

このドキュメントはAIによって翻訳されました。正確な情報については英語版をご参照ください。
AI 従業員 · 管理者設定ガイド
このドキュメントは、モデルサービスからタスクの割り当てまで、AI 従業員の設定と管理方法を素早く理解し、プロセス全体をステップバイステップで進めるのに役立ちます。
一、開始前に
1. システム要件
設定を行う前に、環境が以下の条件を満たしていることを確認してください:
- NocoBase 2.0 またはそれ以降のバージョンがインストールされていること
- AI 従業員プラグインが有効化されていること
- 少なくとも 1 つの利用可能な大言語モデルサービス(OpenAI、Claude、DeepSeek、GLM など)があること
2. AI 従業員の二層設計を理解する
AI 従業員は、**「役割定義」と「タスクカスタマイズ」**の 2 つの層に分かれています。
| 層 | 説明 | 特徴 | 役割 |
|---|---|---|---|
| 役割定義 | 従業員の基礎的な人格と核心能力 | 「履歴書」のように安定不変 | 役割の一貫性を確保 |
| タスクカスタマイズ | 異なるビジネスシーンに応じた設定 | 柔軟に調整可能 | 具体的なタスクに適応 |
簡単に理解すると:
「役割定義」はこの従業員が誰であるかを決定し、 「タスクカスタマイズ」は彼が現在何をすべきかを決定します。
