

Diese Dokumentation wurde automatisch von KI übersetzt.
Aggregatabfrage
Workflow: Aggregations-KnotenCommunity Edition+Einführung
Dieser Knoten wird verwendet, um Aggregatfunktionsabfragen auf Daten in einer Sammlung durchzuführen, die bestimmte Bedingungen erfüllen, und die entsprechenden statistischen Ergebnisse zurückzugeben. Er wird häufig zur Verarbeitung von statistischen Daten für Berichte eingesetzt.
Die Implementierung dieses Knotens basiert auf Datenbank-Aggregatfunktionen. Derzeit unterstützt er nur Statistiken für ein einzelnes Feld einer Sammlung. Der numerische Wert des statistischen Ergebnisses wird im Knotenergebnis gespeichert und kann von nachfolgenden Knoten weiterverwendet werden.
Installation
Dies ist ein integriertes Plugin, das keine Installation erfordert.
Knoten erstellen
In der Workflow-Konfiguration klicken Sie auf das Plus-Symbol ('+') im Workflow, um einen „Aggregatabfrage“-Knoten hinzuzufügen:
Knotenkonfiguration
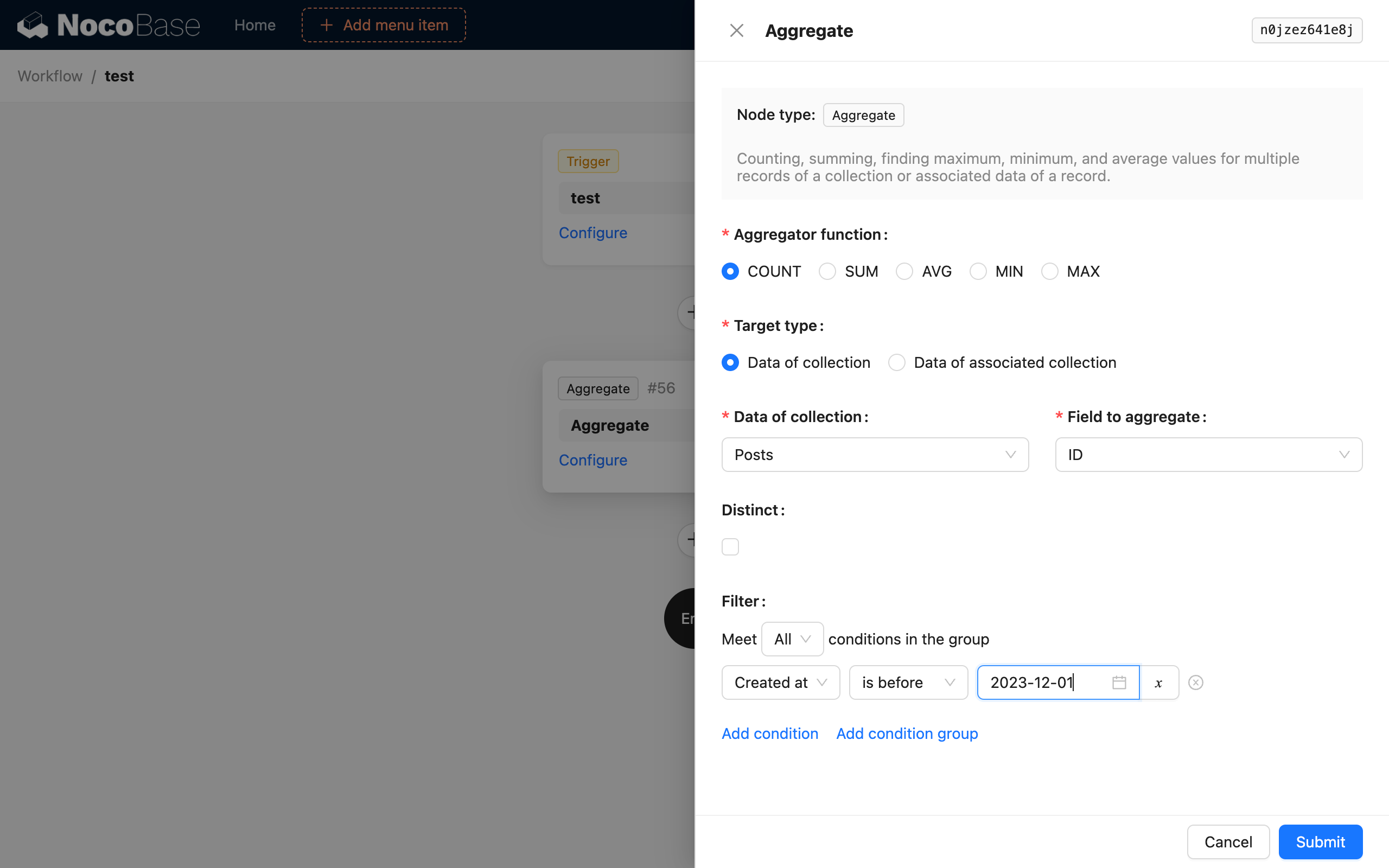
Aggregatfunktion
Es werden 5 Aggregatfunktionen aus SQL unterstützt: COUNT, SUM, AVG, MIN und MAX. Wählen Sie eine davon aus, um eine Aggregatabfrage auf die Daten durchzuführen.
Zieltyp
Das Ziel der Aggregatabfrage kann auf zwei Arten ausgewählt werden: Entweder wählen Sie direkt die Ziel-Sammlung und eines ihrer Felder aus, oder Sie wählen über ein vorhandenes Datenobjekt im Workflow-Kontext die zugehörige 1:n-Beziehungs-Sammlung und deren Feld für die Aggregatabfrage aus.
