

Dit document is vertaald door AI. Voor onnauwkeurigheden, raadpleeg de Engelse versie
Aggregatiequery
Workflow: Aggregatie-queryknooppuntCommunity Edition+Introductie
Wordt gebruikt om een aggregatiefunctiequery uit te voeren op gegevens in een collectie die aan bepaalde voorwaarden voldoen, en retourneert de bijbehorende statistische resultaten. Dit is vaak nuttig voor het verwerken van statistische gegevens voor rapporten.
De implementatie van de node is gebaseerd op database-aggregatiefuncties. Momenteel ondersteunt het alleen statistieken voor één enkel veld van een collectie. Het numerieke resultaat van de statistieken wordt opgeslagen in de uitvoer van de node voor gebruik door volgende nodes.
Installatie
Ingebouwde plugin, geen installatie vereist.
Node aanmaken
In de workflow configuratie-interface klikt u op de plusknop ('+') in de workflow om een 'Aggregatiequery'-node toe te voegen:
Nodeconfiguratie
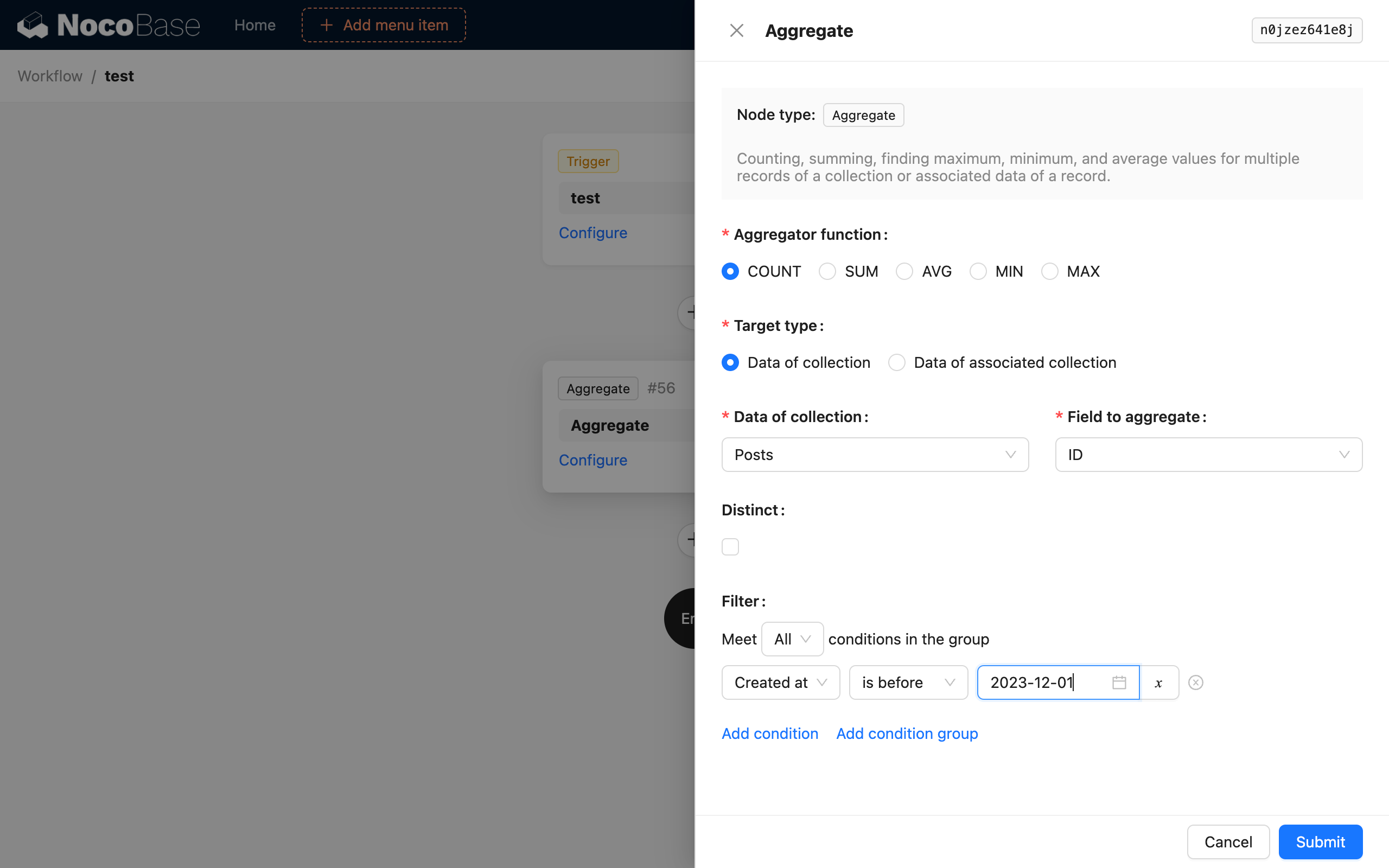
Aggregatiefunctie
Ondersteunt 5 aggregatiefuncties uit SQL: COUNT, SUM, AVG, MIN en MAX. Kies er één om een aggregatiequery op de gegevens uit te voeren.
Doeltype
Het doel van de aggregatiequery kan op twee manieren worden geselecteerd. De ene manier is om direct de doelcollectie en een van de velden ervan te selecteren. De andere manier is om via een bestaand data-object in de workflowcontext de gerelateerde één-op-meer collectie en het bijbehorende veld te selecteren om de aggregatiequery uit te voeren.
Uniek (Distinct)
Dit is DISTINCT in SQL. Het veld voor deduplicatie is hetzelfde als het geselecteerde collectieveld. Het selecteren van verschillende velden voor deze twee wordt momenteel niet ondersteund.
