

Ця документація була автоматично перекладена штучним інтелектом.
Агрегаційний запит
Workflow: Вузол агрегаціїCommunity Edition+Вступ
Використовується для виконання запитів з агрегаційними функціями до даних у колекції, що відповідають певним умовам, та повернення відповідних статистичних результатів. Часто застосовується для обробки статистичних даних для звітів.
Реалізація цього вузла базується на агрегаційних функціях баз даних. Наразі він підтримує статистику лише для одного поля колекції. Числовий результат статистики буде збережено у вихідних даних вузла для використання наступними вузлами.
Встановлення
Вбудований плагін, встановлення не потрібне.
Створення вузла
В інтерфейсі конфігурації робочого процесу натисніть кнопку плюса («+») у потоці, щоб додати вузол «Агрегаційний запит»:
Конфігурація вузла
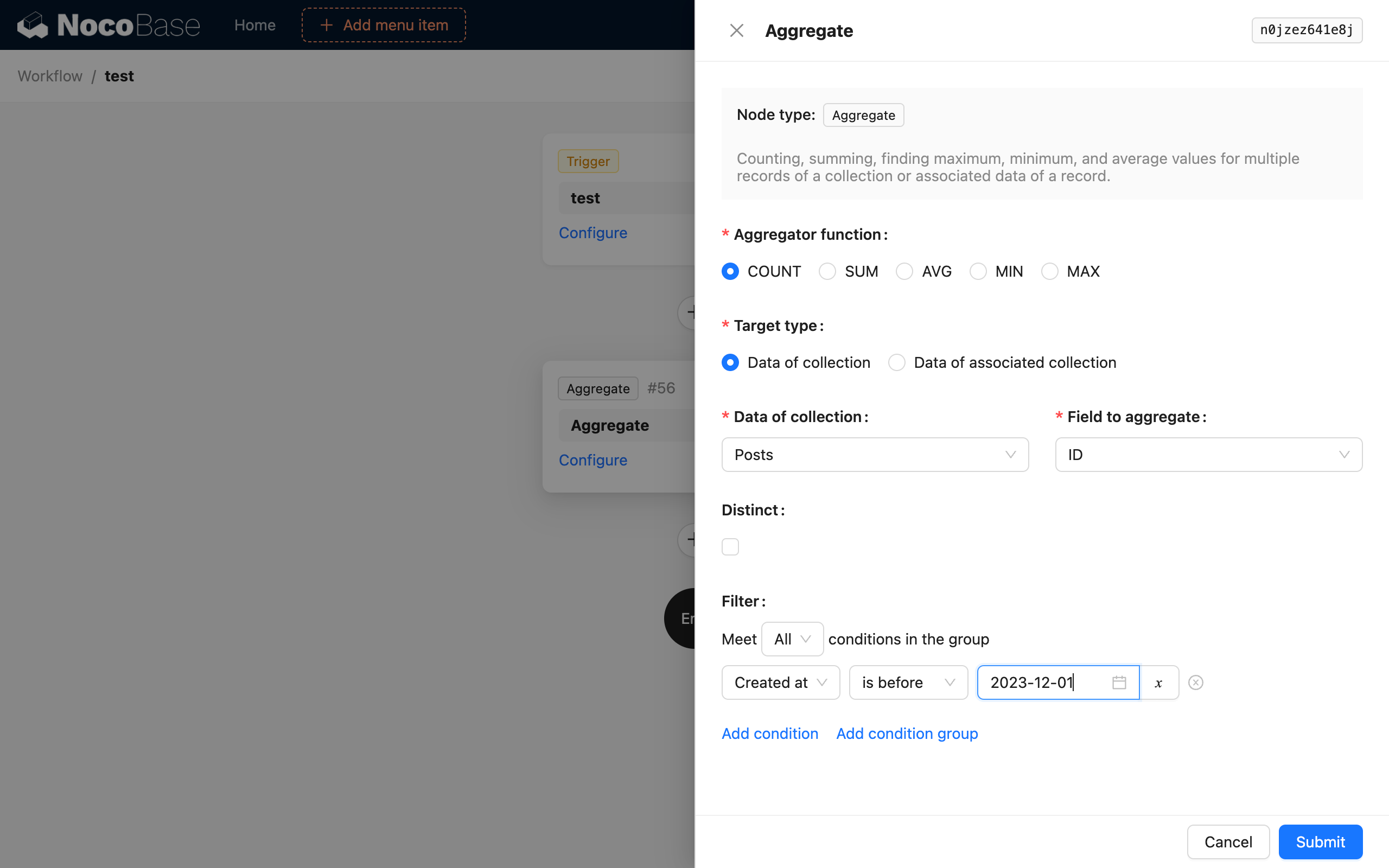
Агрегаційна функція
Підтримує 5 агрегаційних функцій SQL: COUNT, SUM, AVG, MIN та MAX. Виберіть одну з них для виконання агрегаційного запиту до даних.
Тип цілі
Ціль агрегаційного запиту можна вибрати двома способами. Один — це безпосередній вибір цільової колекції та одного з її полів. Інший — через наявний об'єкт даних у контексті робочого процесу вибрати пов'язану колекцію «один-до-багатьох» та її поле для виконання агрегаційного запиту.
Унікальні значення (Distinct)
Це DISTINCT в SQL. Поле для усунення дублікатів збігається з вибраним полем колекції. Наразі не підтримується вибір різних полів для цих двох.
