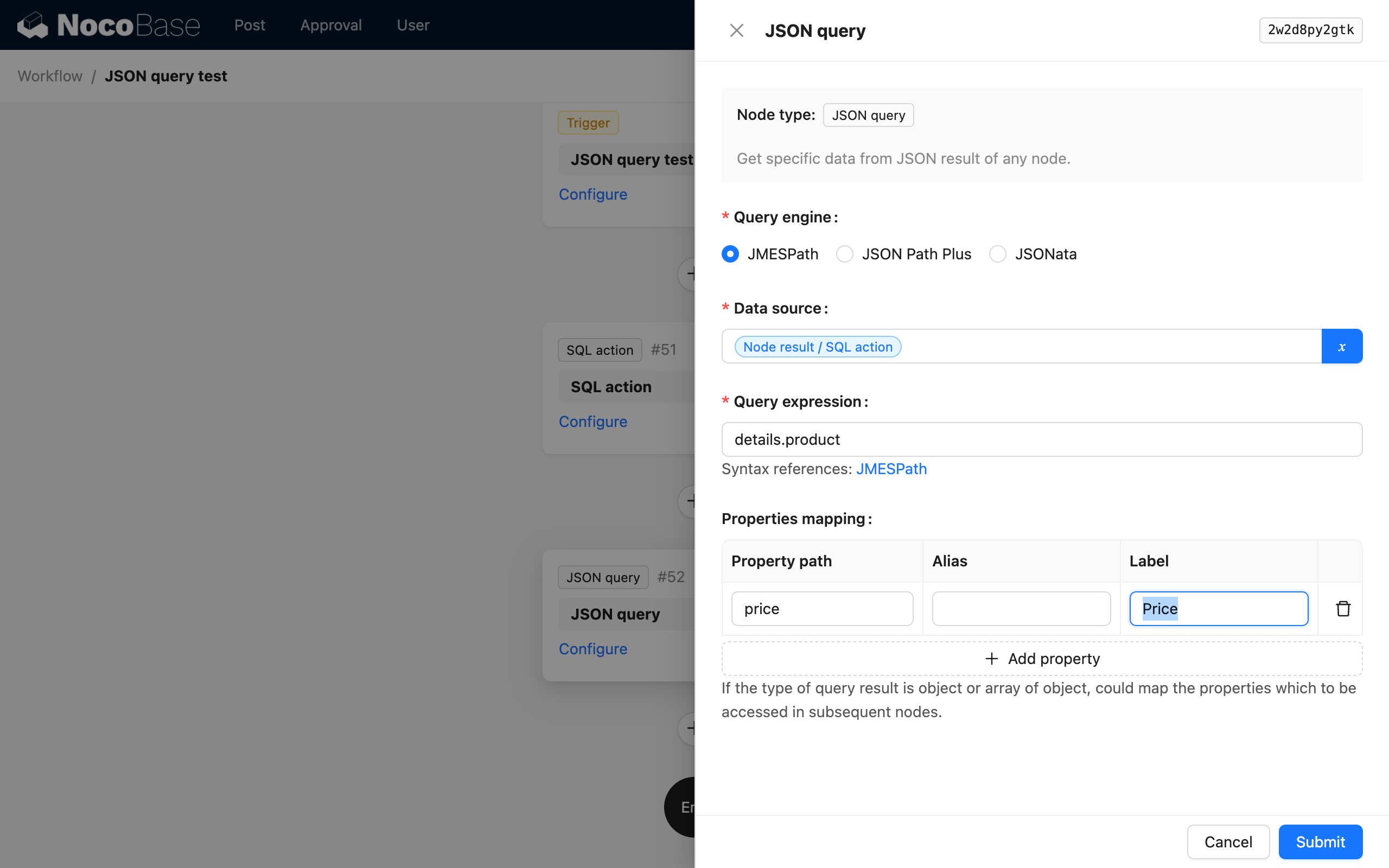
Bei einem Objekt (oder einem Array von Objekten) als Ergebnis wird, wenn keine Eigenschaftszuordnung vorgenommen wird, das gesamte Objekt (oder Array von Objekten) als einzelne Variable im Ergebnis des Knotens gespeichert, und die Eigenschaftswerte des Objekts können nicht direkt als Variablen verwendet werden.