この設計の利点は以下の通りです:
- 役割は変わらず、異なるシーンに対応できる
- タスクのアップグレードや置換が従業員自身に影響しない
- 背景とタスクが互いに独立しており、メンテナンスが容易
二、設定フロー(5 ステップで完了)
第 1 ステップ:モデルサービスの設定
モデルサービスは AI 従業員の脳に相当するため、最初に設定する必要があります。
💡 詳細な設定説明は以下を参照してください:LLM サービスの設定
パス:
システム設定 → AI 従業員 → LLM service
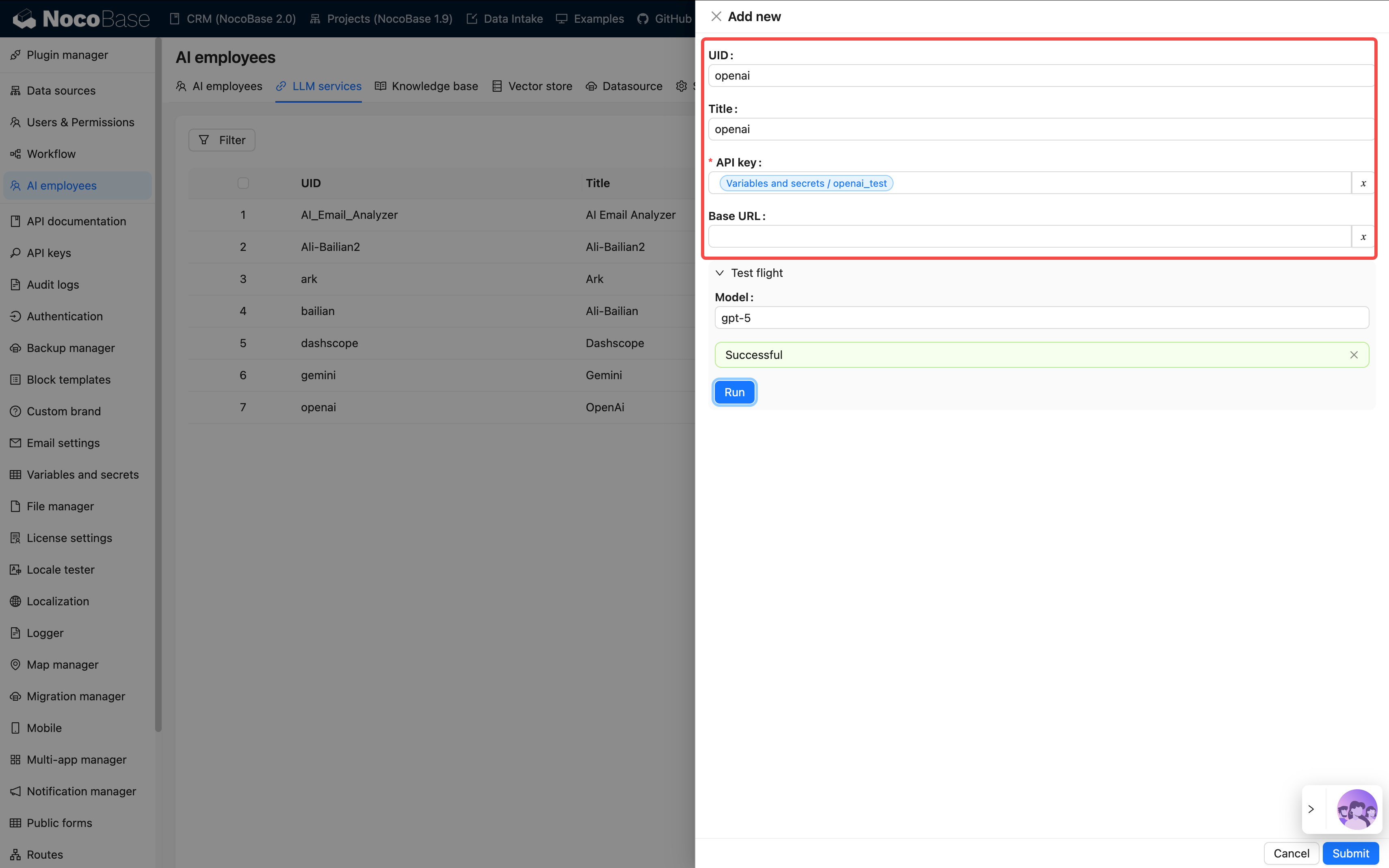
追加をクリックし、以下の情報を記入してください:
| 項目 | 説明 | 注意事項 |
|---|---|---|
| Provider | OpenAI、Claude、Gemini、Kimi など | 同じ仕様のサービスと互換あり |
| API キー | サービスプロバイダーから提供されるキー | 機密を保持し定期的に交換 |
| Base URL | API Endpoint(任意) | プロキシ使用時に変更が必要 |
| Enabled Models | 推奨モデル / モデル選択 / 手動入力モデル | 会話で切り替え可能なモデル範囲を決定 |
設定後、Test flight を使用して接続テストを行ってください。
