

Questa documentazione è stata tradotta automaticamente dall'IA.
Query di Aggregazione
Workflow: Nodo aggregazioneCommunity Edition+Introduzione
Viene utilizzato per eseguire query con funzioni di aggregazione sui dati di una collezione che soddisfano determinate condizioni e restituisce i risultati statistici corrispondenti. È spesso impiegato per elaborare dati statistici relativi a report.
L'implementazione del nodo si basa sulle funzioni di aggregazione del database. Attualmente, supporta solo statistiche su un singolo campo di una collezione. Il risultato numerico delle statistiche verrà salvato nell'output del nodo per essere utilizzato dai nodi successivi.
Installazione
È un plugin integrato, non richiede installazione.
Creazione del Nodo
Nell'interfaccia di configurazione del flusso di lavoro, clicchi sul pulsante più ('+') nel flusso per aggiungere un nodo "Query di Aggregazione":
Configurazione del Nodo
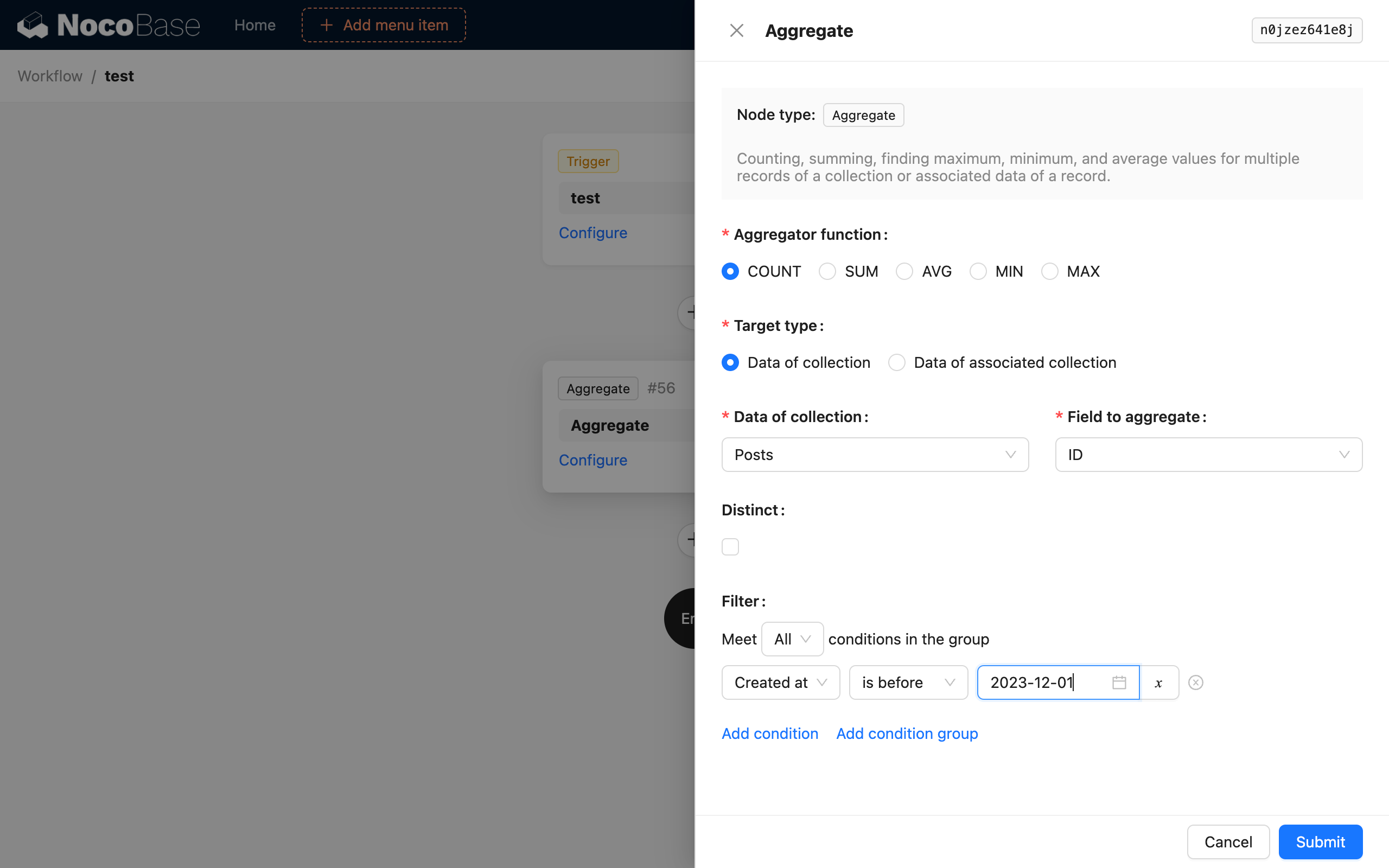
Funzione di Aggregazione
Supporta 5 funzioni di aggregazione SQL: COUNT, SUM, AVG, MIN e MAX. Selezioni una di esse per eseguire una query di aggregazione sui dati.
Tipo di Destinazione
La destinazione della query di aggregazione può essere selezionata in due modalità. Una consiste nel selezionare direttamente la collezione di destinazione e uno dei suoi campi. L'altra consiste nel selezionare la sua collezione correlata uno-a-molti e il campo attraverso un oggetto dati esistente nel contesto del flusso di lavoro per eseguire la query di aggregazione.
Distinti
Corrisponde a DISTINCT in SQL. Il campo per la deduplicazione è lo stesso del campo della collezione selezionata. Attualmente, non è supportata la selezione di campi diversi per questi due.
