

Эта документация была автоматически переведена ИИ.
Агрегирующий запрос
Workflow: Aggregate nodeCommunity Edition+Введение
Этот узел позволяет выполнять агрегирующие запросы к данным в коллекции, которые соответствуют заданным условиям, и возвращать соответствующие статистические результаты. Он часто используется для обработки статистических данных в отчетах.
Реализация узла основана на агрегирующих функциях базы данных. В настоящее время поддерживается только статистика по одному полю одной коллекции. Числовой результат статистики будет сохранен в выходных данных узла для использования последующими узлами.
Установка
Это встроенный плагин, поэтому установка не требуется.
Создание узла
В интерфейсе настройки рабочего процесса нажмите кнопку плюс («+») в потоке, чтобы добавить узел «Агрегирующий запрос»:
Настройка узла
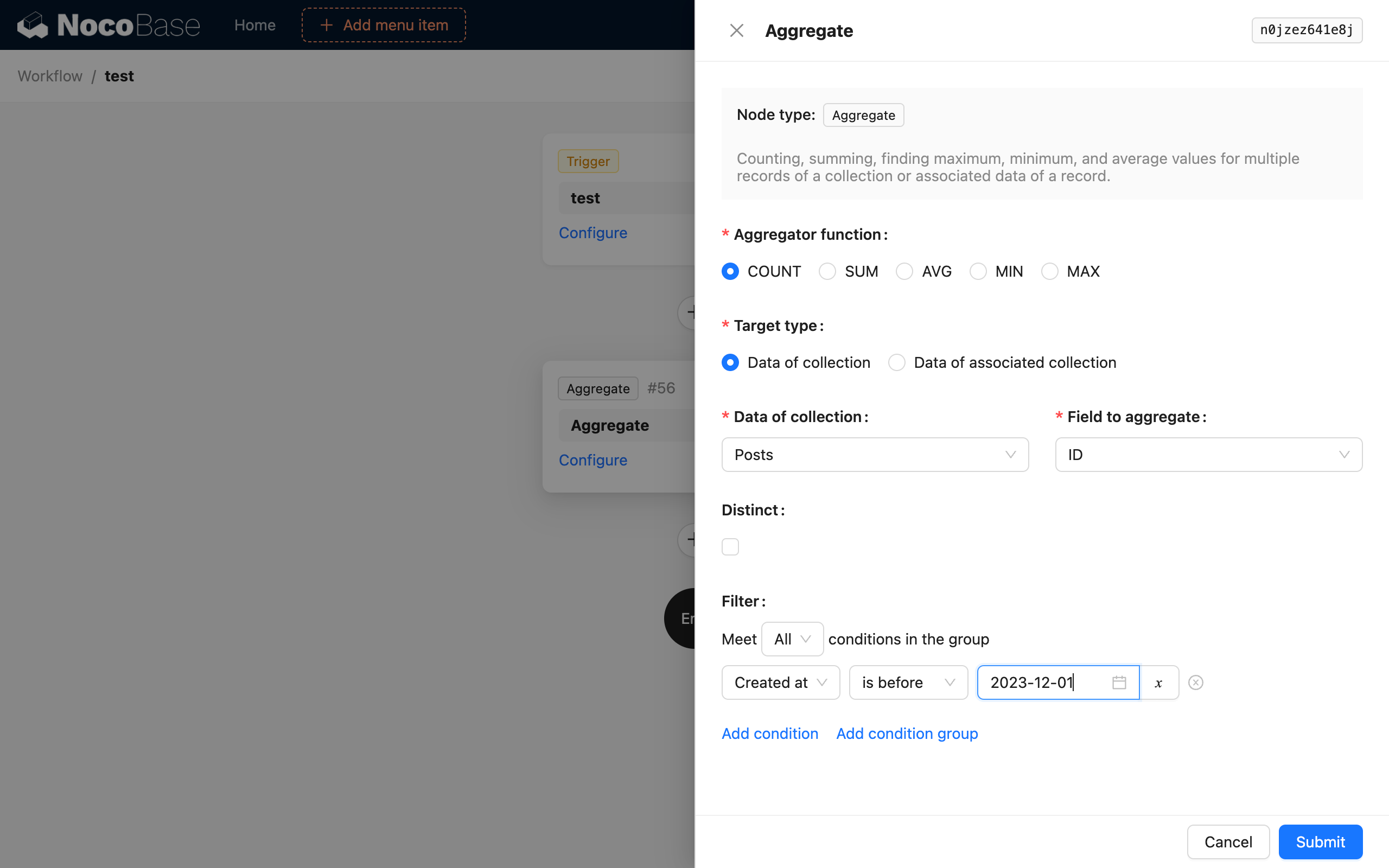
Агрегирующая функция
Поддерживается 5 агрегирующих функций SQL: COUNT, SUM, AVG, MIN и MAX. Выберите одну из них для выполнения агрегирующего запроса к данным.
Тип цели
Цель агрегирующего запроса можно выбрать в двух режимах. Первый — это прямой выбор целевой коллекции и одного из ее полей. Второй — это выбор связанной коллекции «один-ко-многим» и ее поля через существующий объект данных в контексте рабочего процесса для выполнения агрегирующего запроса.
DISTINCT
Это оператор DISTINCT в SQL. Поле для удаления дубликатов совпадает с выбранным полем коллекции. Выбор разных полей для этих двух опций в настоящее время не поддерживается.