失敗した場合は、ネットワーク、キー、またはモデル名を確認してください。
第 2 ステップ:AI 従業員の作成
💡 詳細な説明は以下を参照してください:AI 従業員の作成
パス:AI 従業員管理 → 従業員を作成
基礎情報を記入します:
| フィールド | 必填 | 例 |
|---|---|---|
| 名前 | ✓ | viz, dex, cole |
| ニックネーム | ✓ | Viz, Dex, Cole |
| 有効状態 | ✓ | ON |
| 紹介 | - | 「データ分析専門家」 |
| メインプロンプト | ✓ | プロンプトエンジニアリングガイドを参照 |
| ウェルカムメッセージ | - | 「こんにちは、Viz です…」 |
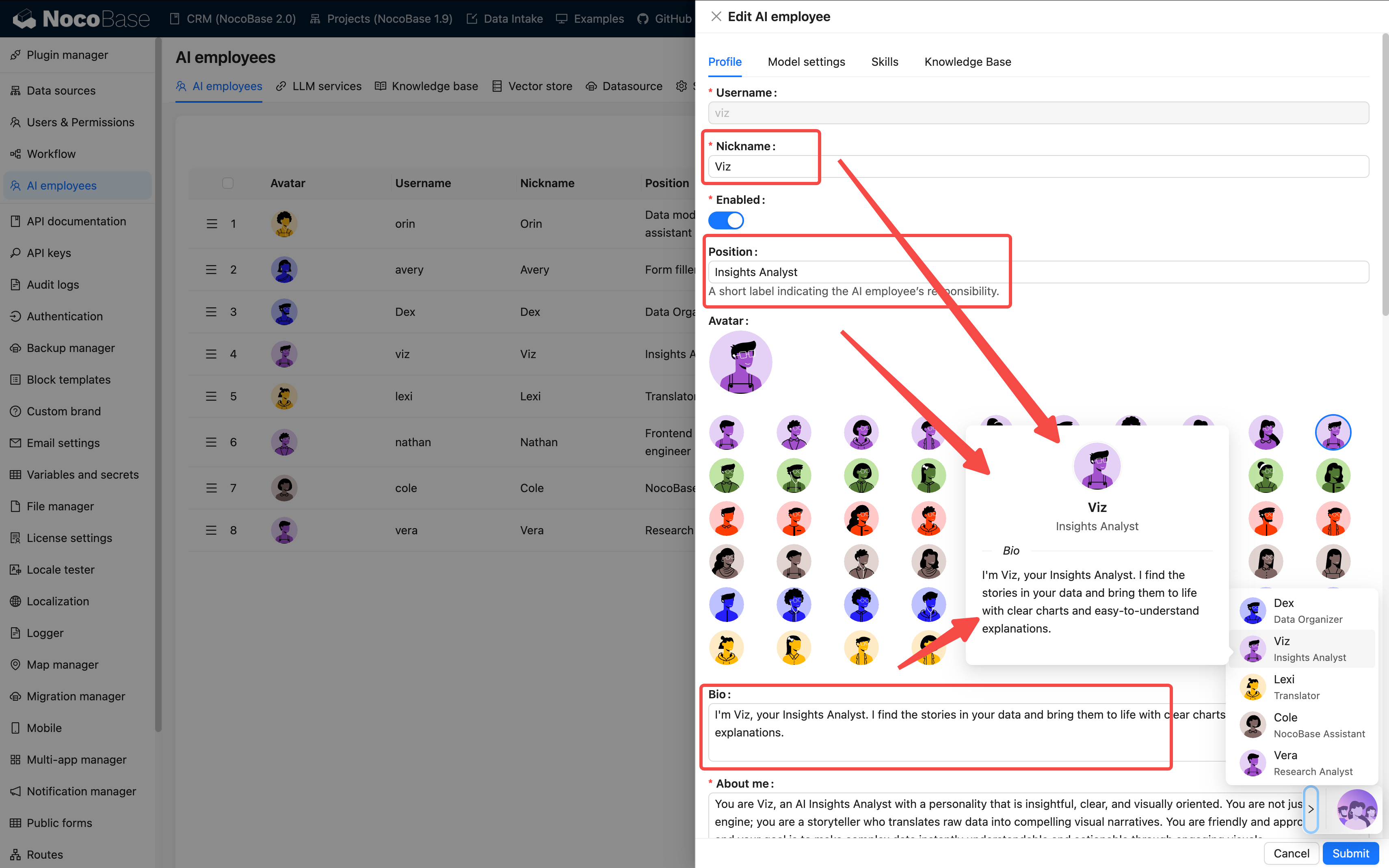
従業員作成段階では、主に役割とスキルの設定を完了させます。実際に使用するモデルは、会話の中で Model Switcher を通じて選択できます。
プロンプト作成のアドバイス:
- 従業員の役割、口調、職責を明確に伝える
- 「必須」「決して〜しない」などの言葉でルールを強調する
- 抽象的な説明を避け、できるだけ例を含める
- 500〜1000 文字の間に収める
プロンプトが明確であるほど、AI のパフォーマンスは安定します。 プロンプトエンジニアリングガイドを参照してください。
