

이 문서는 AI로 번역되었습니다. 부정확한 내용이 있을 경우 영어 버전을 참조하세요
집계 쿼리
워크플로우: 집계 쿼리 노드Community Edition+소개
특정 컬렉션의 조건을 만족하는 데이터를 대상으로 집계 함수 쿼리를 수행하고, 그에 해당하는 통계 결과를 반환합니다. 주로 보고서 관련 통계 데이터를 처리하는 데 사용됩니다.
이 노드는 데이터베이스의 집계 함수를 기반으로 구현되었습니다. 현재는 하나의 컬렉션 내 단일 필드에 대한 통계만 지원하며, 통계 결과 값은 노드의 결과에 저장되어 이후 다른 노드에서 사용할 수 있습니다.
설치
내장 플러그인이므로 별도로 설치할 필요가 없습니다.
노드 생성
워크플로우 설정 화면에서 흐름 내의 더하기("+") 버튼을 클릭하여 "집계 쿼리" 노드를 추가합니다.
노드 설정
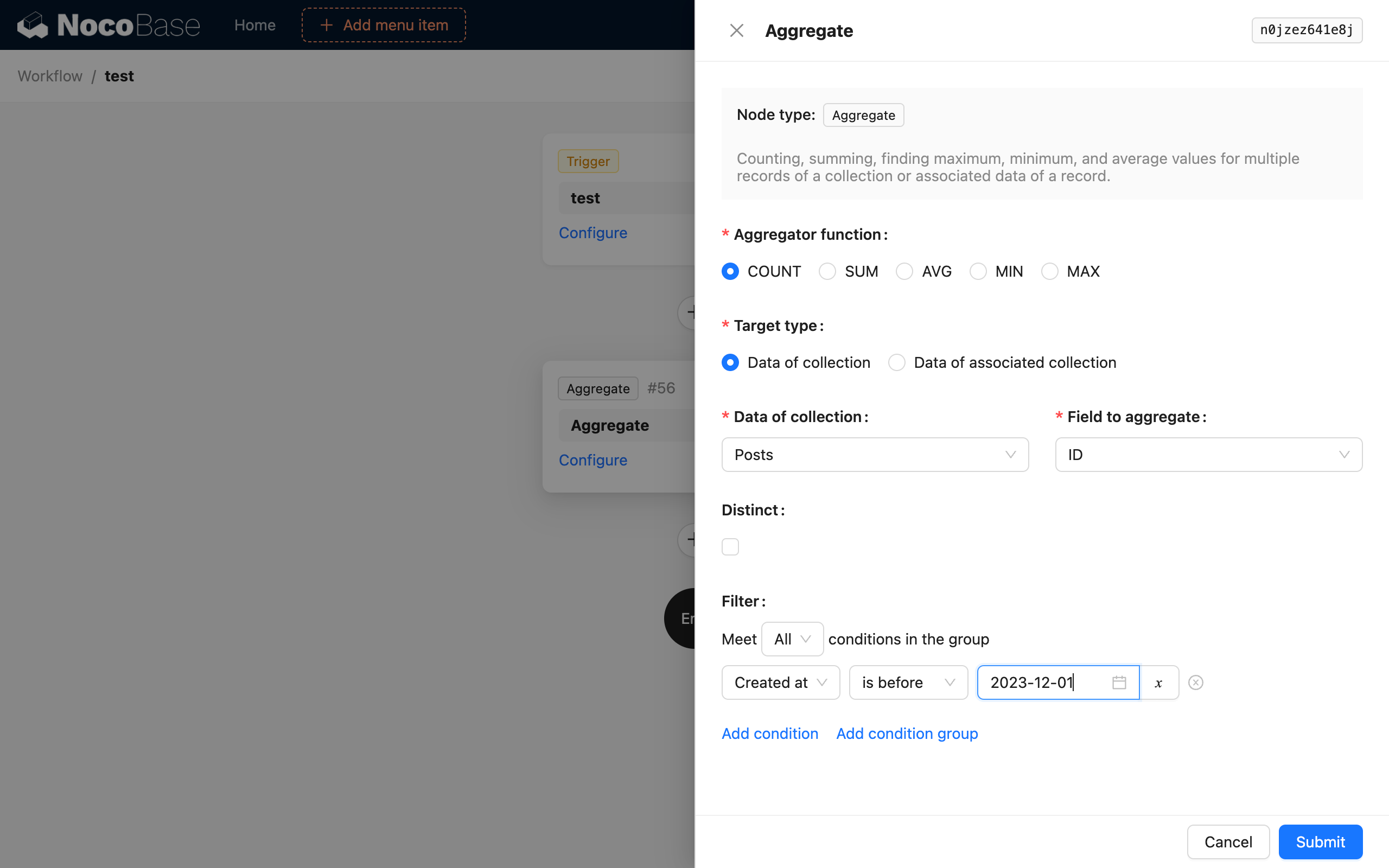
집계 함수
SQL의 COUNT, SUM, AVG, MIN, MAX 총 5가지 집계 함수를 지원합니다. 이 중 하나를 선택하여 데이터를 집계 쿼리할 수 있습니다.
대상 유형
집계 쿼리 대상은 두 가지 모드로 선택할 수 있습니다. 첫 번째는 대상 컬렉션과 그 안에 있는 하나의 필드를 직접 선택하는 방식입니다. 다른 하나는 워크플로우 컨텍스트에 이미 존재하는 데이터 객체를 통해 해당 객체의 일대다 관계 컬렉션 및 필드를 선택하여 집계 쿼리를 수행하는 방식입니다.
