

Esta documentación ha sido traducida automáticamente por IA.
Consulta de Agregación
Flujo de trabajo: Nodo de consulta de agregaciónCommunity Edition+Introducción
Se utiliza para realizar consultas de funciones de agregación sobre los datos de una colección que cumplen ciertas condiciones, y devuelve los resultados estadísticos correspondientes. Es una herramienta común para procesar datos estadísticos relacionados con informes.
La implementación de este nodo se basa en funciones de agregación de bases de datos. Actualmente, solo admite estadísticas sobre un único campo de una colección. El resultado numérico de estas estadísticas se guardará en la salida del nodo para que lo utilicen los nodos posteriores.
Instalación
Plugin integrado, no requiere instalación.
Crear Nodo
En la interfaz de configuración del flujo de trabajo, haga clic en el botón de más ('+') en el flujo para añadir un nodo de "Consulta de Agregación":
Configuración del Nodo
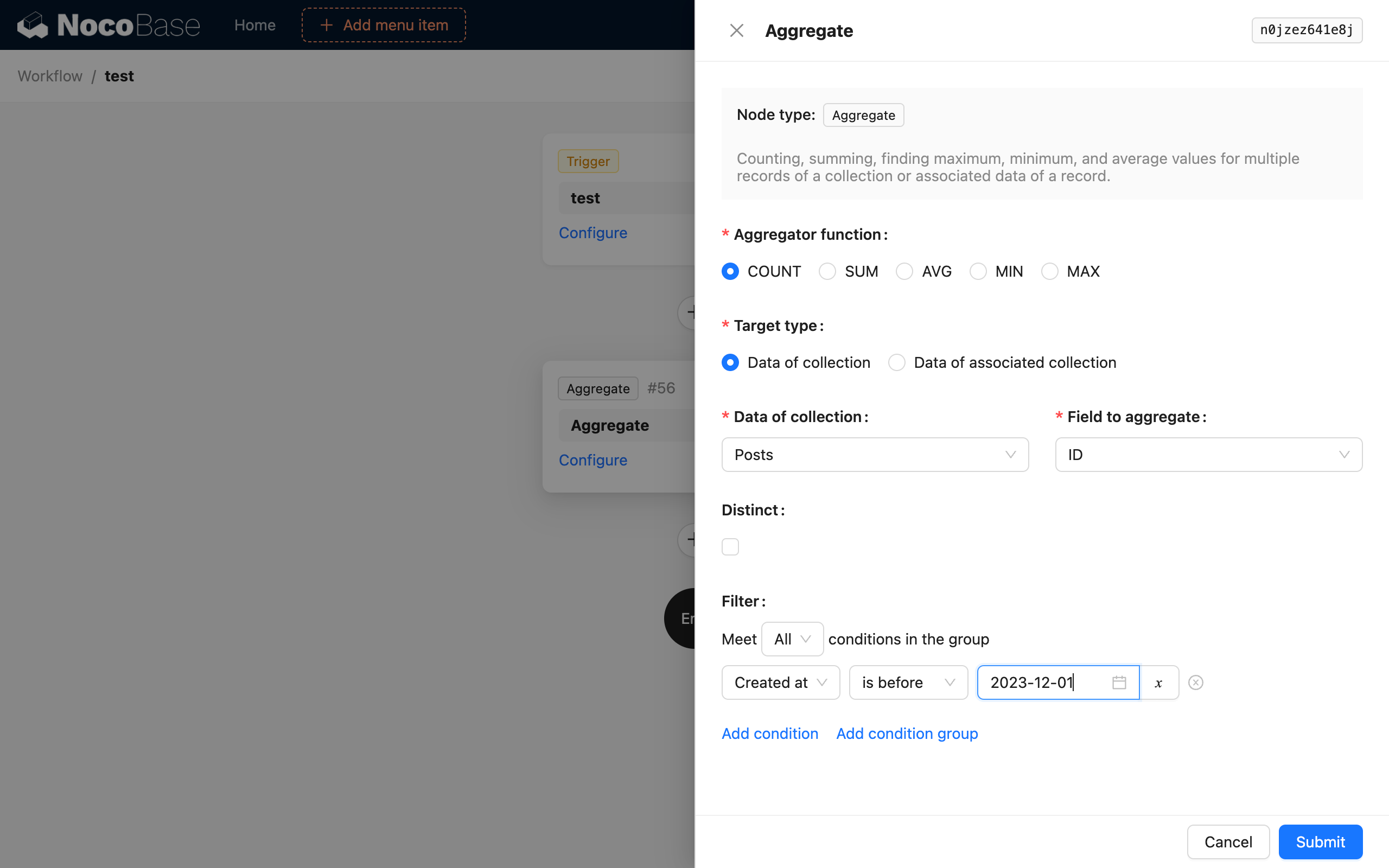
Función de Agregación
Admite 5 funciones de agregación de SQL: COUNT, SUM, AVG, MIN y MAX. Seleccione una de ellas para realizar una consulta de agregación sobre los datos.
Tipo de Objetivo
El objetivo de la consulta de agregación se puede seleccionar de dos modos. Uno es seleccionar directamente la colección de destino y uno de sus campos. El otro es seleccionar, a través de un objeto de datos existente en el contexto del flujo de trabajo, su colección relacionada de uno a muchos y el campo correspondiente, para realizar la consulta de agregación.
Distinto
Es el DISTINCT de SQL. El campo para la deduplicación es el mismo que el campo de la colección seleccionada. Actualmente, no se admite seleccionar campos diferentes para ambos.