Distinct
Dies entspricht DISTINCT in SQL. Das Feld für die Duplikatsentfernung ist dasselbe wie das ausgewählte Sammlungsfeld. Es wird derzeit nicht unterstützt, unterschiedliche Felder für diese beiden auszuwählen.
Filterbedingungen
Ähnlich wie bei den Filterbedingungen einer normalen Sammlungsabfrage können Sie Kontextvariablen aus dem Workflow verwenden.
Beispiel
Das Aggregationsziel „Sammlungsdaten“ ist relativ einfach zu verstehen. Hier erläutern wir die Verwendung des Aggregationsziels „Verknüpfte Sammlungsdaten“ am Beispiel der Zählung der Gesamtzahl der Artikel in einer Kategorie, nachdem ein neuer Artikel hinzugefügt wurde.
Zuerst erstellen Sie zwei Sammlungen: „Artikel“ und „Kategorien“. Die Sammlung „Artikel“ enthält ein n:1-Beziehungsfeld, das auf die Kategorie-Sammlung verweist. Gleichzeitig wird ein umgekehrtes 1:n-Beziehungsfeld von „Kategorien“ zu „Artikel“ erstellt:
| Feldname | Typ |
|---|---|
| Titel | Einzeiliger Text |
| Zugehörige Kategorie | n:1 (Kategorien) |
| Feldname | Typ |
|---|---|
| Kategoriename | Einzeiliger Text |
| Enthaltene Artikel | 1:n (Artikel) |
Als Nächstes erstellen Sie einen Workflow, der durch ein Sammlungsereignis ausgelöst wird. Wählen Sie aus, dass er ausgelöst wird, nachdem neue Daten zur Sammlung „Artikel“ hinzugefügt wurden.