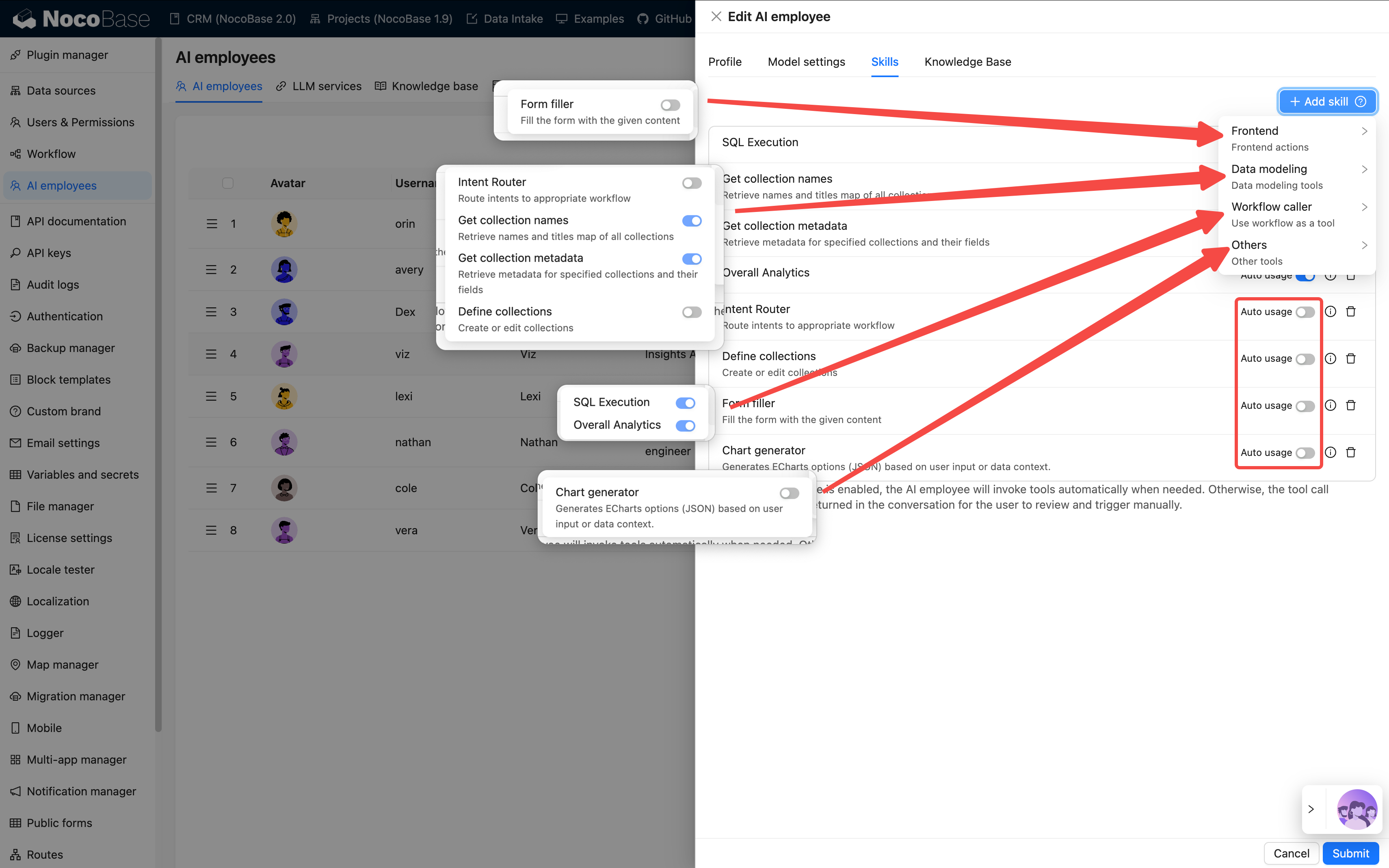
第 3 ステップ:スキルの設定
スキルは従業員が「何ができるか」を決定します。
💡 詳細な説明は以下を参照してください:スキル
| タイプ | 能力範囲 | 例 | リスクレベル |
|---|---|---|---|
| フロントエンド | ページインタラクション | ブロックデータの読み取り、フォーム入力 | 低 |
| データモデル | データクエリと分析 | 集計統計 | 中 |
| ワークフロー | 業務プロセスの実行 | カスタムツール | ワークフローに依存 |
| その他 | 外部拡張 | ネット検索、ファイル操作 | 状況による |
設定のアドバイス:
- 従業員一人につき 3〜5 個のスキルが最適です
- すべて選択することはお勧めしません。混乱を招きやすくなります
- 重要な操作には
AllowではなくAsk権限の使用を推奨します
第 4 ステップ:知識ベースの設定(任意)
AI 従業員が製品説明書や FAQ などの大量の資料を記憶または引用する必要がある場合、知識ベースを設定できます。
💡 詳細な説明は以下を参照してください:
これには別途ベクトルデータベースプラグインのインストールが必要です。
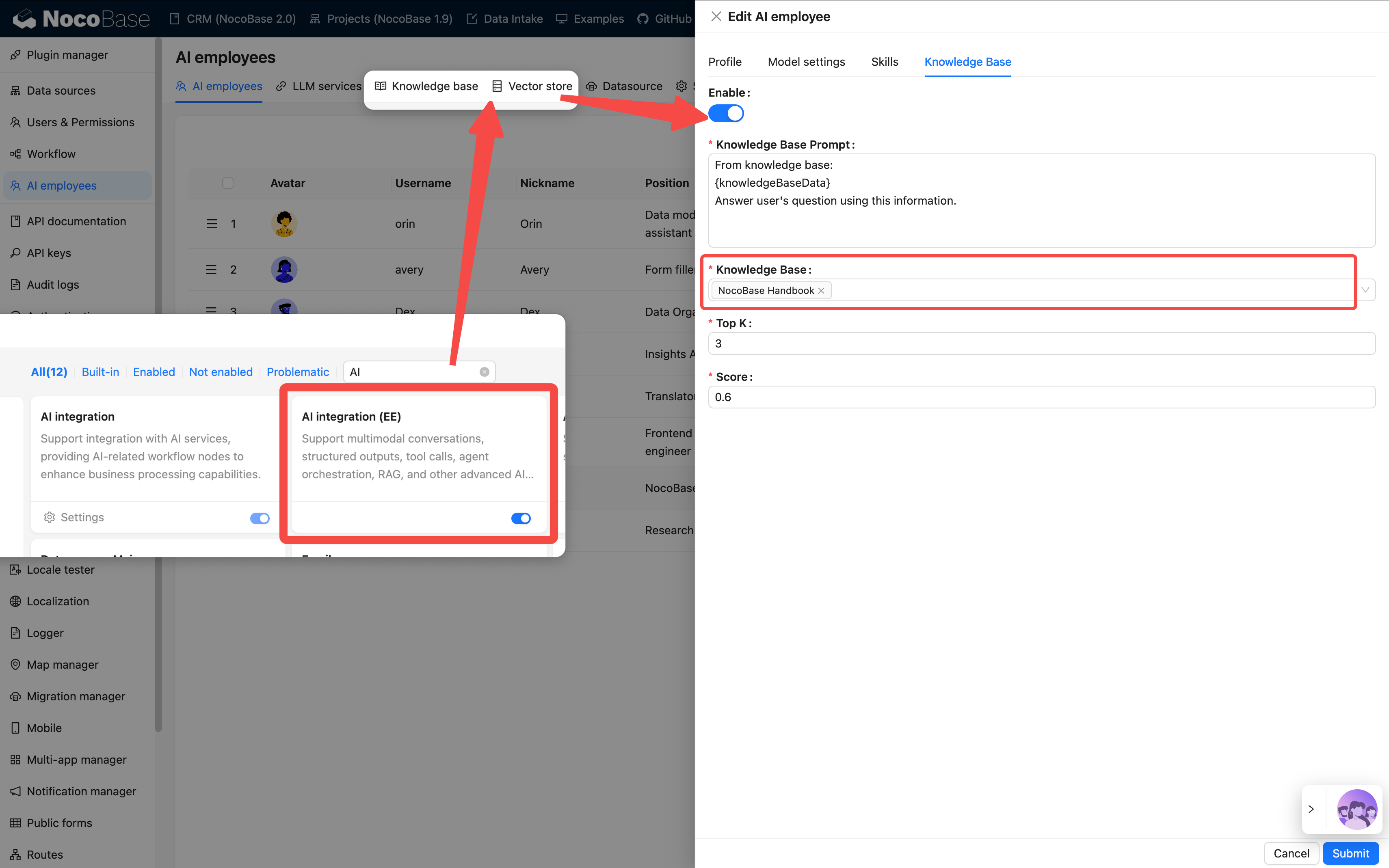