Умови фільтрації
Подібно до умов фільтрації у звичайному запиті до колекції, ви можете використовувати контекстні змінні робочого процесу.
Приклад
Ціль агрегації «Дані колекції» досить легко зрозуміти. Тут ми розглянемо приклад «підрахунку загальної кількості статей у категорії після додавання нової статті», щоб продемонструвати використання цілі агрегації «Пов'язані дані колекції».
Спершу створіть дві колекції: «Статті» та «Категорії». Колекція «Статті» має поле зв'язку «багато-до-одного», що вказує на колекцію «Категорії», а також створено зворотне поле зв'язку «один-до-багатьох» від «Категорій» до «Статей»:
| Назва поля | Тип |
|---|---|
| Заголовок | Однорядковий текст |
| Категорія | Багато-до-одного (Категорії) |
| Назва поля | Тип |
|---|---|
| Назва категорії | Однорядковий текст |
| Статті | Один-до-багатьох (Статті) |
Далі створіть робочий процес, що запускається подією колекції. Виберіть запуск після додавання нових даних до колекції «Статті».
Потім додайте вузол агрегаційного запиту та налаштуйте його так:
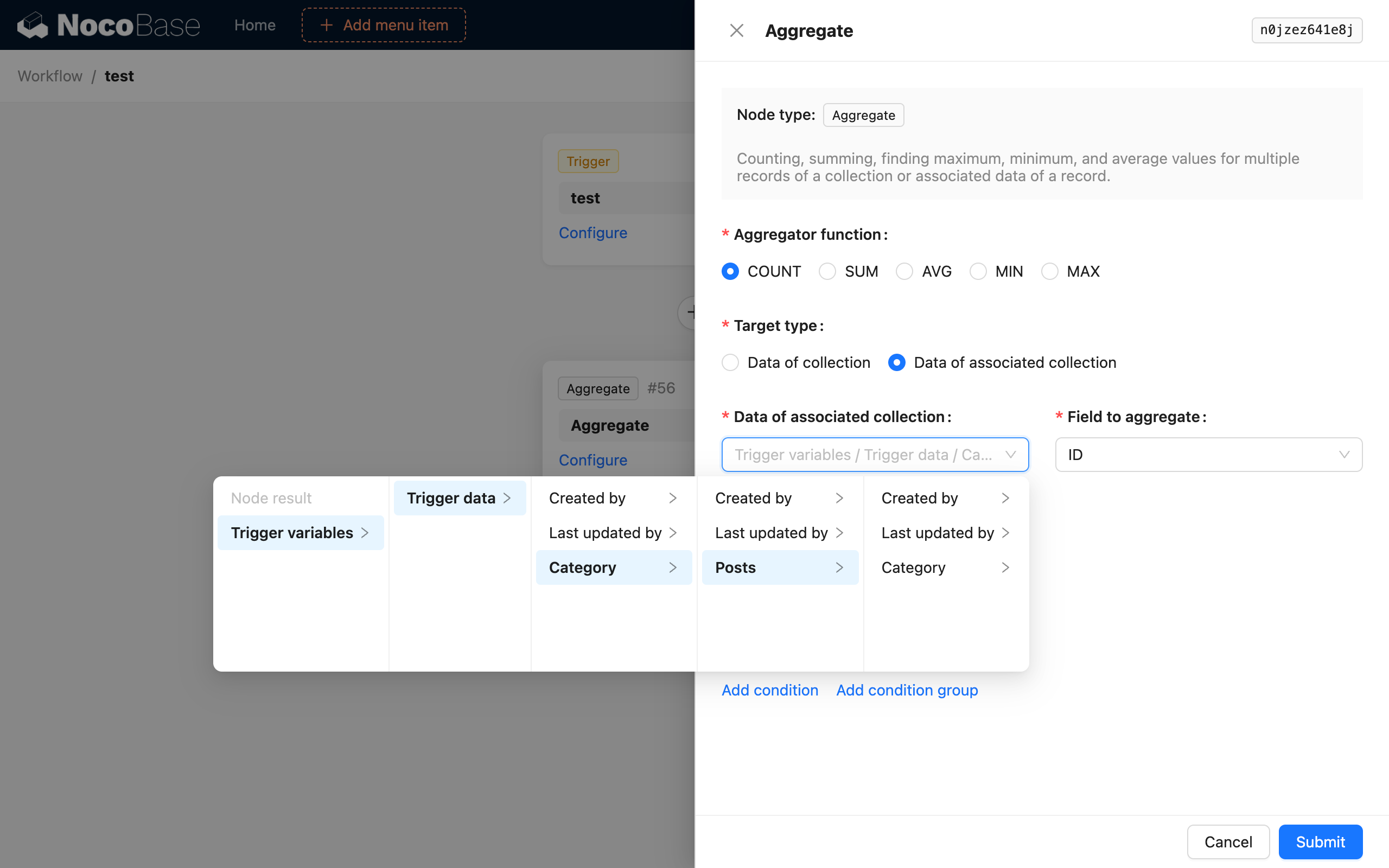
Таким чином, після запуску робочого процесу, вузол агрегаційного запиту підрахує кількість усіх статей у категорії нової доданої статті, і збереже це як результат вузла.
Якщо вам потрібно використовувати дані зв'язків з тригера події колекції, ви повинні налаштувати відповідні поля в розділі «Попереднє завантаження пов'язаних даних» у тригері, інакше їх неможливо буде вибрати.