Filtervoorwaarden
Vergelijkbaar met de filtervoorwaarden bij een normale collectiequery, kunt u contextvariabelen uit de workflow gebruiken.
Voorbeeld
Het aggregatiedoel 'Collectiegegevens' is relatief eenvoudig te begrijpen. Hier gebruiken we 'het tellen van het totale aantal artikelen in een categorie nadat een nieuw artikel is toegevoegd' als voorbeeld om het gebruik van het aggregatiedoel 'Gerelateerde collectiegegevens' te introduceren.
Maak eerst twee collecties aan: 'Artikelen' en 'Categorieën'. De collectie 'Artikelen' heeft een veel-op-één relatieveld dat verwijst naar de collectie 'Categorieën', en er wordt ook een omgekeerd één-op-veel relatieveld van 'Categorieën' naar 'Artikelen' aangemaakt:
| Veldnaam | Type |
|---|---|
| Titel | Enkele regel tekst |
| Categorie | Veel-op-één (Categorieën) |
| Veldnaam | Type |
|---|---|
| Categorienaam | Enkele regel tekst |
| Artikelen | Eén-op-veel (Artikelen) |
Maak vervolgens een workflow aan die wordt geactiveerd door een collectiegebeurtenis. Selecteer dat deze wordt geactiveerd nadat nieuwe gegevens zijn toegevoegd aan de collectie 'Artikelen'.
Voeg daarna een aggregatiequery-node toe en configureer deze als volgt:
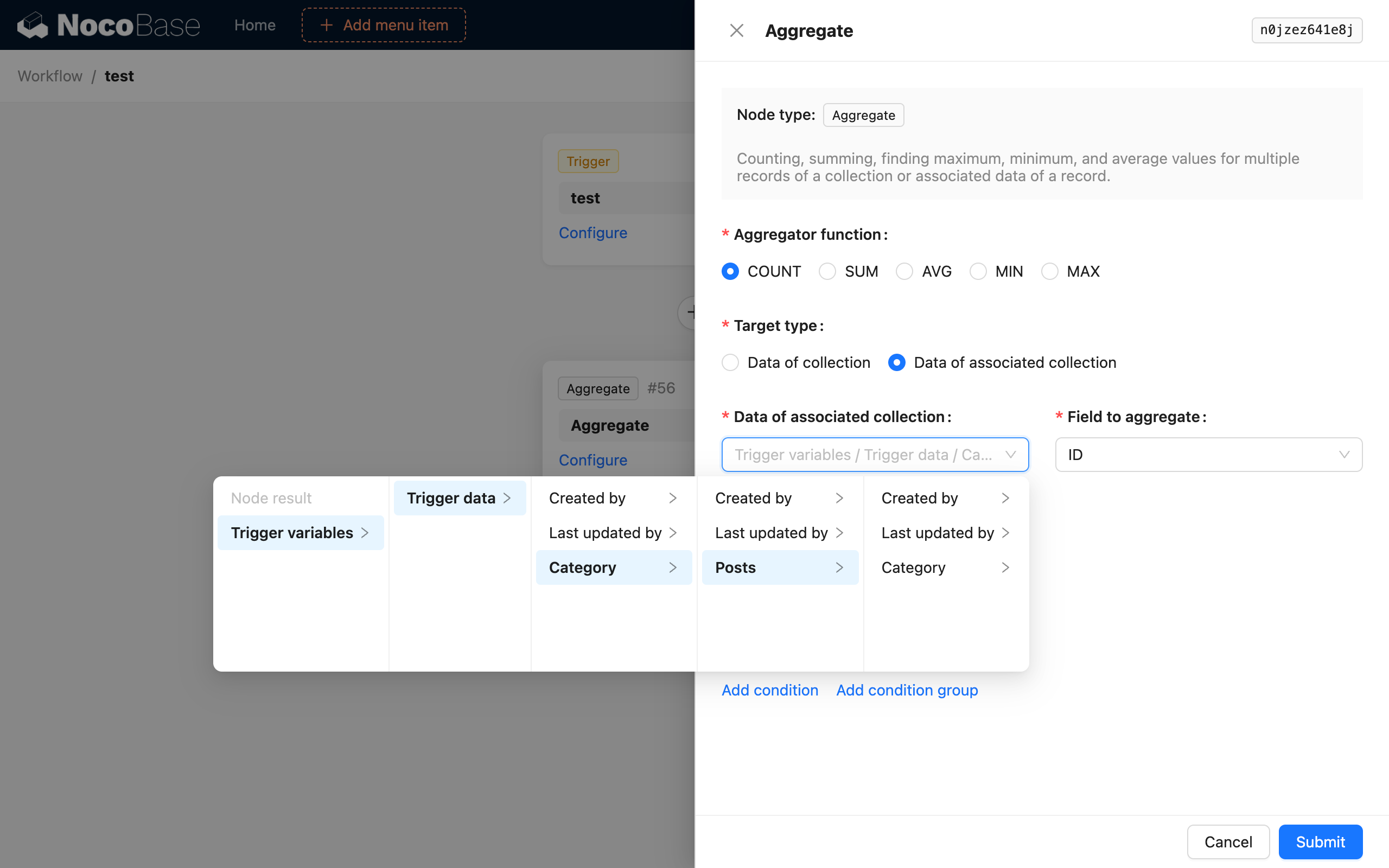
Op deze manier, nadat de workflow is geactiveerd, zal de aggregatiequery-node het aantal artikelen tellen in de categorie van het nieuw toegevoegde artikel en dit opslaan als het resultaat van de node.
Als u de relatiegegevens van de collectiegebeurtenistrigger wilt gebruiken, moet u de relevante velden configureren in de sectie 'Gerelateerde gegevens voorladen' van de trigger, anders kunnen deze niet worden geselecteerd.