Условия фильтрации
Подобно условиям фильтрации в обычном запросе к коллекции, вы можете использовать контекстные переменные рабочего процесса.
Пример
Цель агрегации «Данные коллекции» относительно проста для понимания. Здесь мы рассмотрим пример использования цели агрегации «Данные связанной коллекции» на примере «подсчета общего количества статей в категории после добавления новой статьи».
Сначала создайте две коллекции: «Статьи» и «Категории». Коллекция «Статьи» будет иметь поле отношения «многие-к-одному», указывающее на коллекцию «Категории», а также будет создано обратное поле отношения «один-ко-многим» от «Категорий» к «Статьям»:
| Название поля | Тип |
|---|---|
| Заголовок | Однострочный текст |
| Категория | Многие-к-одному (Категории) |
| Название поля | Тип |
|---|---|
| Название категории | Однострочный текст |
| Статьи | Один-ко-многим (Статьи) |
Далее создайте рабочий процесс, запускаемый событием коллекции. Выберите запуск после добавления новых данных в коллекцию «Статьи».
Затем добавьте узел агрегирующего запроса и настройте его следующим образом:
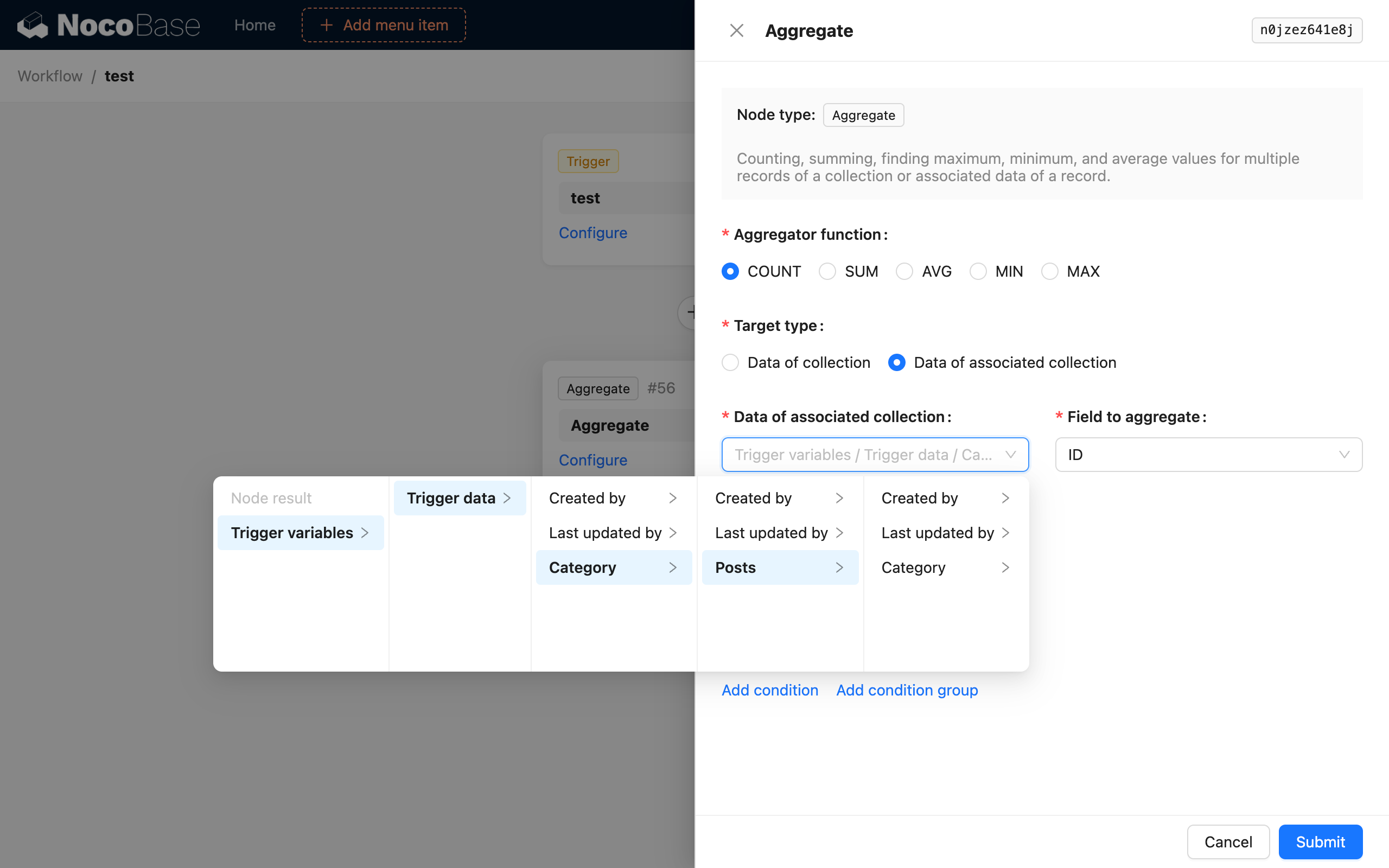
Таким образом, после запуска рабочего процесса узел агрегирующего запроса подсчитает количество всех статей в категории только что добавленной статьи и сохранит его в качестве результата узла.
Если вам необходимо использовать данные отношений из триггера события коллекции, вы должны настроить соответствующие поля в разделе «Предварительная загрузка связанных данных» триггера, иначе их нельзя будет выбрать.