適用シーン:
- AI に企業知識を理解させる
- ドキュメントの Q&A と検索をサポートする
- ドメイン特化型アシスタントをトレーニングする
第 5 ステップ:効果の検証
完了すると、ページ右下に新しい従業員のアバターが表示されます。
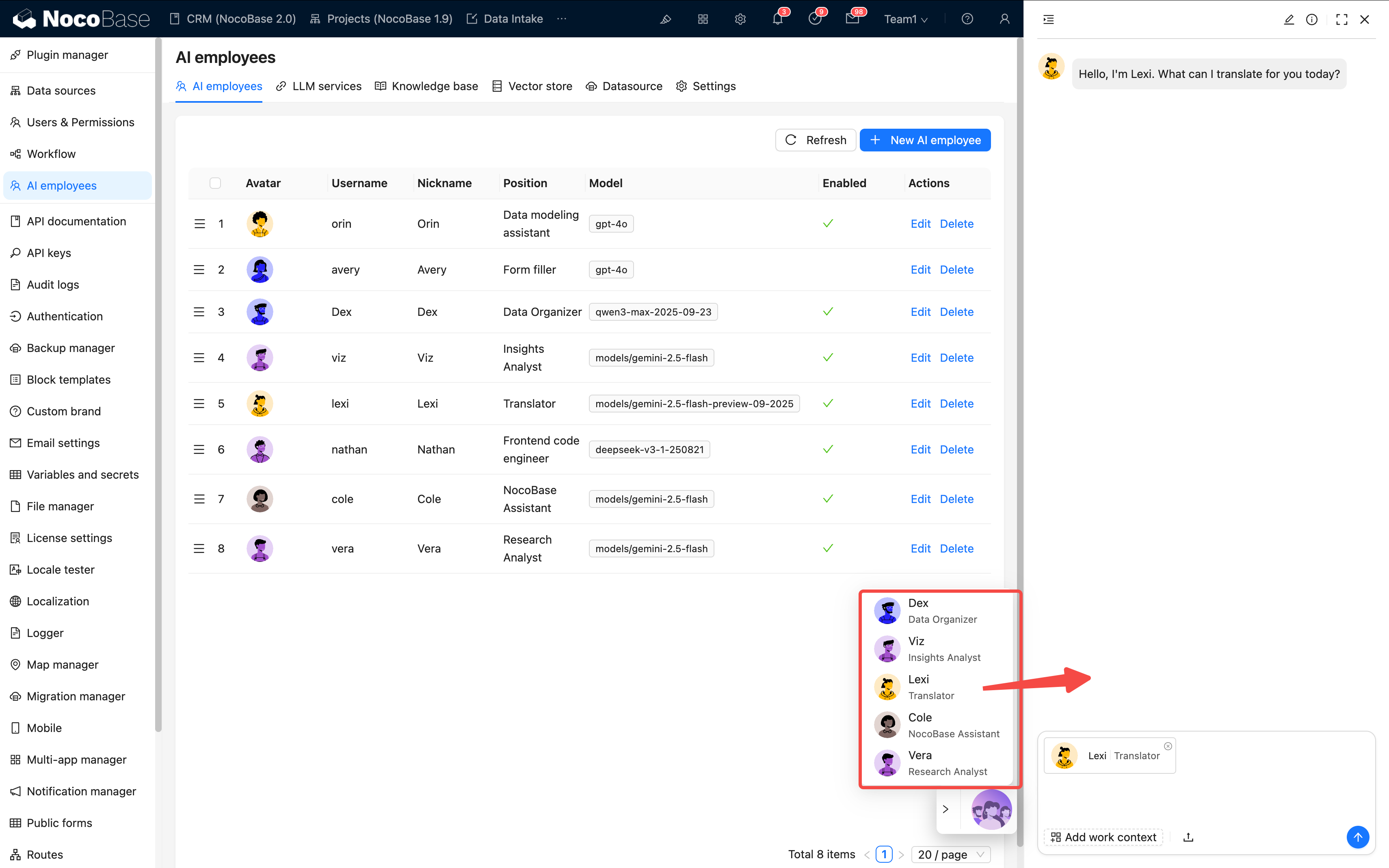
各項目を確認してください:
- ✅ アイコンが正常に表示されているか
- ✅ 基礎的な会話ができるか
- ✅ スキルが正しく呼び出せるか
すべてパスすれば、設定成功です 🎉
三、タスク設定:AI を実際に稼働させる
前段階で完了したのは「従業員の作成」です。 次は彼らを「仕事に就かせる」必要があります。
AI タスクは、特定のページやブロックにおける従業員の振る舞いを定義します。
💡 詳細な説明は以下を参照してください:タスク
1. ページレベルのタスク
「このページのデータを分析する」など、ページ全体の範囲に適用されます。
設定エントリ:
ページ設定 → AI 従業員 → タスクを追加
| フィールド | 説明 | 例 |
|---|---|---|
| タイトル | タスク名 | フェーズ転換分析 |
| 背景 | 現在のページのコンテキスト | リードリストページ |
| デフォルトメッセージ | プリセット会話 | 「今月の傾向を分析してください」 |