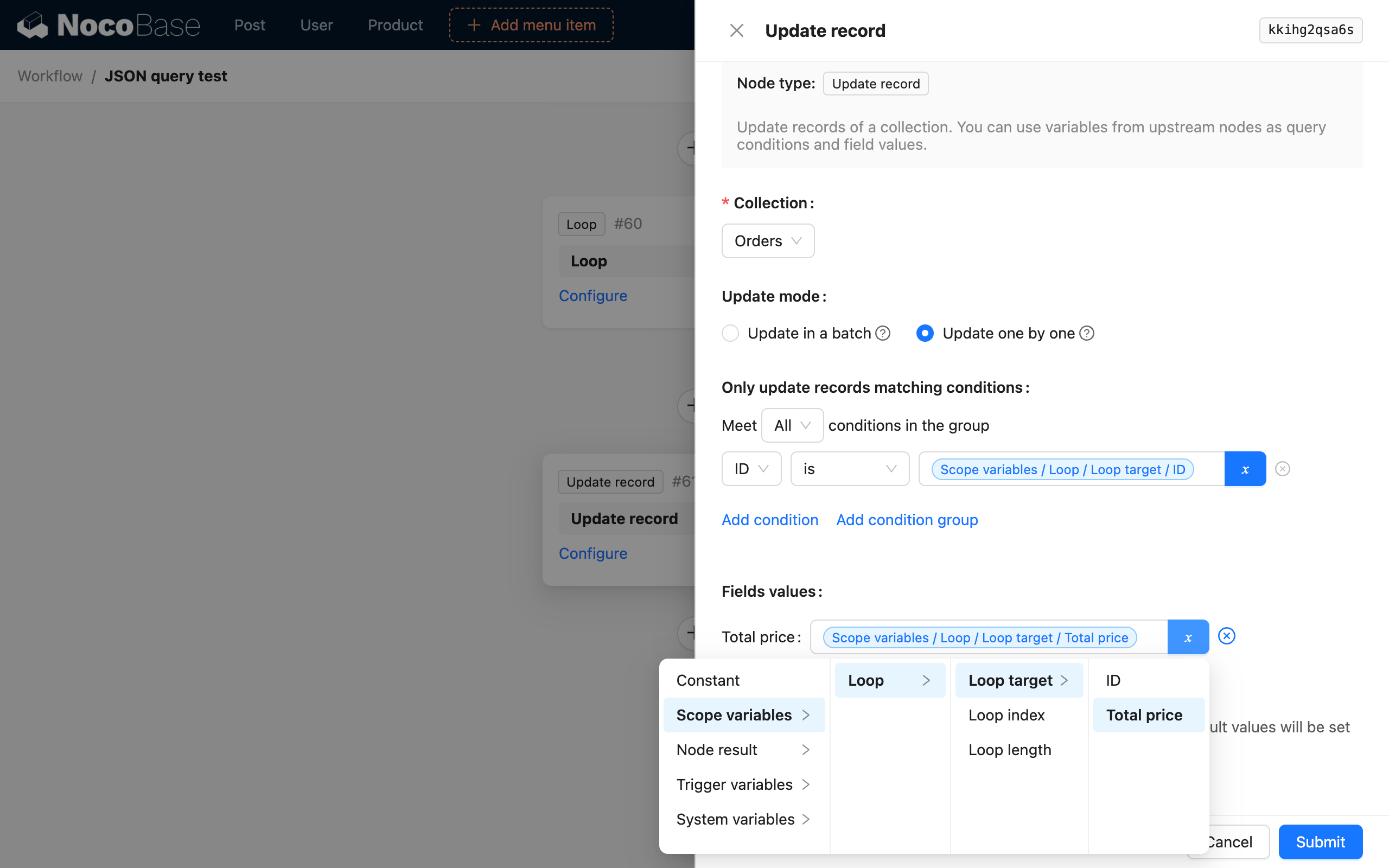
Beispiel
Angenommen, die zu parsende Daten stammen von einem vorhergehenden SQL-Knoten, der zur Abfrage von Daten verwendet wird, und dessen Ergebnis ein Satz von Bestelldaten ist:
Wenn wir die Gesamtsumme der beiden Bestellungen in den Daten parsen und berechnen und diese zusammen mit der entsprechenden Bestell-ID zu einem Objekt zusammenfügen möchten, um den Gesamtpreis der Bestellung zu aktualisieren, können wir dies wie folgt konfigurieren:
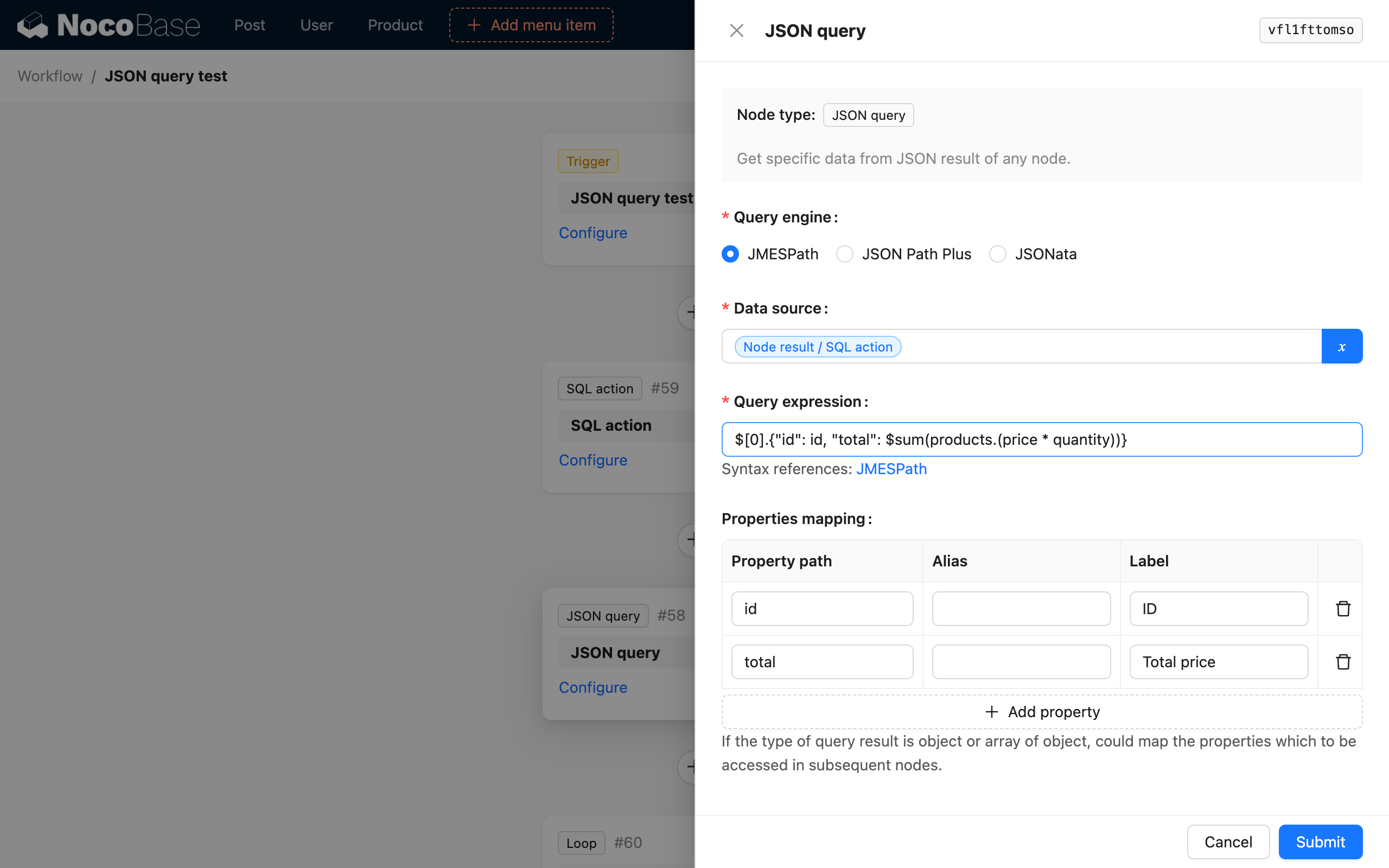
- Wählen Sie die JSONata Parsing-Engine aus;
- Wählen Sie das Ergebnis des SQL-Knotens als Datenquelle aus;
- Verwenden Sie den JSONata-Ausdruck
$[0].{"id": id, "total": products.(price * quantity)}zum Parsen; - Wählen Sie die Eigenschaftszuordnung, um
idundtotalals untergeordnete Variablen zuzuordnen;
Das finale Parsing-Ergebnis sieht wie folgt aus:
Anschließend durchlaufen Sie das resultierende Bestell-Array, um den Gesamtpreis der Bestellungen zu aktualisieren.