Condizioni di Filtro
Simili alle condizioni di filtro in una normale query di collezione, può utilizzare le variabili di contesto del flusso di lavoro.
Esempio
L'obiettivo di aggregazione "Dati della collezione" è relativamente facile da comprendere. Qui, useremo come esempio "il conteggio del numero totale di articoli in una categoria dopo l'aggiunta di un nuovo articolo" per illustrare l'uso dell'obiettivo di aggregazione "Dati della collezione associata".
Innanzitutto, crei due collezioni: "Articoli" e "Categorie". La collezione Articoli ha un campo di relazione molti-a-uno che punta alla collezione Categorie, e viene anche creato un campo di relazione inverso uno-a-molti da Categorie ad Articoli:
| Nome Campo | Tipo |
|---|---|
| Titolo | Testo su riga singola |
| Categoria | Molti-a-Uno (Categorie) |
| Nome Campo | Tipo |
|---|---|
| Nome Categoria | Testo su riga singola |
| Articoli | Uno-a-Molti (Articoli) |
Successivamente, crei un flusso di lavoro attivato da un evento di collezione. Lo configuri per attivarsi dopo l'aggiunta di nuovi dati alla collezione Articoli.
Poi, aggiunga un nodo di query di aggregazione e lo configuri come segue:
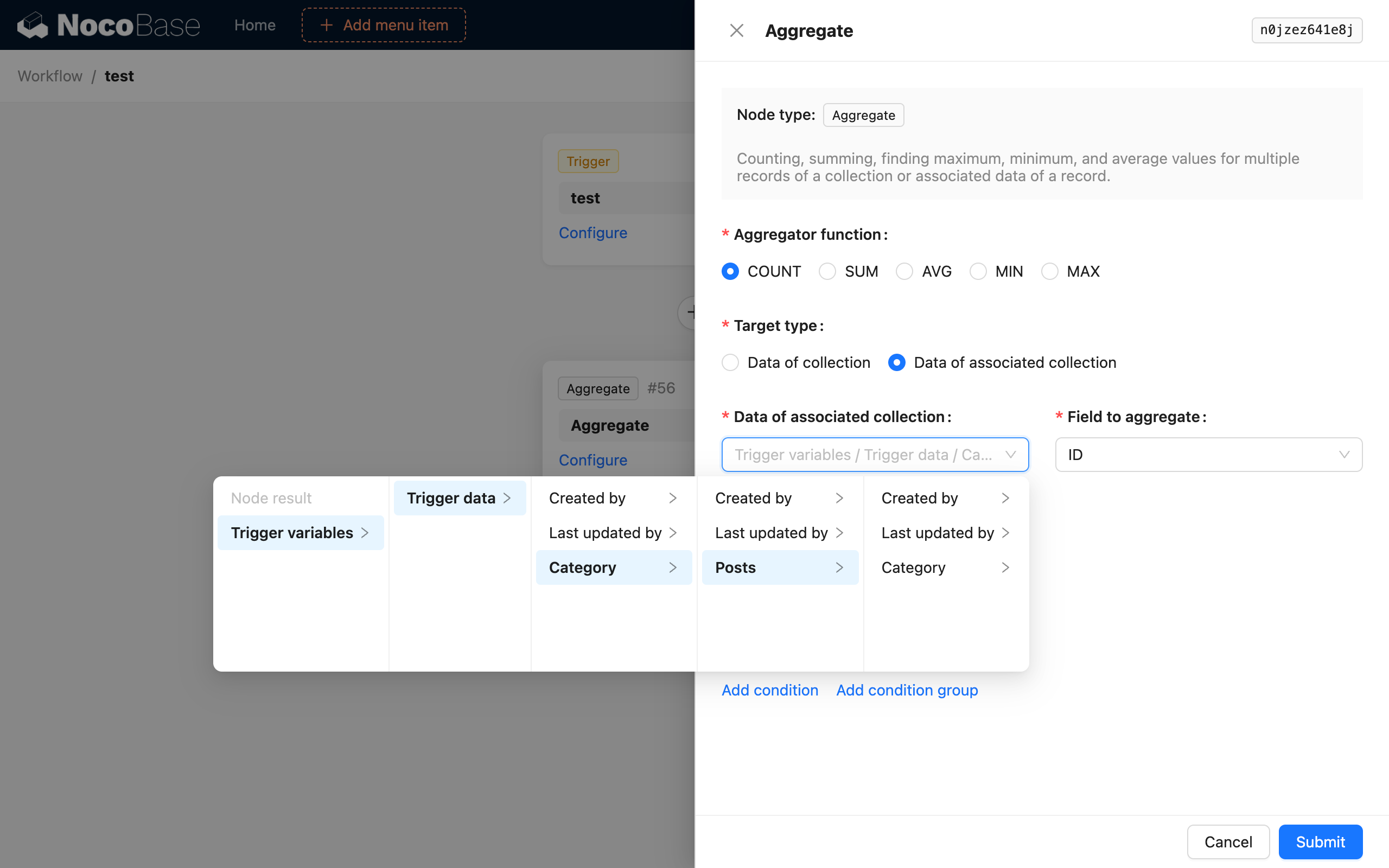
In questo modo, dopo l'attivazione del flusso di lavoro, il nodo di query di aggregazione conterà il numero di tutti gli articoli nella categoria dell'articolo appena aggiunto e lo salverà come risultato del nodo.
Se ha bisogno di utilizzare i dati di relazione dal trigger di evento della collezione, deve configurare i campi pertinenti nella sezione "Precarica dati associati" del trigger, altrimenti non sarà possibile selezionarli.