

Tento dokument byl přeložen umělou inteligencí. V případě nepřesností se prosím obraťte na anglickou verzi
Agregační dotaz
Workflow: Agregační uzelCommunity Edition+Úvod
Slouží k provádění dotazů s agregačními funkcemi nad daty v kolekci, která splňují určité podmínky, a vrací odpovídající statistické výsledky. Často se používá pro zpracování statistických dat souvisejících s reporty.
Implementace uzlu je založena na databázových agregačních funkcích. V současné době podporuje pouze statistiky nad jedním polem jedné kolekce. Číselný výsledek statistik se uloží do výstupu uzlu pro použití následnými uzly.
Instalace
Vestavěný plugin, nevyžaduje instalaci.
Vytvoření uzlu
V rozhraní konfigurace pracovního postupu klikněte na tlačítko plus („+“) v toku a přidejte uzel „Agregační dotaz“:
Konfigurace uzlu
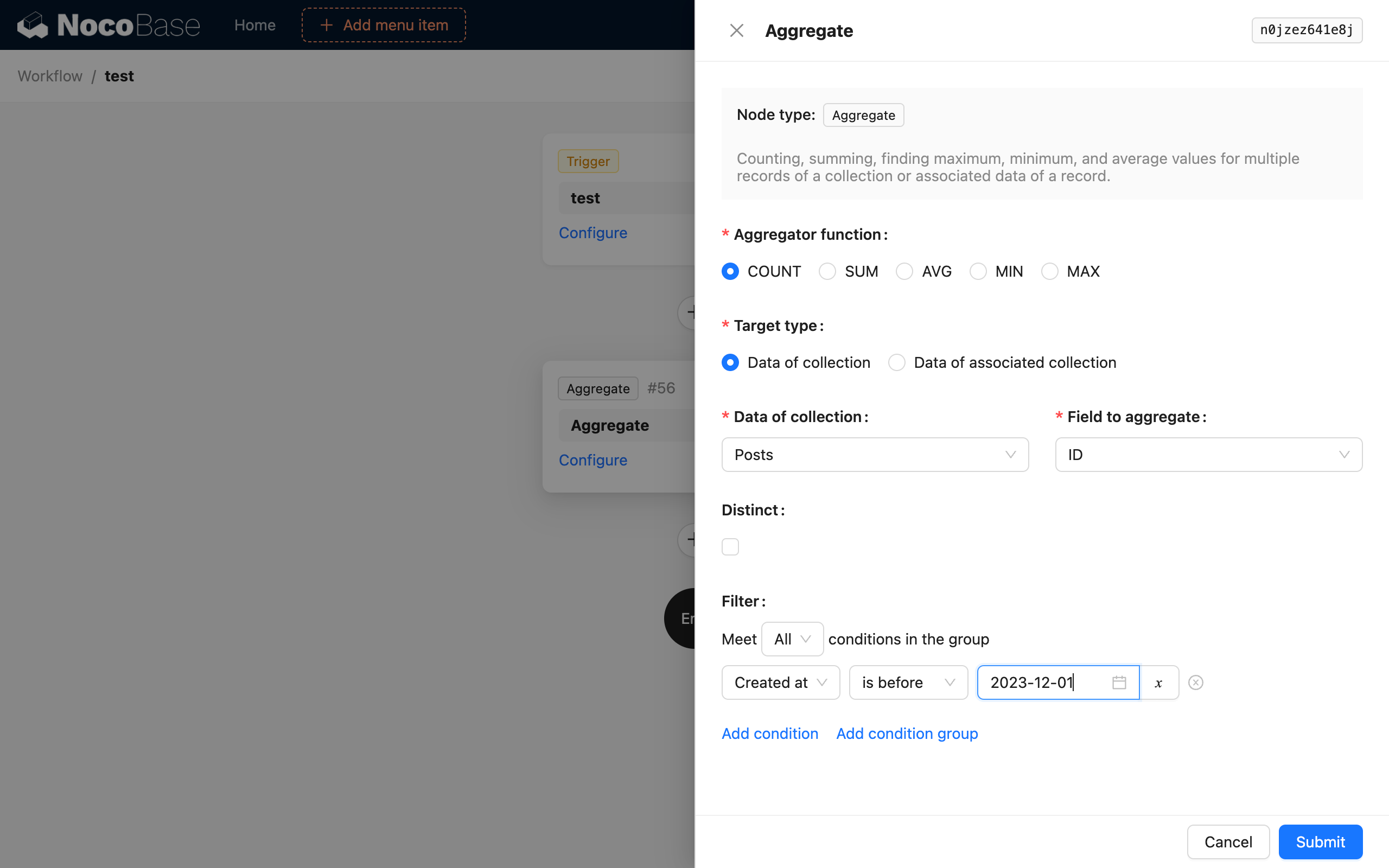
Agregační funkce
Podporuje 5 agregačních funkcí z SQL: COUNT, SUM, AVG, MIN a MAX. Vyberte jednu z nich pro provedení agregačního dotazu nad daty.
Typ cíle
Cíl agregačního dotazu lze vybrat ve dvou režimech. Jeden je přímý výběr cílové kolekce a jednoho z jejích polí. Druhý je výběr prostřednictvím existujícího datového objektu v kontextu pracovního postupu, kde vyberete jeho kolekci s relací jedna k mnoha a pole, pro provedení agregačního dotazu.
Distinct
Jedná se o DISTINCT v SQL. Pole pro odstranění duplicit je stejné jako vybrané pole kolekce. Výběr různých polí pro tyto dva účely v současné době není podporován.