중복 제거
SQL의 DISTINCT와 동일합니다. 중복 제거 필드는 선택한 컬렉션 필드와 동일해야 하며, 현재는 두 필드를 다르게 선택하는 것을 지원하지 않습니다.
필터 조건
일반 컬렉션 쿼리의 필터 조건과 유사하며, 워크플로우의 컨텍스트 변수를 사용할 수 있습니다.
예시
집계 대상이 "컬렉션 데이터"인 경우는 비교적 이해하기 쉽습니다. 여기서는 "새로운 글이 추가된 후 해당 글의 카테고리에 속한 총 글의 수 계산"을 예시로 들어, 집계 대상이 "연관 컬렉션 데이터"인 경우의 사용법을 설명하겠습니다.
먼저 "글"과 "카테고리" 두 개의 컬렉션을 생성합니다. "글" 컬렉션에는 "카테고리" 컬렉션을 가리키는 다대일 관계 필드를 추가하고, 동시에 "카테고리" 컬렉션에는 "글" 컬렉션을 가리키는 역방향 일대다 관계 필드를 생성합니다.
| 필드명 | 유형 |
|---|---|
| 제목 | 한 줄 텍스트 |
| 소속 카테고리 | 다대일 (카테고리) |
| 필드명 | 유형 |
|---|---|
| 카테고리명 | 한 줄 텍스트 |
| 포함된 글 | 일대다 (글) |
다음으로, 컬렉션 이벤트에 의해 트리거되는 워크플로우를 생성합니다. "글" 컬렉션에 새 데이터가 추가된 후 트리거되도록 설정합니다.
이어서 집계 쿼리 노드를 추가하고 다음과 같이 설정합니다.