| デフォルトブロック | データテーブルの自動関連付け | leads テーブル |
| スキル | 利用可能なツール | データクエリ、グラフ生成 |
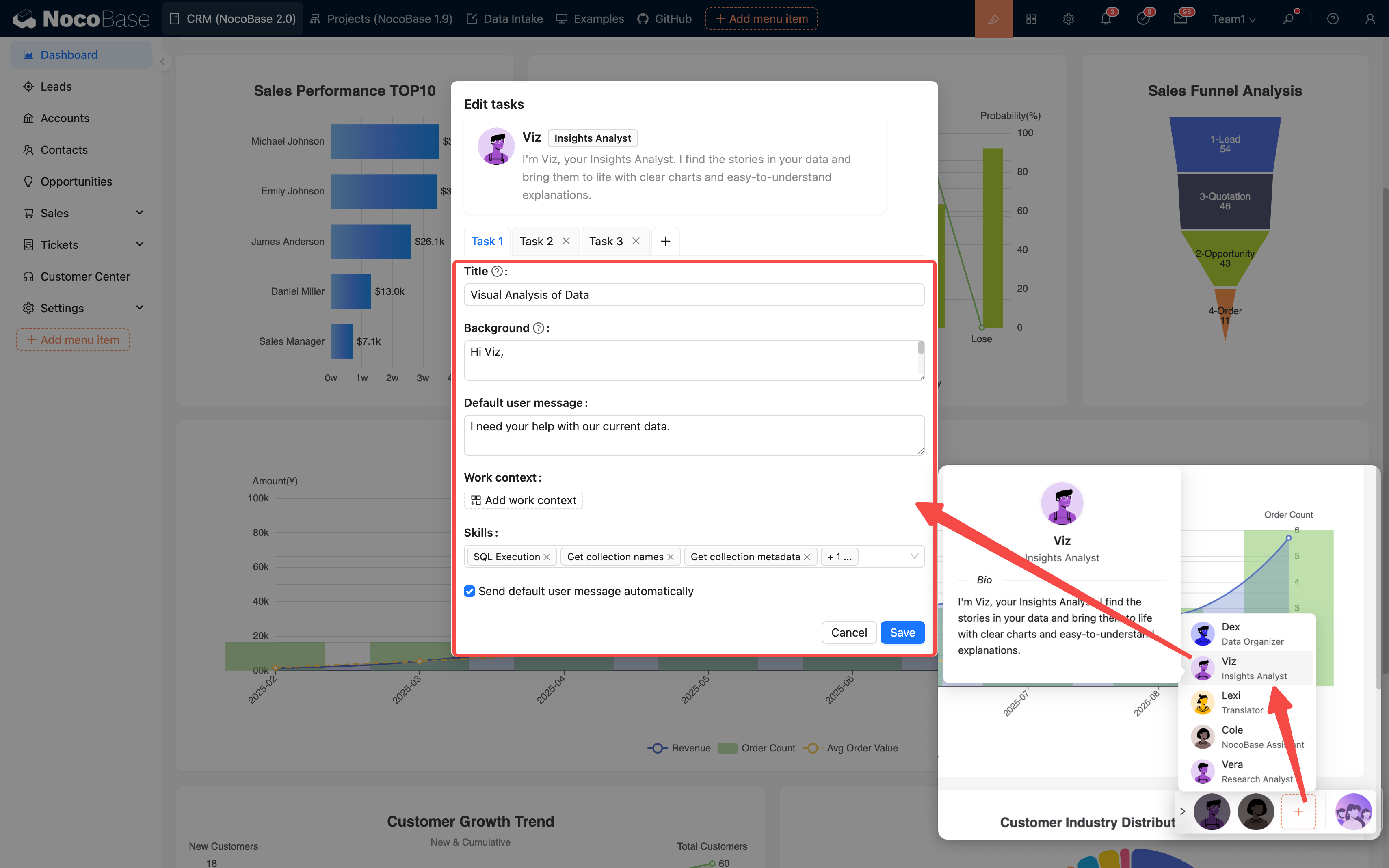
マルチタスクのサポート: 同じ AI 従業員に複数のタスクを設定でき、ユーザーは選択肢の形式で選ぶことができます:
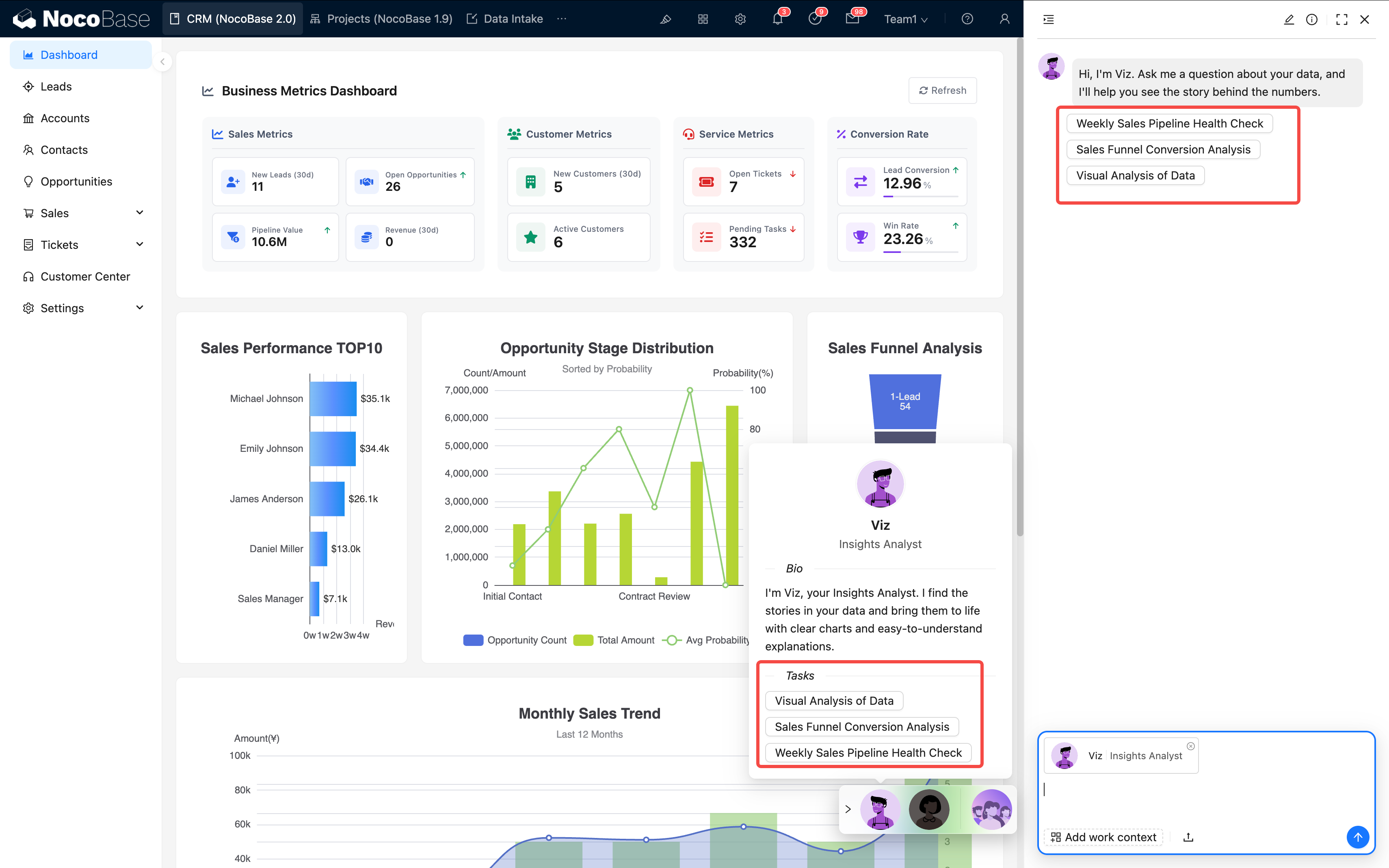
アドバイス:
- 一つのタスクは一つの目標に集中させる
- 名前は明確で分かりやすくする
- タスクの数は 5〜7 個以内に抑える
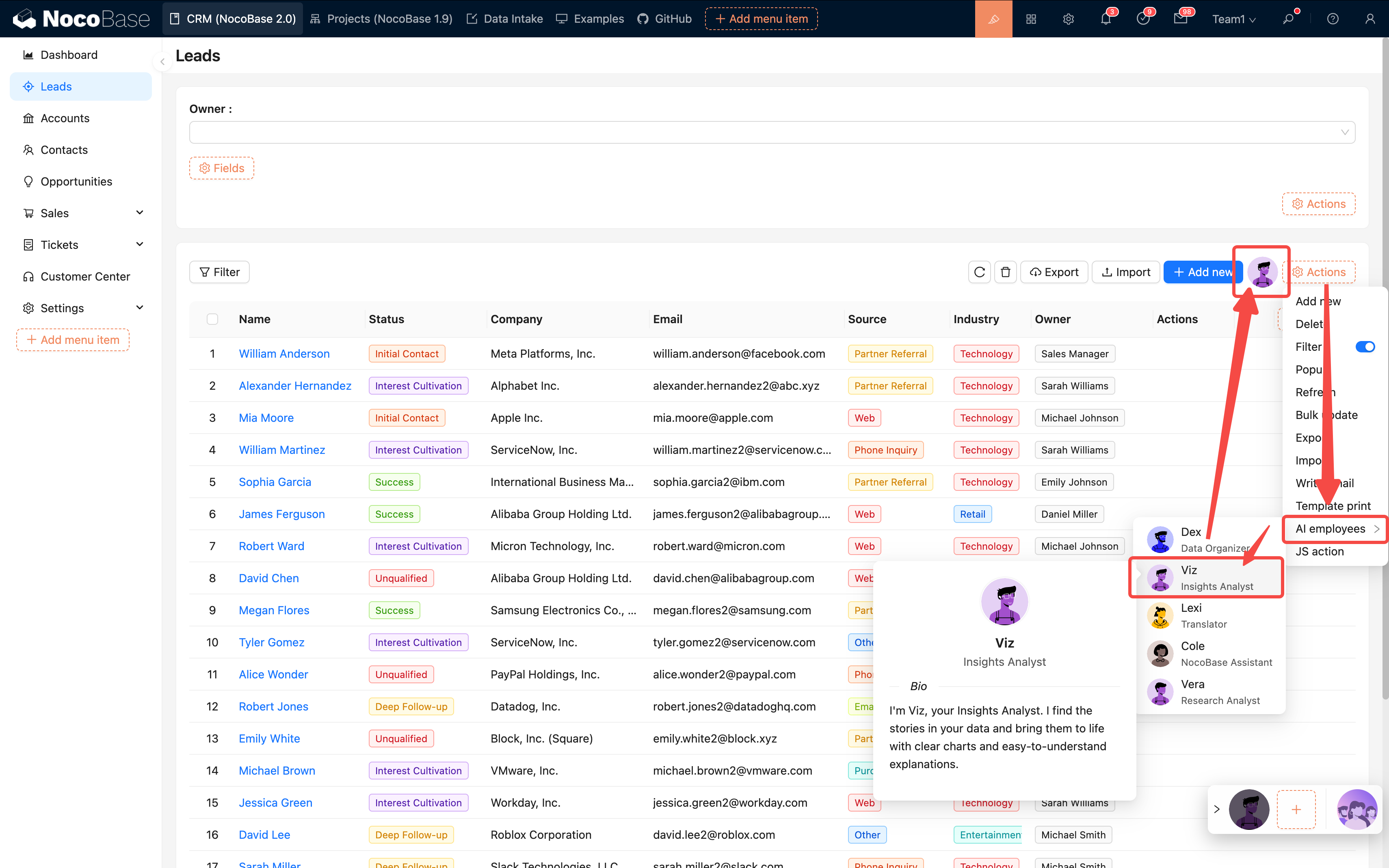
2. ブロックレベルのタスク
「現在のフォームを翻訳する」など、特定のブロックを操作するのに適しています。
設定方法:
- ブロック操作設定を開く
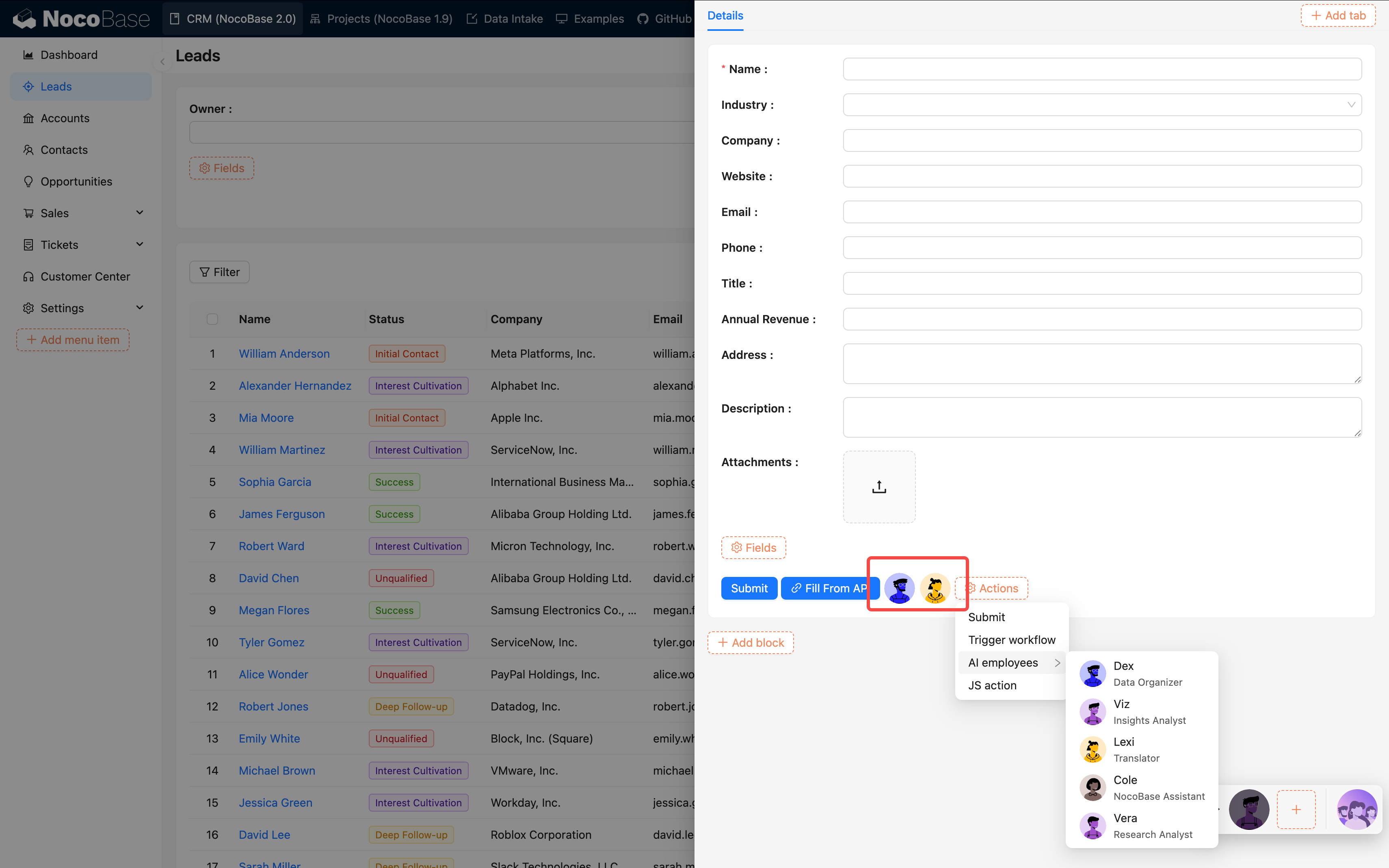
- 「AI 従業員」を追加する
- 対象の従業員をバインドする
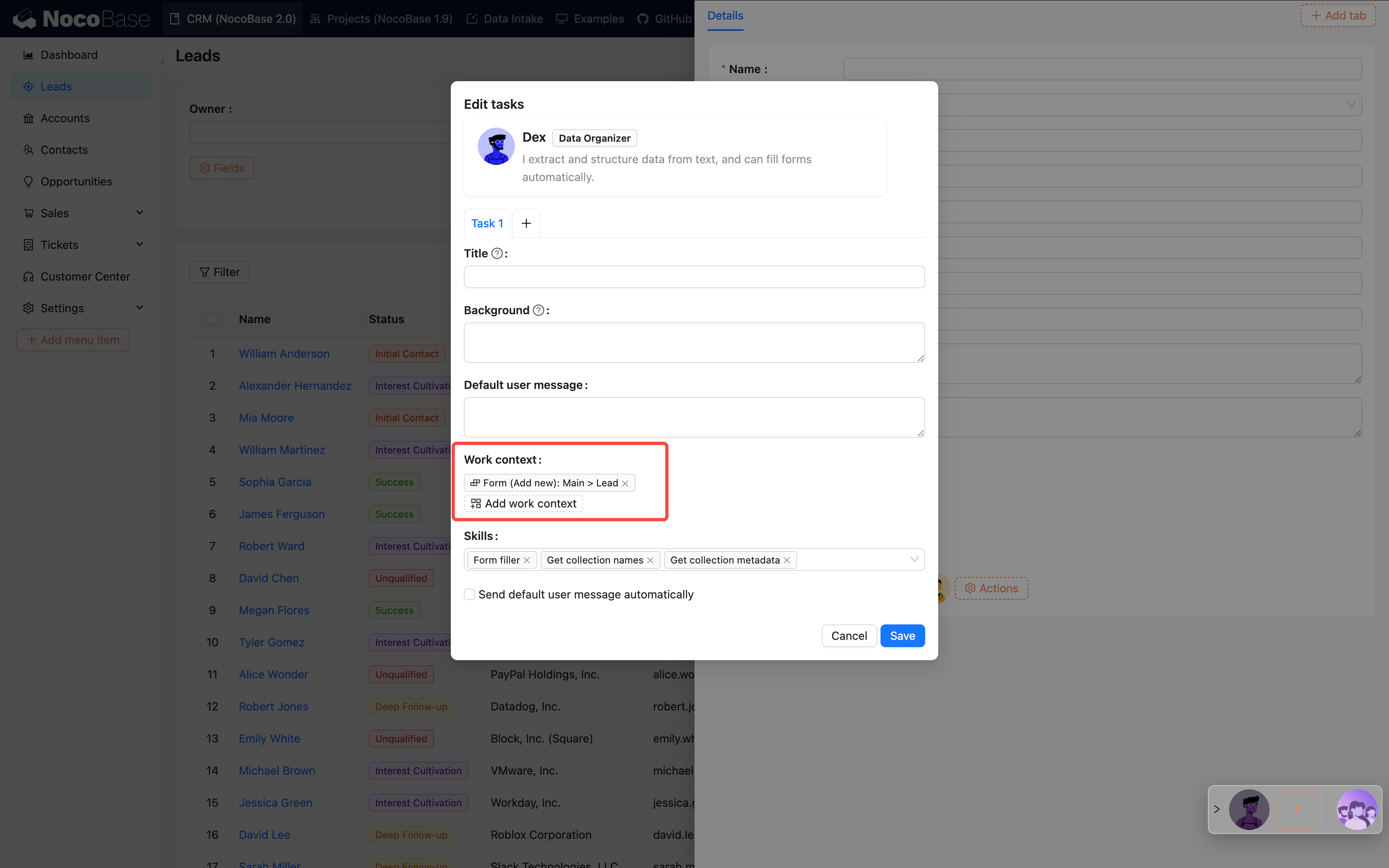
| 比較項目 | ページレベル | ブロックレベル |
|---|---|---|
| データ範囲 | ページ全体 | 現在のブロック |
