

Cette documentation a été traduite automatiquement par IA.
Requête d'agrégation
Flux de travail : Nœud de requête d'agrégationCommunity Edition+Introduction
Permet d'effectuer des requêtes avec fonctions d'agrégation sur les données d'une collection qui remplissent certaines conditions, et de renvoyer les résultats statistiques correspondants. C'est souvent utilisé pour traiter les données statistiques des rapports.
L'implémentation de ce nœud repose sur les fonctions d'agrégation de base de données. Actuellement, il ne prend en charge que les statistiques sur un seul champ d'une collection. Le résultat numérique de ces statistiques est enregistré dans la sortie du nœud pour être utilisé par d'autres nœuds ultérieurement.
Installation
Ce plugin est intégré, aucune installation n'est requise.
Créer un nœud
Dans l'interface de configuration du flux de travail, cliquez sur le bouton plus (« + ») dans le flux pour ajouter un nœud « Requête d'agrégation » :
Configuration du nœud
Fonction d'agrégation
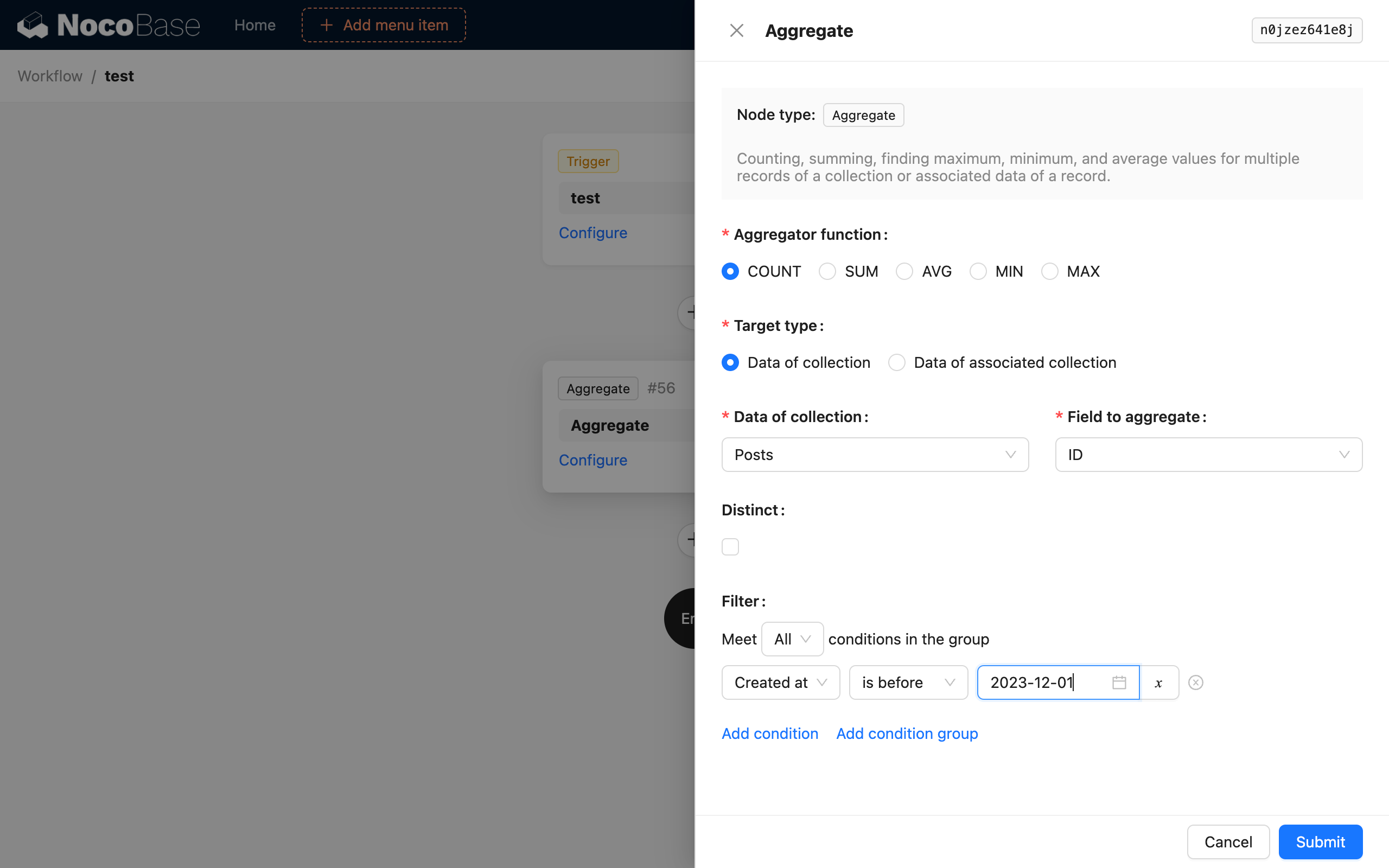
Ce nœud prend en charge 5 fonctions d'agrégation SQL : COUNT, SUM, AVG, MIN et MAX. Sélectionnez l'une d'entre elles pour effectuer une requête d'agrégation sur vos données.
Type de cible
La cible de la requête d'agrégation peut être sélectionnée de deux manières. Soit vous choisissez directement la collection cible et l'un de ses champs, soit vous sélectionnez une collection et un champ liés en relation un-à-plusieurs via un objet de données existant dans le contexte du flux de travail pour effectuer la requête d'agrégation.
Distinct
Il s'agit de la clause DISTINCT en SQL. Le champ utilisé pour la déduplication est le même que le champ de la collection sélectionnée. Il n'est pas possible pour l'instant de choisir des champs différents pour ces deux options.