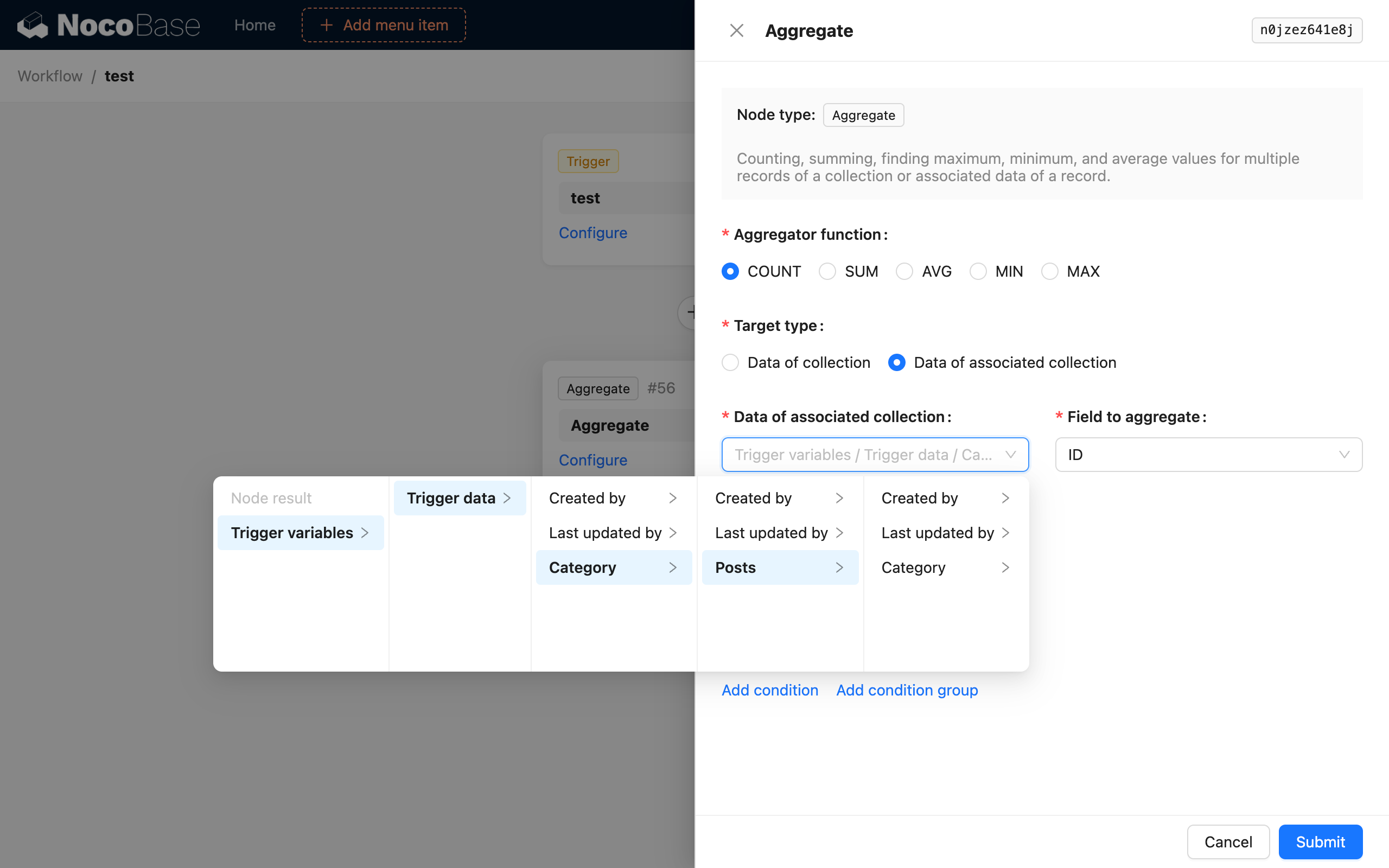
이렇게 설정하면 워크플로우가 트리거된 후, 집계 쿼리 노드에서 새로 추가된 글의 카테고리에 속한 모든 글의 수를 계산하여 노드의 결과로 저장합니다.
컬렉션 이벤트 트리거의 관계 데이터를 사용해야 하는 경우, 트리거에서 "연관 데이터 미리 로드" 관련 필드를 설정해야 합니다. 그렇지 않으면 선택할 수 없습니다.