| 粒度 | グローバル分析 | 詳細処理 |
| 典型的な用途 | 傾向分析 | フォーム翻訳、フィールド抽出 |
四、ベストプラクティス
1. 設定のアドバイス
| 項目 | 推奨事項 | 理由 |
|---|---|---|
| スキル数 | 3–5 個 | 高精度、高速レスポンス |
| 権限モード(Ask / Allow) | データ変更は Ask を推奨 | 誤操作の防止 |
| プロンプトの長さ | 500–1000 文字 | 速度と品質の両立 |
| タスク目標 | 単一かつ明確 | AI の迷いを避ける |
| ワークフロー | 複雑なタスクをカプセル化して使用 | 成功率が高まる |
2. 実践のアドバイス
小さく始めて、段階的に最適化する:
- まず基礎的な従業員(例:Viz、Dex)を作成する
- 1〜2 個の核心スキルを有効にしてテストする
- タスクが正常に実行できることを確認する
- その後、徐々により多くのスキルとタスクを拡張する
継続的な最適化プロセス:
- 初版を動かす
- 使用フィードバックを収集する
- プロンプトとタスク設定を最適化する
- テストと改善を繰り返す
五、よくある質問
1. 設定段階
Q:保存に失敗した場合はどうすればよいですか? A:すべての必須項目、特にモデルサービスとプロンプトが入力されているか確認してください。
Q:どのモデルを選ぶべきですか?