Danach fügen Sie einen Aggregatabfrage-Knoten hinzu und konfigurieren ihn wie folgt:
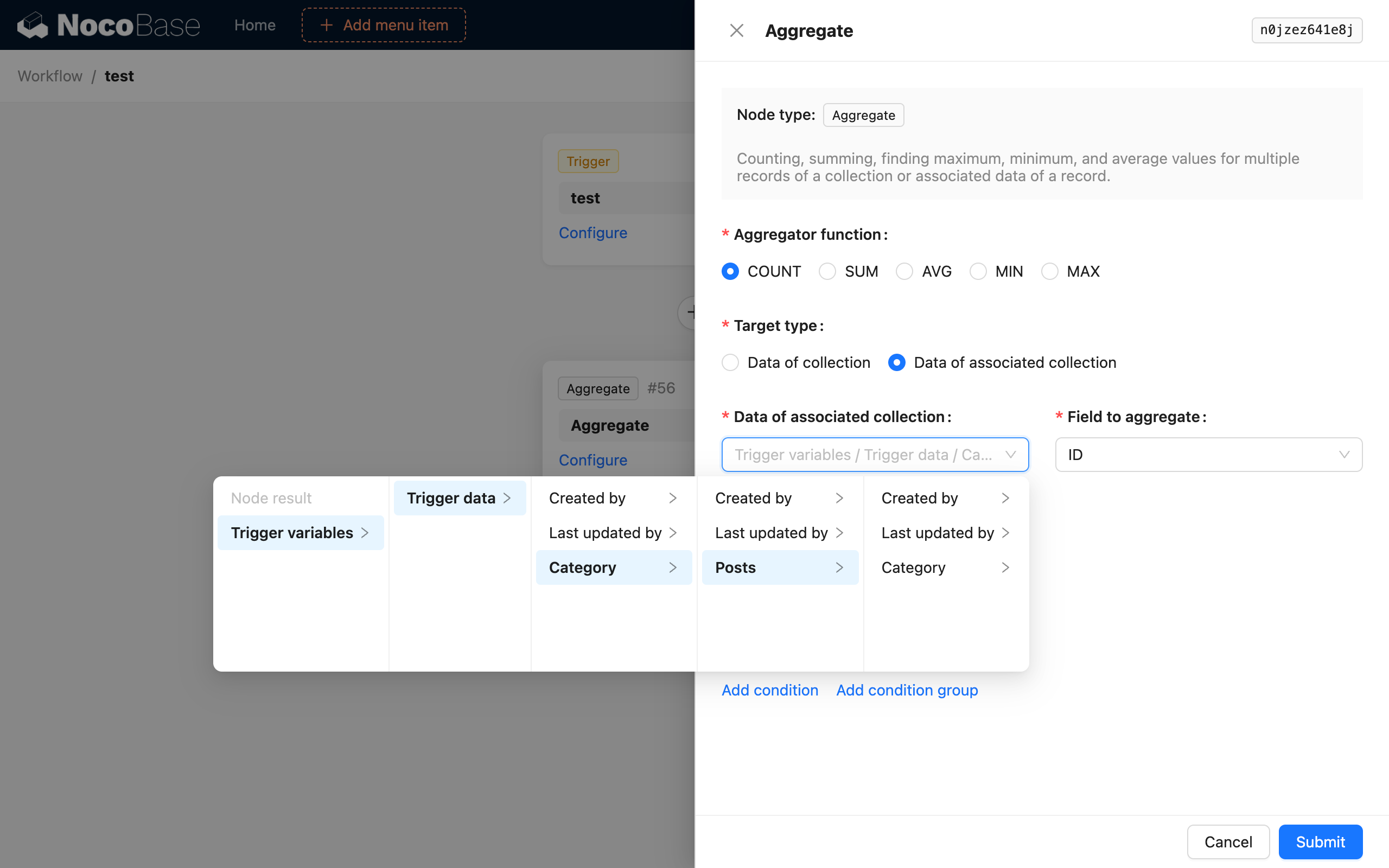
Auf diese Weise zählt der Aggregatabfrage-Knoten nach dem Auslösen des Workflows die Anzahl aller Artikel in der Kategorie des neu hinzugefügten Artikels und speichert dies als Knotenergebnis.
Wenn Sie die Beziehungsdaten des Sammlungsereignis-Triggers verwenden möchten, müssen Sie die entsprechenden Felder im Abschnitt „Verknüpfte Daten vorladen“ des Triggers konfigurieren. Andernfalls können diese nicht ausgewählt werden.