Conditions de filtrage
Similaires aux conditions de filtrage d'une requête de collection normale, vous pouvez utiliser les variables de contexte du flux de travail.
Exemple
La cible d'agrégation « Données de collection » est relativement simple à comprendre. Ici, nous allons prendre l'exemple du « décompte du nombre total d'articles dans une catégorie après l'ajout d'un nouvel article » pour illustrer l'utilisation de la cible d'agrégation « Données de collection associées ».
Tout d'abord, créez deux collections : « Articles » et « Catégories ». La collection Articles possède un champ de relation plusieurs-à-un qui pointe vers la collection Catégories, et un champ de relation inverse un-à-plusieurs est également créé de Catégories vers Articles :
| Nom du champ | Type |
|---|---|
| Titre | Texte sur une ligne |
| Catégorie | Plusieurs-à-un (Catégories) |
| Nom du champ | Type |
|---|---|
| Nom de la catégorie | Texte sur une ligne |
| Articles | Un-à-plusieurs (Articles) |
Ensuite, créez un flux de travail déclenché par un événement de collection. Configurez-le pour qu'il se déclenche après l'ajout de nouvelles données à la collection Articles.
Ajoutez ensuite un nœud de requête d'agrégation et configurez-le comme suit :
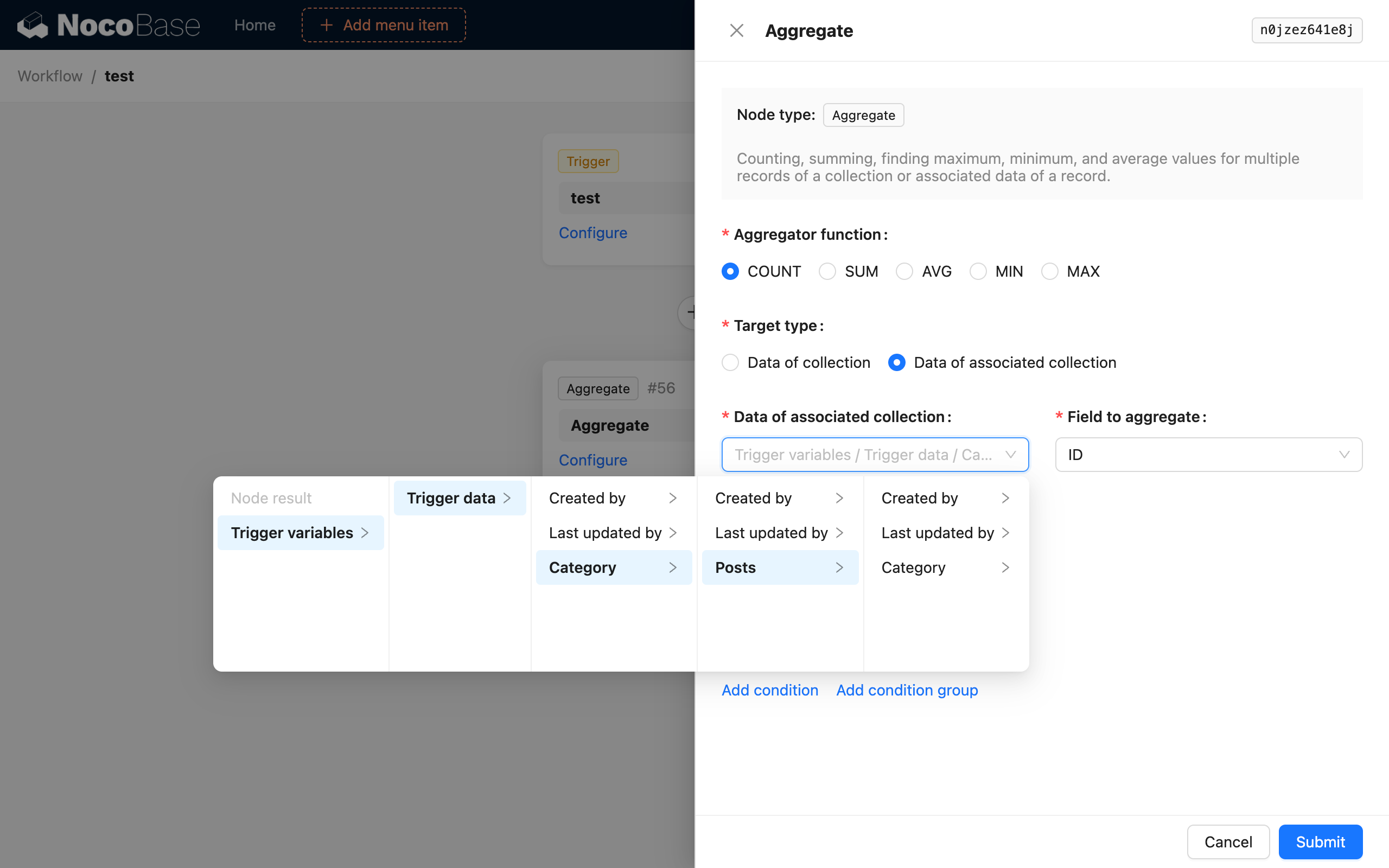
Ainsi, une fois le flux de travail déclenché, le nœud de requête d'agrégation comptera le nombre total d'articles dans la catégorie de l'article nouvellement ajouté et enregistrera ce résultat comme sortie du nœud.
Si vous avez besoin d'utiliser les données de relation du déclencheur d'événement de collection, vous devez configurer les champs pertinents dans la section « Précharger les données associées » du déclencheur, sinon vous ne pourrez pas les sélectionner.