Podmínky filtru
Podobně jako u podmínek filtru při běžném dotazu na kolekci, můžete použít kontextové proměnné pracovního postupu.
Příklad
Agregační cíl „Data kolekce“ je poměrně snadno pochopitelný. Zde použijeme příklad „počítání celkového počtu článků v kategorii po přidání nového článku“ k představení použití agregačního cíle „Data související kolekce“.
Nejprve vytvořte dvě kolekce: „Články“ a „Kategorie“. Kolekce Články má pole s relací mnoho k jedné, které odkazuje na kolekci Kategorie, a zároveň je vytvořeno reverzní pole s relací jedna k mnoha z Kategorie na Články:
| Název pole | Typ |
|---|---|
| Název | Jednořádkový text |
| Kategorie | Mnoho k jedné (Kategorie) |
| Název pole | Typ |
|---|---|
| Název kategorie | Jednořádkový text |
| Články | Jedna k mnoha (Články) |
Dále vytvořte pracovní postup spouštěný událostí kolekce. Nastavte jej tak, aby se spustil po přidání nových dat do kolekce Články.
Poté přidejte uzel agregačního dotazu a nakonfigurujte jej následovně:
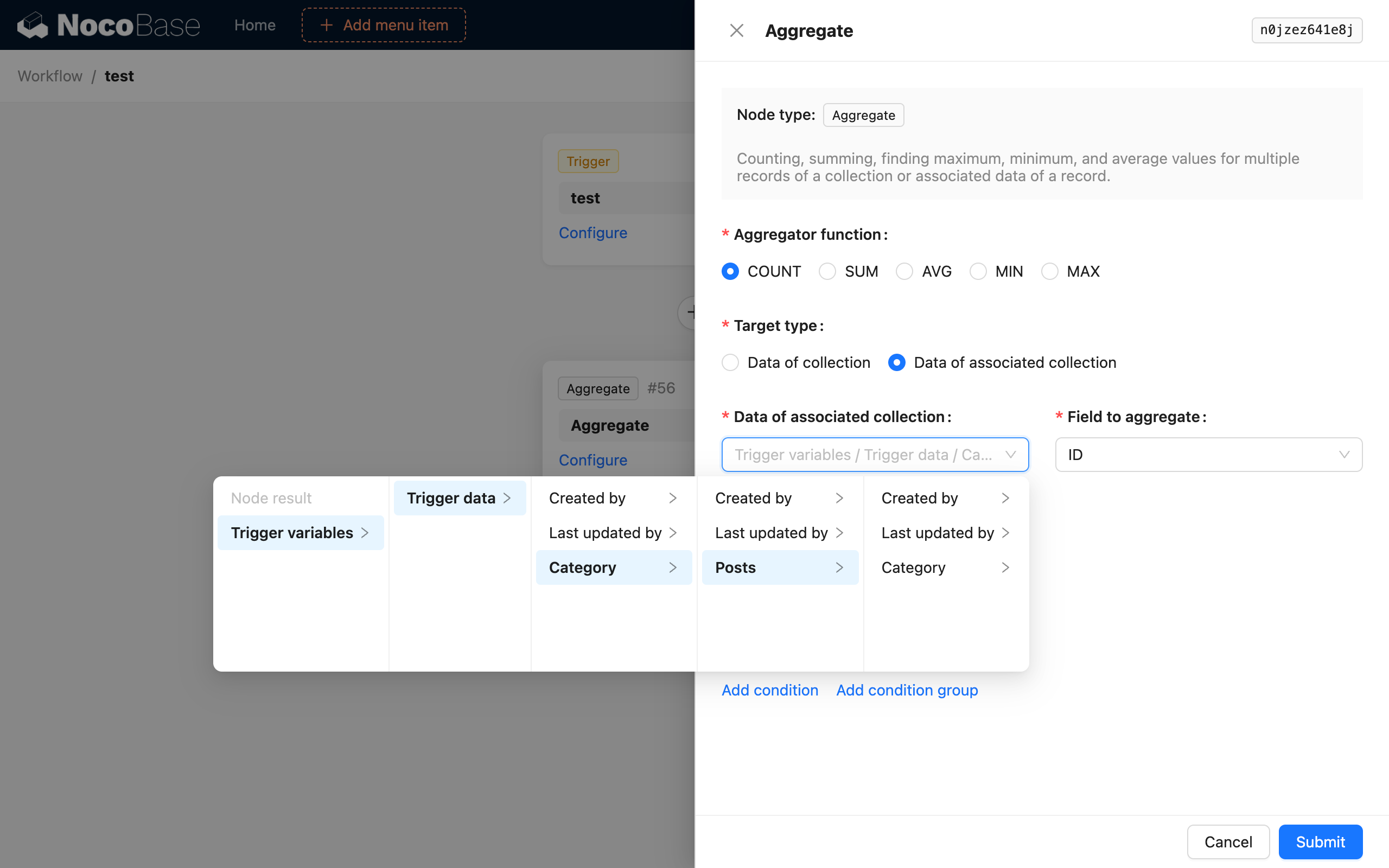
Tímto způsobem, po spuštění pracovního postupu, uzel agregačního dotazu spočítá počet všech článků v kategorii nově přidaného článku a uloží jej jako výsledek uzlu.
Pokud potřebujete použít relační data ze spouštěče události kolekce, musíte v sekci „Přednačíst související data“ ve spouštěči nakonfigurovat příslušná pole, jinak je nebude možné vybrat.