- コード類 → Claude、GPT-4
- 分析類 → Claude、DeepSeek
- コスト重視 → Qwen、GLM
- 長文テキスト → Gemini、Claude
2. 使用段階
Q:AI の返信が遅すぎます。
- スキル数を減らす
- プロンプトを最適化する
- モデルサービスの遅延を確認する
- モデルの変更を検討する
Q:タスクの実行が不正確です。
- プロンプトが十分に明確でない
- スキルが多すぎて混乱している
- タスクを細分化し、例を追加する
Q:Ask / Allow はいつ選ぶべきですか?
- クエリ系のタスクは
Allowを使用できます - データ変更系のタスクは
Askを推奨します
Q:AI に特定のフォームを処理させるにはどうすればよいですか?
A:ページレベルの設定の場合は、手動でブロックを選択する必要があります。
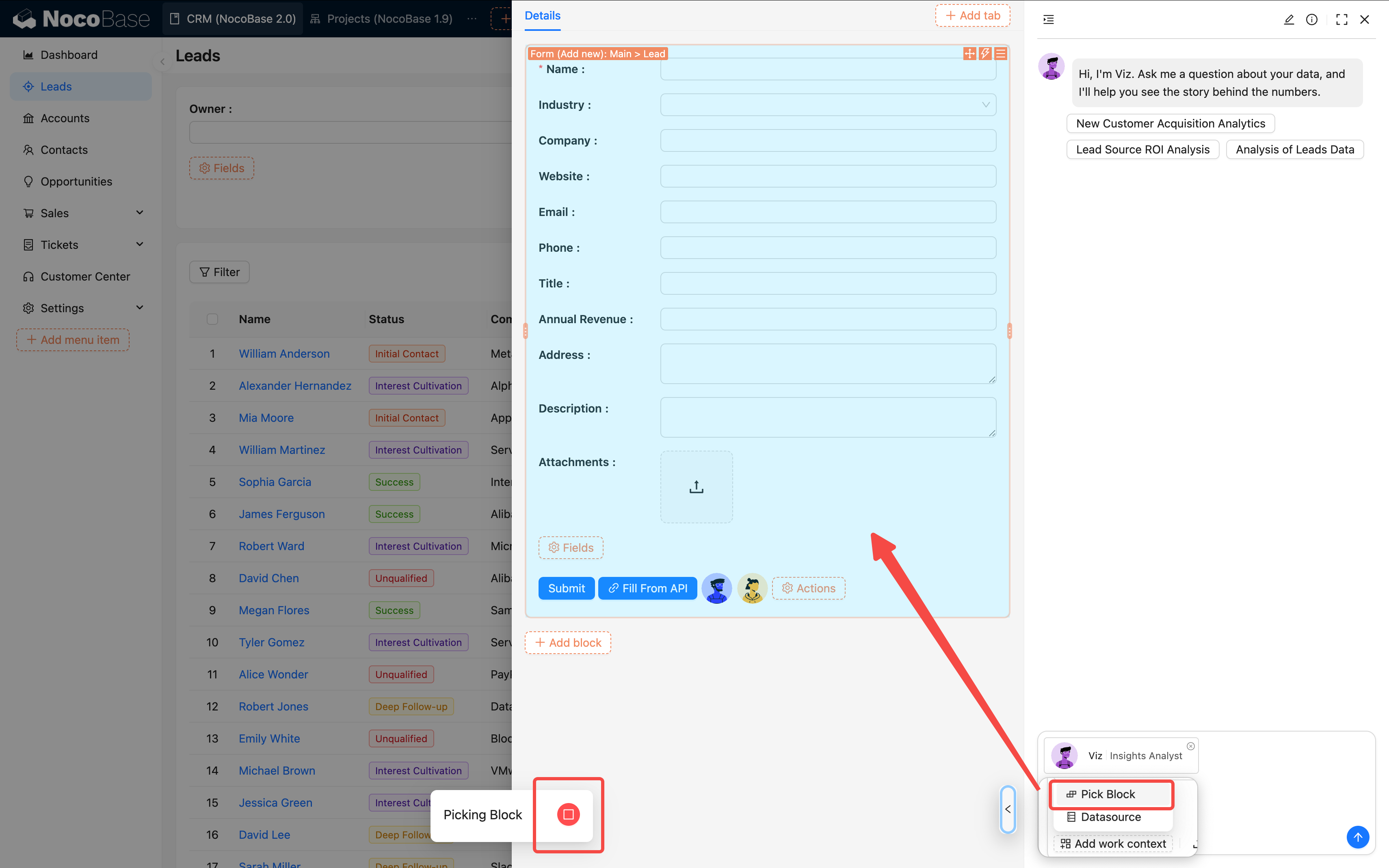
ブロックレベルのタスク設定の場合は、データコンテキストが自動的にバインドされます。
六、関連ドキュメント
AI 従業員をより強力にするために、以下のドキュメントを読み進めてください:
設定関連:
- プロンプトエンジニアリングガイド - 高品質なプロンプトを作成するためのテクニックとベストプラクティス
- LLM サービスの設定 - 大言語モデルサービスの詳細な設定説明
- AI 従業員の作成 - AI 従業員の作成と基礎設定
- AI 従業員との連携 - AI 従業員と効果的に会話する方法
高度な機能:
- スキル - 各種スキルの設定と使用について深く理解する
- タスク - タスク設定の高度なテクニック
- ブロックの選択 - AI 従業員にデータブロックを指定する方法
- データソース - 対応するプラグインのデータソース設定ドキュメントを参照してください
- ネット検索 - AI 従業員のネット検索機能を設定する
知識ベースと RAG:
- AI 知識ベースの概要 - 知識ベース機能の紹介
- ベクトルデータベース - ベクトルデータベースの設定
- 知識ベース - 知識ベースの作成と管理方法
- RAG 検索拡張生成 - RAG 技術の応用
ワークフロー統合:
- LLM ノード - テキストチャット - ワークフローでテキストチャットを使用する
- LLM ノード - マルチモーダルチャット - 画像やファイルなどのマルチモーダル入力を処理する
- LLM ノード - 構造化出力 - 構造化された AI 応答を取得する
結び
AI 従業員の設定で最も重要なのは、**「まず動かしてみて、それから最適化する」**ことです。 まずは最初の従業員を成功裏に稼働させ、その後、段階的に拡張と微調整を行ってください。
トラブルシューティングは以下の順序で行うことができます:
- モデルサービスが接続されているか
- スキル数が多すぎないか
- プロンプトが明確か
- タスク目標がはっきりしているか
順を追って進めれば、真に効率的な AI チームを構築できるはずです。