Condiciones de Filtro
Similar a las condiciones de filtro en una consulta de colección normal, puede utilizar variables de contexto del flujo de trabajo.
Ejemplo
El objetivo de agregación "Datos de la colección" es relativamente fácil de entender. Aquí, utilizaremos "contar el número total de artículos en una categoría después de añadir un nuevo artículo" como ejemplo para presentar el uso del objetivo de agregación "Datos de la colección asociada".
Primero, cree dos colecciones: "Artículos" y "Categorías". La colección de Artículos tiene un campo de relación de muchos a uno que apunta a la colección de Categorías, y también se crea un campo de relación inversa de uno a muchos de Categorías a Artículos:
| Nombre del Campo | Tipo |
|---|---|
| Título | Texto de una línea |
| Categoría | Muchos a Uno (Categorías) |
| Nombre del Campo | Tipo |
|---|---|
| Nombre de Categoría | Texto de una línea |
| Artículos | Uno a Muchos (Artículos) |
A continuación, cree un flujo de trabajo activado por un evento de colección. Seleccione que se active después de que se añadan nuevos datos a la colección de Artículos.
Luego, añada un nodo de consulta de agregación y configúrelo de la siguiente manera:
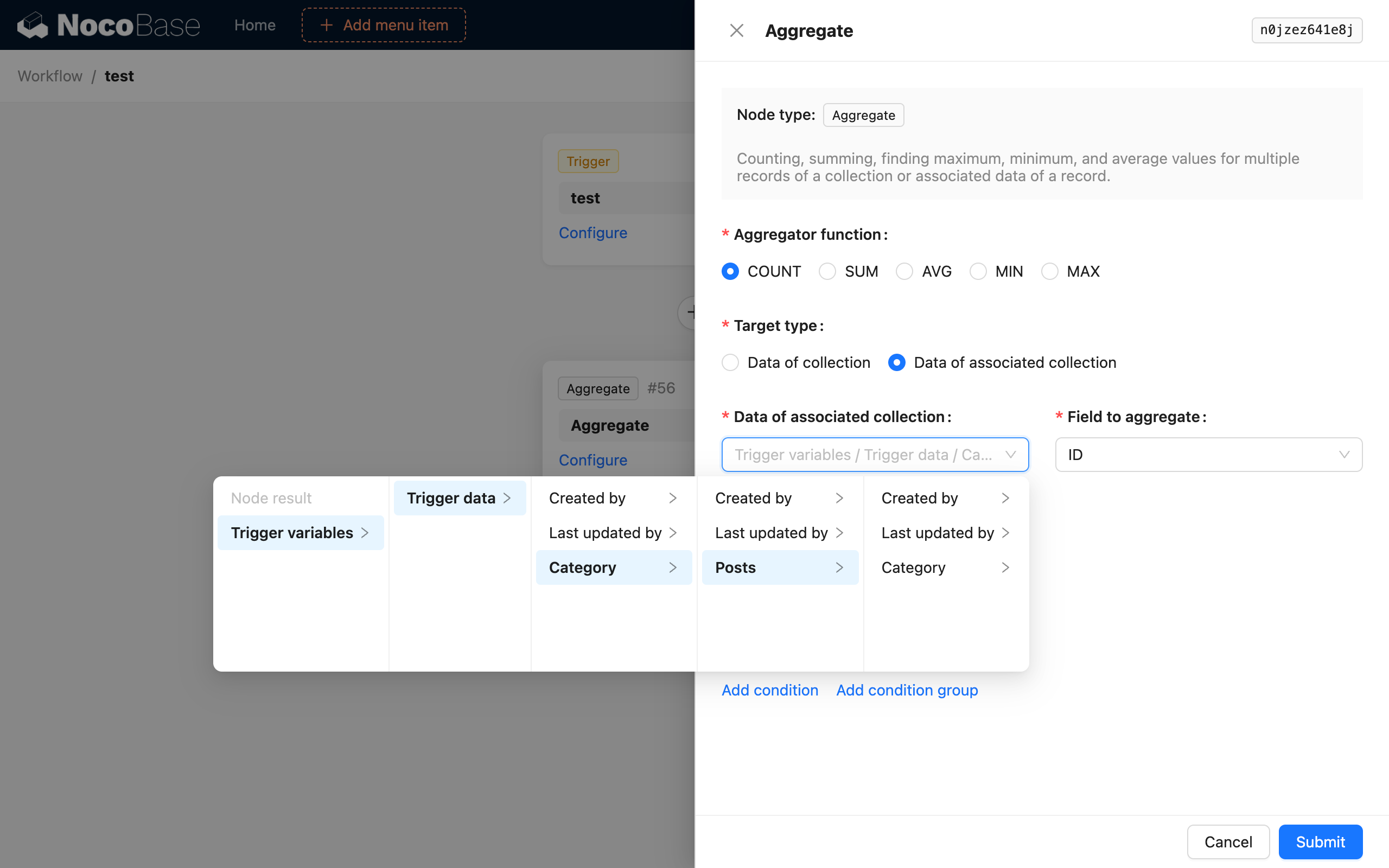
De esta manera, después de que se active el flujo de trabajo, el nodo de consulta de agregación contará el número de todos los artículos en la categoría del artículo recién añadido y lo guardará como resultado del nodo.
Si necesita utilizar los datos de relación del activador de eventos de colección, debe configurar los campos relevantes en la sección "Precargar datos asociados" del activador; de lo contrario, no podrá seleccionarlos.